



Résoudre les voies obscures de l'intuition

Autour de l'intuition, de nombreux penseurs ont travaillé tout au long de l'histoire, comme Descartes, Kant ou Husserl. Aujourd'hui, cependant, l'intuition est un concept qui étudie les psychologues et les neurologues, en utilisant pour cela les outils et les voies de la science moderne. Nous n'apportons pas ici leurs travaux profonds. Il suffit de savoir que, selon les dernières théories, l'intuition est la connaissance générée par des voies non rationnelles. Par conséquent, ce type de connaissance ne peut ni expliquer ni parler [1]. Il donne de l'importance à ce concept, qui réapparaîtra.
Tout au long de cet article, nous verrons si l'intuition est une caractéristique exclusive des êtres humains. Pour cela, nous allons d'abord analyser et comprendre les machines qui jouent aux échecs. Voici une des grandes réalisations scientifiques de 2016 pour le magazine Science [2]: Alpha, l'intelligence artificielle qui a conquis le jeu chinois.
Échecs et Machine Deep Blue

Dans la culture occidentale, les échecs ont été le point culminant des jeux stratégiques de table. Essayons d'analyser ce jeu à travers les nombres. Dans les échecs chaque joueur a au début 16 pièces de 6 types. Les pièces de chaque type peuvent être déplacées de différentes façons. Par conséquent, dans toute situation du jeu, un joueur peut effectuer 35 mouvements différents.
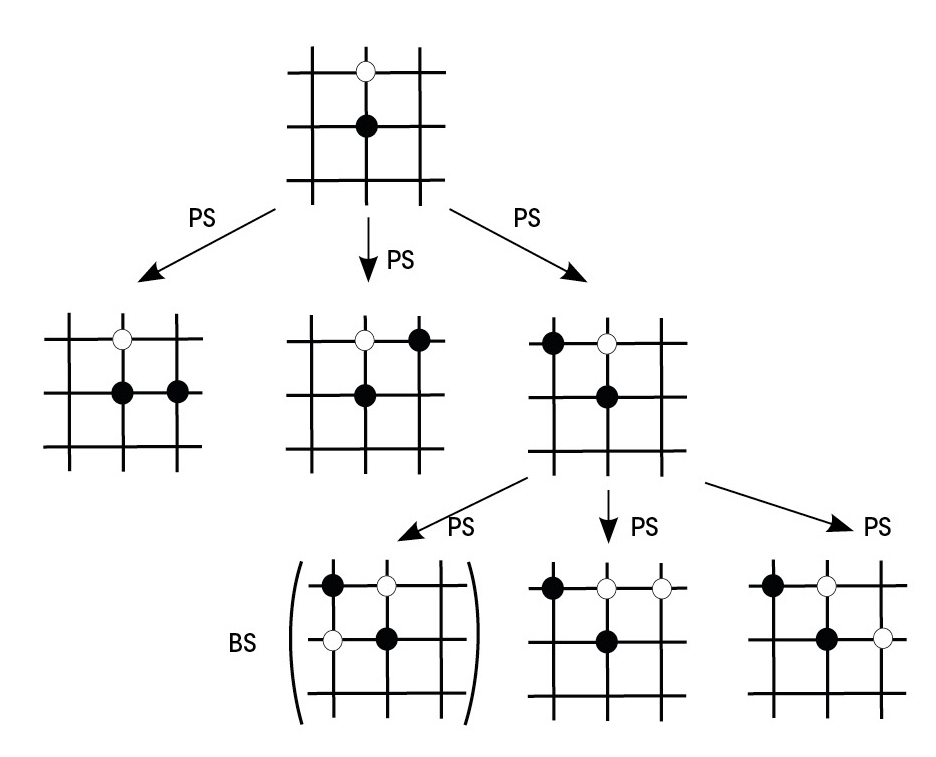
Les échecs et ce type de jeux peuvent apparaître en utilisant des structures de type arbre. La racine de l'arbre indique l'état initial du parti, chaque pièce étant dans sa position initiale. Supposons que depuis la situation initiale nous déplaçons un pion. Cette nouvelle situation serait en première ligne de notre arbre, avec tous les mouvements possibles de toutes les autres pièces. De chaque nouvelle situation sortiront autant de nouvelles branches que des mouvements possibles et ainsi de suite (Figure 1).
On considère que le nombre de jeux qui peuvent être créés aux échecs, c'est-à-dire le nombre de nœuds de l'arbre, est d'environ 10120. Pour voir plus clairement l'ampleur de ce nombre, imaginez que, selon les meilleurs calculs, dans notre univers il y a 1080 atomes!
La machine qui a pu pour la première fois battre un grand maître d'échecs était Deep Blue en 1997 [3]. Ce supercalculateur programmé par IBM utilisait l'arbre d'échecs pour prendre des décisions. Incapable de conserver tout l'arbre, à partir du noeud représentant un état de jeu, la machine analysait les six lignes de profondeur suivantes. J'évaluais les noeuds qu'il y avait dans ces profondeurs, voyant ce qui était le plus mauvais noeud pour lui et ce qui le meilleur. Après cette évaluation, je prenais le mouvement nécessaire pour éviter le pire noeud.
La clé de cette stratégie de jeu est la capacité d'évaluation des nœuds. Pour ce faire, IBM a travaillé avec de grands joueurs d'échecs pour obtenir des critères programmables avec leurs connaissances. Ces critères sont appelés heuristiques. IBM a fait un grand travail pour définir et programmer ces heuristiques et a fini par vaincre Gary Kasparov lui-même.
jeu chinois Go
Les règles du jeu go sont plus simples que les échecs, mais le jeu est beaucoup plus complexe. On calcule qu'il y a 10761 jeux possibles au sommet ! Mais ce n'est pas le pire: dans les échecs, il est possible de programmer des heuristiques, mais il est presque impossible de bien définir les critères qui fonctionnent correctement et de les convertir en programmes. En général, les experts sont d'accord pour savoir si un mouvement a été bon ou mauvais, mais ils ne peuvent pas expliquer pourquoi ils pensent. Il semble que l'intuition est la clé pour jouer. Et bien sûr, nous ne savons pas encore parler de l'intuition, la transformer en une formule mathématique ou l'écrire comme un programme.
C'est pourquoi la plupart des experts ont dit qu'il y a de nombreuses années, nous ne voyions aucune machine qui gagnerait les meilleurs joueurs du Go dans les années vingt. Car nous l'avons vu. En mars 2016, Deep Mind [4] a remporté l'un des grands champions du monde, le Coréen Lee Sedol, avec la machine Alpha.
Alpha Go et le pouvoir d'apprentissage
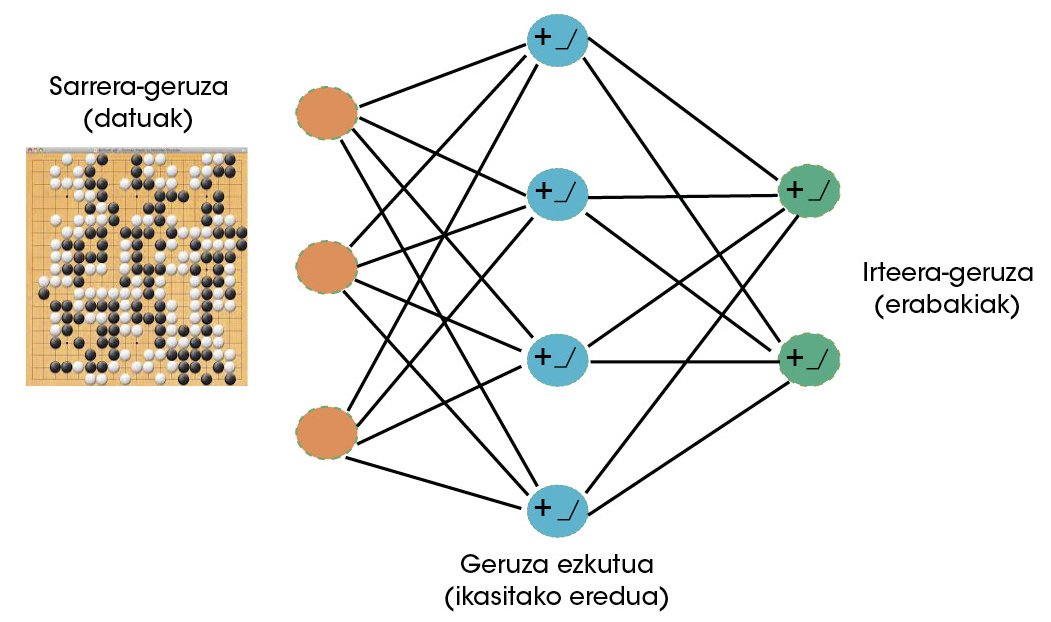
Les scientifiques de Deep Mind ont clairement vu que le goa pouvait être un jeu très approprié pour les machines capables d'apprendre. Par conséquent, les réseaux neuronaux ont commencé à être utilisés pour apprendre à jouer à l'avenir [5]. Les réseaux neuronaux sont actuellement les algorithmes d'apprentissage les plus réussis [6]. Comme les neurones cérébraux, les neurones artificiels reçoivent une série de signaux (données) qui, comme appris, sont activés ou non. Tout au long du processus d'apprentissage, le réseau neuronal définit les données devant lesquelles il doit être activé et l'intensité de ces activations. Par l'interconnexion de neurones artificiels, la formation de couches, ces réseaux peuvent apprendre des comportements très complexes (figure 2).
Alpha Go a deux réseaux neuronaux importants: d'une part, nous avons un réseau de politiques et d'autre part un réseau de valeurs. Le but du réseau politique est de deviner ce qui sera le meilleur mouvement suivant avec une situation de jeu. Pour cela, deux stratégies d'apprentissage sont combinées. Au début, 30 millions de coups humains ont été montrés au réseau avec un apprentissage supervisé. C'est-à-dire, pour une situation de jeu qui voyait le réseau, on lui apprenait quel était le prochain mouvement. Il a appris à généraliser de ces exemples. Une fois traités tous les mouvements et achevés les études, le réseau politique prévoyait les mouvements d'un être humain avec un taux d'invention de 57%.
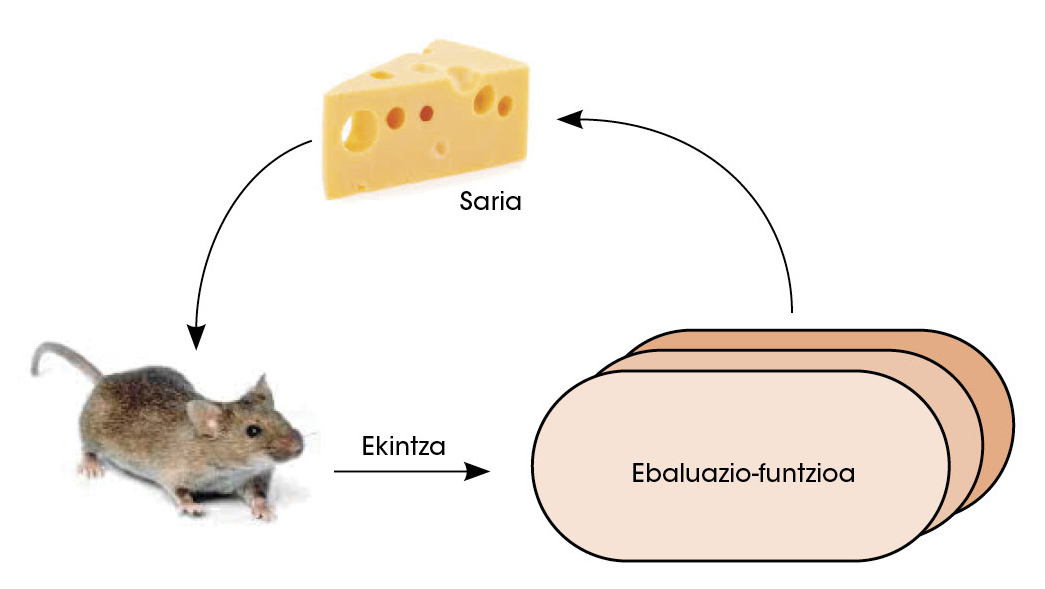
Dans une deuxième phase, le réseau politique se confronte. Ainsi, avec l'apprentissage par renfort, le réseau a amélioré la capacité de décider quel était le meilleur mouvement suivant. Dans ce type d'études, le réseau est libre de prendre des décisions. Si, à la suite de ces décisions, vous gagnez, vous serez attribué le prix. Mais si vous perdez vous êtes puni. Pour maximiser le nombre de prix, le réseau apprend à prendre des décisions toujours meilleures (figure 3).
Le réseau de valeurs a un autre objectif. Votre mission est d'évaluer la probabilité de gagner avec une situation de jeu. Pour former ce réseau, des milliers de parties contestées par Alpha Go ont été utilisées contre lui-même. Après avoir vu tant de matchs, le réseau de valeurs a appris à calculer correctement la chance de gagner un joueur devant un scénario de jeu.
Comment combiner ces deux réseaux neuronaux pour jouer dans l'œil? Pour cela, nous devons réutiliser l'arbre du jeu. Alpha, à travers une situation de jeu, utilise le réseau politique pour prédire les prochains meilleurs mouvements. Simulez des parties pour ces mouvements jusqu'à une certaine profondeur. Les états de jeu finaux de ces parties passent au réseau de valeurs pour calculer la probabilité de gagner. Ainsi, Alpha Go maintient la branche de jeu qui donne le plus de chances au réseau de valeurs parmi les mouvements que le tissu politique considère mieux (figure 4). En outre, il faut tenir compte qu'avec plus de parties, le réseau politique et le réseau de valeurs deviennent meilleurs dans leur travail.
Deep Blue vs Alpha
Il est vrai que les deux machines prennent des décisions en recherchant l'arbre de jeu. Mais il y a une énorme différence quand il s'agit de les analyser. Dans le cas de Deep Blue, les experts ont programmé manuellement les critères pour évaluer les situations de jeu. Donc, Deep Blue ne pourrait pas jouer dans un jeu autre que les échecs. Et bien sûr, votre capacité de jeu sera toujours la même, tant qu'il n'y aura pas d'experts qui amélioreront les heuristiques.
Alpha Go utilise deux réseaux neuronaux pour évaluer les meilleurs mouvements et les situations de jeu. Ces réseaux n'ont pas été programmés manuellement. Ils obtiennent en apprenant leur capacité, ils ont donc deux avantages principaux:
1 Valable pour tout autre jeu de société.
2 Comme vous jouez plus, Alpha devient meilleur joueur.
Les modes de fonctionnement des deux machines sont un excellent exemple des deux grands paradigmes historiques du monde de l'intelligence artificielle: Intelligence rigide orientée vers la connaissance de Deep Blue et la capacité d'apprentissage d'Alpha Goren. De la programmation manuelle des machines à l'abandon de leur propre apprentissage. Aujourd'hui, nous avons vu assez clairement que la deuxième idée, celle d'apprendre, est beaucoup plus puissante avec des exemples comme Alpha Go.
Conclusions
L'intuition est une connaissance non rationnelle. Les experts qui jouent à Goa ont recours à l'intuition pour expliquer leurs décisions et analyses. Ils savent comment agir, mais ils ne sont pas capables de l'expliquer correctement. Ils ne peuvent pas dire pourquoi un mouvement est mieux qu'un autre.
Alpha Go a pu imiter la fonction de l'intuition en profitant de la capacité d'apprendre. Face à une situation de jeu, il décide intuitivement quel est le meilleur mouvement suivant, comme le fait un être humain. Vous décidez également intuitivement si une situation de jeu vous mènera à gagner. Et il semble que son intuition est au-dessus de l'être humain.
Le grand champion Lee Sedol a employé différentes stratégies pour conquérir Alpha. Dans un parti, intentionnellement, il se comportait mal parce qu'il ne savait pas quoi faire Alpha Go devant un homme qui agissait mal. Il a échoué. Il ne pouvait gagner qu'en match grâce à un mouvement que peu attendaient. Selon les ingénieurs, Alpha Go a prévu ce mouvement, mais lui a donné une probabilité très basse. Lee Sedol a surpris la machine avec ce mouvement. Mais une seule fois.
Le défi pour l'avenir est d'utiliser les réseaux neuronaux et les techniques d'apprentissage que Alpha utilise pour résoudre nos problèmes quotidiens. Les machines d'apprentissage peuvent nous aider dans l'industrie, les services, la médecine et même dans le développement de la science. L'intuition est l'une des clés dans tous ces domaines et il semble que nous savons déjà quoi faire pour que les machines obtiennent cette intuition.
Bibliographie Bibliographie
[1] Théories de l'intuition : https://es.wikipedia.org/wiki/Intuici%C3%B3 (dernière visite: 28/12/2016)
[2] Science’s top 10 breakthroughs of 2016: http://www.sciencemag.org/news/2016/12/ai-proteinfolding-our-breakthrough-runners? utm_source=sciencemagèche utm_medium=twitter utm_campaign=6319issue-10031 (dernière visite : 28/12/2016).
[3] Deep Blue (chess computer): https://en.wikipedia.org/wiki/Deep_Blue_(chess_computer) (dernière visite: 21/01/2017)
[4] Deep Mind: https://deepmind.com/ (dernière visite: 29/01/2017)
[5] Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
[6] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







