



Perquè la màquina parli de la pròpia veu

Inma Hernaez Rioja és professora catedràtica de l'Escola Superior d'Enginyeria de Bilbao i fundadora del grup de recerca Aholkularitza. El grup va néixer en 1995 dins de la UPV/EHU i treballa la parla automàtica en basca. Ha estat un treball bastant silenciós fins ara. De fet, el ressò i l'acolliment que ha tingut l'últim projecte, | MyTTS, ha estat tan gran que van haver de suspendre temporalment el sistema.
Darrere d'aquest èxit es troba el treball de molts anys i en el punt de partida una vivència personal: La germana d'Hernaez va perdre la veu per una operació. I la seva trajectòria ha estat impulsada per ajudar-lo a comunicar-se amb ell i amb uns altres. “La meva germana ha estat el primer usuari dels nostres desenvolupaments. En una ocasió van homenatjar un amic íntim de la seva germana, qui va donar una petita xerrada gràcies a l'aplicació. Donar-me aquesta oportunitat m'ha donat molta força per a avançar en la recerca”.
Des dels seus inicis fins a l'actualitat, el desenvolupament ha estat notable. Fa 20 anys, per a aconseguir una bona qualitat en les tècniques de síntesis de veu, es necessitaven moltes hores d'enregistrament d'una persona. Per exemple, per a aconseguir la veu que té Siri, Hernaez ha dit que trigarien unes 30 hores. A més, havia de gravar-se en un estudi amb una qualitat molt bona.

La tècnica es basava en el procediment “tallar i pegar”. No es tallaven paraules o frases, sinó petites unitats: difonemas, trifonemas, vocals o consonants amb el context... Posteriorment, depenent del context, l'algorisme determinava quina unitat triar de la base de dades. “Es deia síntesi basada en corpus. Era molt car”, ha precisat.
Utilitat i qualitat
El següent pas es remunta a l'any 2002 gràcies a la síntesi estadístic-paramètrica. Aquesta tècnica consisteix, en primer lloc, en la parametrització dels senyals de veu i, posteriorment, en la interconnexió d'aquests paràmetres mitjançant un tractament estadístic. Explica que la qualitat no és tan bona com la del sistema anterior, però amb molt menys enregistrament s'aconsegueix un resultat acceptable. A més, el seu caràcter estadístic li confereix una gran flexibilitat en poder adaptar el model estadístic a qualsevol mostra.
Així explica el procés. “Tenim veu mitjana. Aquesta veu no és de ningú, està feta amb moltes veus i ponents. No són qualsevol ponent, solen ser ponents professionals, la veu mitjana s'obté a partir del seu enregistrament. Després, aquesta veu es pot adaptar a la veu de qualsevol usuari, per al que n'hi ha prou amb tenir una mostra de cent frases”.
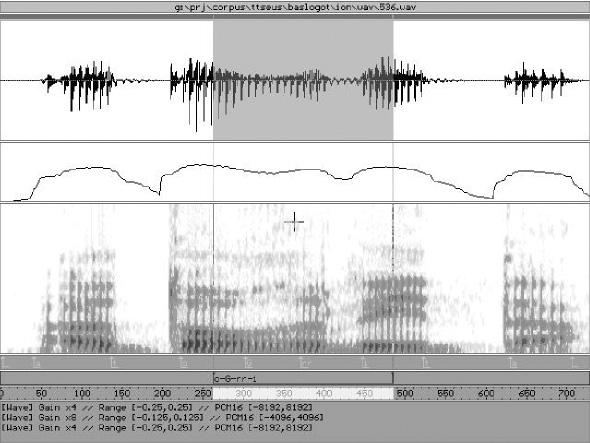
En aquestes cent frases hi ha totes les combinacions sonores i l'enregistrament dur mig hora. L'avanç és evident, ja que facilita enormement que qualsevol persona tingui una veu sintètica adaptada a la seva veu. “De fet, si gravem més frases s'aconsegueix una millor qualitat, però no podem demanar més esforç que això”, diu Hernaez.
Té altres limitacions. Per exemple, no és capaç d'expressar emocions: “Gravant un corpus amb emocions es pot aconseguir, però en aquest projecte les frases són neutres i no fem l'anàlisi del text per a buscar emocions. No obstant això, es pot posar en el text, però no el fem”.
Però els avantatges són evidents: el sintetitzador no agafa memòria, l'han implementat fàcilment en Android, funciona en temps real en el mòbil... Tot això permet a qualsevol persona utilitzar-ho en el seu dia a dia. I aquest era l'objectiu inicial.
De fet, Hernaez ha reconegut que existeixen en l'actualitat sistemes que ofereixen una major qualitat, especialment basats en xarxes neuronals: “La tecnologia actual de síntesi és molt bona. Jo t'ensenyaria algunes frases i tu no series capaç de distingir si és sintètic o natural. Però no podríem entrar en Android o utilitzar-ho en temps real”.
Del laboratori a l'usuari
I aquesta és la sagnia: en el dia a dia les persones que necessiten veu sintètica per a comunicar-se han d'utilitzar els sistemes que hi ha i són molt limitats. Així, en molts casos, les dones han d'utilitzar la veu humana; o els parlants de llengües minoritzades, el llenguatge hegemònic; o els nens, el de Siri. L'objectiu d'Hobe ha estat reduir la distància entre la veu de l'usuari i la que ofereix el sintetitzador.
S'ha procurat que el sistema desenvolupat sigui el més còmode i senzill possible per a l'usuari. El funcionament és el següent: “L'usuari grava primer aquestes cent frases, en basca o en castellà, i es crea automàticament una aplicació amb la seva veu sintètica. A continuació ho rebrà per correu electrònic i només haurà de fer clic per a baixar-ho al seu mòbil Android. La veu es grava com a veu del sistema, per la qual cosa pot utilitzar-la no sols en la nostra aplicació de comunicació, sinó també en altres aplicacions com llegir llibres en molts e-reader o en Adobe. I es poden comunicar en temps real”.
Per part seva, les persones amb mobilitat molt limitada utilitzen tauleta i palanca o lector d'iris. En aquest cas l'integren en Windows.

Entre els usuaris es troben les persones amb esclerosi lateral amiotròfica. En principi, el projecte pretén ajudar a qualsevol persona que hagi perdut la seva veu, però quan la pèrdua és sobtada (per exemple, a causa d'un ictus), és difícil aconseguir la seva veu sintètica. Per part seva, les persones amb esclerosi lateral amiotròfica perden progressivament la seva capacitat de moviment. Per tant, des que reben el diagnòstic tenen temps per a realitzar l'enregistrament i crear la seva pròpia veu sintètica.
En els últims tres o quatre anys, juntament amb Biocruces, han treballat amb pacients als quals calia fer laringectomía. ”Els laringectomizados poden parlar amb la veu esofàgica, però amb aquesta col·laboració els metges informaven els pacients per a realitzar l'enregistrament abans de la intervenció. Així que després tenien l'aplicació, perquè en les primeres setmanes no poden parlar”, explica Hernaez. Diu que aquesta col·laboració ha donat un gran impuls al projecte.
Ara continuen treballant per a millorar la qualitat (tenen un nou algorisme) i per a escurçar el camí que es fa des del laboratori a l'usuari. També s'està fent un esforç perquè la veu del nen estigui disponible, fins i tot en altres llengües, com el català. Objectiu final: que totes les persones que ho necessitin tinguin la possibilitat de comunicar-se a través de la veu sintètica de la manera més personalitzada, natural i senzilla possible.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







