



Pour que la machine parle de sa propre voix

Inma Hernaez Rioja est professeur titulaire de l'École supérieure d'ingénierie de Bilbao et fondatrice du groupe de recherche Aholkularitza. Le groupe est né en 1995 dans l'UPV/EHU et travaille la parole automatique en basque. Il a été un travail assez silencieux jusqu'à présent. En fait, l'écho et l'accueil du dernier projet, MyTTS, ont été si importants qu'ils ont dû temporairement suspendre le système.
Derrière ce succès se trouve le travail de plusieurs années et au point de départ une expérience personnelle: La sœur de Hernaez a perdu la voix pour une opération. Et sa trajectoire a été poussée par l'aider à communiquer avec lui et avec d'autres. « Ma sœur a été le premier utilisateur de nos développements. Une fois, ils ont rendu hommage à un ami intime de leur sœur, qui a donné une petite conversation grâce à l'application. Me donner cette opportunité m’a donné beaucoup de force pour avancer dans la recherche.»
De ses débuts à nos jours, le développement a été remarquable. Il y a 20 ans, pour obtenir une bonne qualité dans les techniques de synthèse vocale, il fallait beaucoup d'heures d'enregistrement d'une personne. Par exemple, pour obtenir la voix de Siri, Hernaez a dit qu'il faudrait environ 30 heures. En outre, il devait être enregistré dans un studio avec une très bonne qualité.

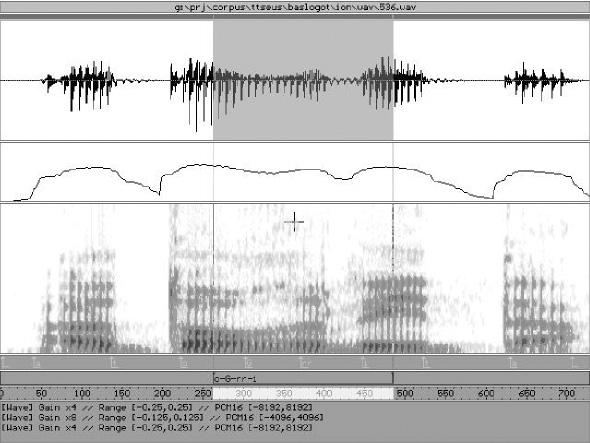
La technique était basée sur la procédure “couper et coller”. On ne coupait pas de mots ou de phrases, mais de petites unités: diphonèmes, triphonèmes, voyelles ou consonnes avec le contexte... Par la suite, selon le contexte, l'algorithme déterminait quel lecteur choisir de la base de données. « On appelait synthèse basée sur le corpus. C’était très cher», a-t-il précisé.
Utilité et qualité
L'étape suivante remonte à 2002 grâce à la synthèse statistico-paramétrique. Cette technique consiste en premier lieu à paramétrer les signaux vocaux, puis à interconnecter ces paramètres par un traitement statistique. Il explique que la qualité n'est pas aussi bonne que celle du système précédent, mais avec beaucoup moins d'enregistrement on obtient un résultat acceptable. En outre, son caractère statistique lui confère une grande flexibilité en pouvant adapter le modèle statistique à n'importe quel échantillon.
Cela explique le processus. « Nous avons une voix moyenne. Cette voix n'est pas de personne, elle est faite avec beaucoup de voix et de conférenciers. Ils ne sont pas un orateur, ils sont généralement des conférenciers professionnels, la voix moyenne est obtenue à partir de leur enregistrement. Ensuite, cette voix peut être adaptée à la voix de n'importe quel utilisateur, donc il suffit d'avoir un échantillon de cent phrases. »
Dans ces cent phrases il y a toutes les combinaisons sonores et l'enregistrement dure une demi-heure. L'avancement est évident, car il facilite grandement que toute personne ait une voix synthétique adaptée à sa voix. “En fait, si nous enregistrons plus de phrases, nous obtenons une meilleure qualité, mais nous ne pouvons pas demander plus d'effort que cela”, dit Hernaez.
Il a d'autres limitations. Par exemple, il n'est pas capable d'exprimer des émotions: « Enregistrer un corpus avec des émotions peut être réalisé, mais dans ce projet les phrases sont neutres et nous ne faisons pas l’analyse du texte pour rechercher des émotions. Cependant, il peut être mis dans le texte, mais nous ne le faisons pas”.
Mais les avantages sont évidents: le synthétiseur ne prend pas de mémoire, l'ont facilement mis en œuvre sur Android, il fonctionne en temps réel sur mobile... Tout cela permet à quiconque de l'utiliser dans sa vie quotidienne. Et c'était le but initial.
En fait, Hernaez a reconnu qu'il existe actuellement des systèmes qui offrent une meilleure qualité, notamment basés sur des réseaux neuronaux: « La technologie de synthèse actuelle est très bonne. Je vous enseignerais quelques phrases et vous ne seriez pas en mesure de distinguer si elle est synthétique ou naturelle. Mais nous ne pourrions pas entrer dans Android ou l'utiliser en temps réel”.
Du laboratoire à l'utilisateur
Et c'est la sangria: dans la vie quotidienne, les gens qui ont besoin de voix synthétique pour communiquer doivent utiliser les systèmes là-bas et sont très limités. Ainsi, dans de nombreux cas, les femmes doivent utiliser la voix humaine; ou les locuteurs de langues minorifiées, le langage hégémonique; ou les enfants, celui de Siri. L'objectif de Hobe était de réduire la distance entre la voix de l'utilisateur et celle offerte par le synthétiseur.
Il a été fait en sorte que le système développé soit aussi confortable et simple que possible pour l'utilisateur. Le fonctionnement est le suivant: « L’utilisateur enregistre d’abord ces cent phrases, en basque ou en espagnol, et une application est automatiquement créée avec sa voix synthétique. Ensuite, vous le recevrez par e-mail et il vous suffit de cliquer pour le télécharger sur votre mobile Android. La voix est enregistrée comme une voix système, de sorte que vous pouvez l'utiliser non seulement dans notre application de communication, mais aussi dans d'autres applications comme la lecture de livres sur de nombreux e-reader ou Adobe. Et ils peuvent communiquer en temps réel ».
Pour leur part, les personnes à mobilité réduite utilisent tablette et levier ou lecteur iris. Dans ce cas, ils l'intègrent dans Windows.

Parmi les utilisateurs se trouvent les personnes atteintes de sclérose latérale amyotrophique. En principe, le projet vise à aider toute personne qui a perdu sa voix, mais quand la perte est soudaine (par exemple en raison d'un ictus), il est difficile d'obtenir sa voix synthétique. De leur côté, les personnes atteintes de sclérose latérale amyotrophique perdent progressivement leur capacité de mouvement. Par conséquent, depuis qu'ils reçoivent le diagnostic, ils ont le temps de réaliser l'enregistrement et de créer leur propre voix synthétique.
Au cours des trois ou quatre dernières années, avec Biocruces, ils ont travaillé avec des patients qui devaient faire la laryngectomie. « Les laringectomisés peuvent parler à la voix oesophagienne, mais avec cette collaboration les médecins informaient les patients pour effectuer l’enregistrement avant l’intervention. Ils avaient donc ensuite l’application, parce que dans les premières semaines ils ne peuvent pas parler”, explique Hernaez. Il dit que cette collaboration a donné une grande impulsion au projet.
Ils travaillent maintenant à améliorer la qualité (ils ont un nouvel algorithme) et à raccourcir le chemin qui est fait du laboratoire à l'utilisateur. Un effort est également fait pour rendre la voix de l'enfant disponible, même dans d'autres langues, comme le catalan. Objectif final: que toutes les personnes qui en ont besoin aient la possibilité de communiquer à travers la voix synthétique de la manière la plus personnalisée, naturelle et simple possible.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







