OCR en eúscaro
2003/05/01 Martinez Iraola, Edurne Iturria: Elhuyar aldizkaria
As vías de acceso, análise e recollida de información van cambiando. Nun tempo o mellor modo de recibir a información era o libro impreso, pero hoxe en día, pola contra, esiximos alternativas como a procura, copia e movemento da información, a clasificación, modificación e manipulación da mesma. Todas elas son opcións que non nos daban os textos tradicionais coñecidos até agora, pero na sociedade dixital actual as cousas son moi diferentes.
O uso da OCR está moi estendido no mercado vasco, aínda que iso supón una importante labor de corrección posterior. En Euskal Herria temos moitos xornais, revistas e editoriais, e na maioría dos casos o seu fondo documental non está gardado en formato dixital. A difusión de Internet, con todo, fixo necesario que todos estes fondos documentais estean debidamente dixitalizados e recolleitos paira organizar sistemas de catalogación e procura máis rápidos.
O OCR (Optical Character Recognition) é o coñecemento por computador dos caracteres de texto escritos ou impresos. Isto significa que cando usamos o software OCR escaneamos cada carácter coma se fose una foto, e despois analizamos esa imaxe escaneada e volvémola a un código de caracteres normal (por exemplo, ASCII).
A precisión do sistema OCR está limitada por tres factores: a calidade do documento orixinal, a calidade da imaxe creada polo escáner e a interpretación que sobre este último fai o software OCR. Aquí falaremos da última.
O que fai o OCR, en poucas palabras, é converter a imaxe escaneada en texto. Paira iso, analiza os diferentes puntos que compoñen a imaxe e distingue os ocos que hai entre eles. Este proceso denomínase segmentación e realízase en tres pasos: sepáranse as primeiras liñas (segmentación en liña), realízase o illamento das palabras (segmentación de palabras) e finalmente distínguense os caracteres (segmentación de caracteres). Esta última fase é máis sinxela se todos os caracteres son da mesma anchura, e complícase moito si tócanse entre si, se se mesturan con outras marcas de puntuación ou se o ancho depende da forma do carácter.
Paira realizar o coñecemento de carácter é necesario que o sistema OCR coñeza todos os caracteres do idioma do texto escaneado. Se xurdisen dúbidas cos caracteres, esperaría a que se complete a palabra, proceso no que será útil dispor dun dicionario desa lingua paira poder equiparala. Así, mediante un xogo de probabilidades e avaliando se se trata dunha palabra do dicionario, o sistema seleccionará un ou outro carácter.
Ao parecer, a existencia dun alfabeto e un dicionario nesa lingua sería suficiente paira aplicar correctamente o OCR, pero no caso do eúscaro non é así. Neste caso non se pode proporcionar una lista completa de palabras posibles, é dicir, non se pode crear un dicionario, xa que ao ser una lingua declinada, de cada una das raíces de palabras extráense demasiadas formas de palabra. As ferramentas lingüísticas van ser una gran axuda neste paso, é dicir, traballando as principais características do eúscaro podemos conseguir grandes melloras no desenvolvemento dun sistema OCR. Por exemplo, as agrupacións de caracteres ou palabras (ts, tz, tx, ou raias) que se realizan en eúscaro son menos habituais no resto das linguas europeas.
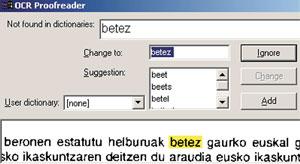
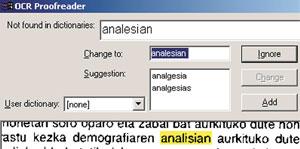
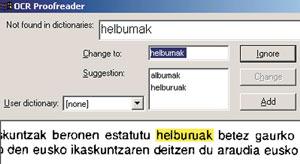
Coa maioría do software OCR que se utilizan actualmente, cando queremos analizar un texto en eúscaro, debemos utilizar o vocabulario dunha lingua en castelán. Con todo, nestes casos é preferible non utilizar vocabulario que o doutra lingua paira non cometer máis erros no texto. Por exemplo, se estamos a utilizar un dicionario en inglés, case seguro que substituirá a maioría das aparicións de seis palabras polo set. Se se está usando o castelán, a aparición da palabra enerxía substituiraa pola palabra energ (tache).
O resultado do proxecto desenvolvido en ELEKA é que ao software OCR máis utilizado na actualidade, o programa Omnipage, engadiuse una corrección en eúscaro xunto coa información morfológica do eúscaro. Este programa, paira o caso do eúscaro, está preparado paira dar o paso de converter a imaxe escaneada nun carácter. Até a data, con todo, non estaba preparada paira a fase posterior de verificación e corrección das palabras (aínda que está destinada ás linguas maioritarias: inglés, alemán). As seguintes intencións consistirán en engadir un corrector OCR como Xuxen paira os procesadores de textos Microsoft Word e OpenOffice, paira pór a disposición dos usuarios que non utilicen Omnipage o sistema OCR en eúscaro.
Por tanto, a través da incorporación de ferramentas lingüísticas en eúscaro desenvolveuse a ferramenta que mellor dixitaliza os textos en eúscaro. É dicir, ELEKA desenvolveu una ferramenta que entende e dirixe o eúscaro de forma automática á hora de dixitalizar os textos. Paira o desenvolvemento deste proxecto contou coa colaboración da Viceconsejería de Política Lingüística do Goberno Vasco, que se encargará da distribución desta aplicación.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia