Portal de Corpus Web: Gran almacén de textos en eúscaro realizados por Elhuyar I+D
Paira una lingua é moi importante dispor de corpus textuais (coleccións de textos que serven paira realizar estudos lingüísticos). Son imprescindibles paira a obtención de datos paira a realización de estudos lingüísticos ou paira a toma de decisións na estandarización lingüística. E son moi útiles tamén na creación de textos ou na tradución: pódennos explicar como se utilizaron ou traducido palabras que non aparecen nos dicionarios ou que non teñen exemplos suficientes.
Pero, ademais, os corpus son de vital importancia no mundo das tecnoloxías lingüísticas. Nos sistemas de recoñecemento de voz que traen os teléfonos móbiles intelixentes de hoxe en día, por exemplo, utilízanse corpus paira tentar inventar una palabra que non se entendeu do todo ben, mirando nos corpus cal é o máis probable nese contexto, ou os sistemas de tradución automática, por exemplo, utilizan corpus paralelos (corpus formados por textos que son traducións recíprocas) paira aprender, como contámosche no número de novembro de 2009.
Cantos corpus máis grandes mellor
Nese mesmo artigo destacabamos que canto máis grandes sexan estes corpus mellor. Paira consultar o uso dunha palabra rara haberá máis aparicións diferentes ou máis posibilidades de aparecer si o corpus é maior. A tradución automática require tamén corpus de tamaño o máis grande posible, por iso é polo que Google sexa referencia na tradución automática multilingüe, xa que cos textos que indexa paira o buscador fórmanse enormes corpus paralelos.
Como en moitos outros ámbitos, o eúscaro está moi por detrás doutras linguas con máis recursos, tanto en tamaño como en tempo. Repasemos a situación do inglés: o corpus inglés Brown, que se considera o punto de partida do moderna corpus, foi creado en 1964 e tiña un millón de palabras; o British National Corpus, de 100 millóns de palabras por palabra, é de 1995; e na actualidade existen corpus de miles de millóns de palabras en inglés. En canto aos corpus paralelos que inclúen o inglés, o sistema de tradución automática iniciado por Google en 2005 adestrouse sobre un corpus de 200.000 millóns de palabras.
En eúscaro, pola contra, o primeiro corpus (corpus textual do Dicionario Xeral Vasco de Euskaltzaindia) elaborouse en 1984 e consta de 4,6 millóns de palabras. XX de Euskaltzaindia. O Corpus Estatístico do Eúscaro do século XX finalizou en 2002 con 6 millóns de palabras. A Fundación Elhuyar e o Grupo IXA da UPV lanzaron en 2006 o Corpus de Ciencia e Tecnoloxía, con 9 millóns de palabras. A UPV-EHU tamén realizou ese mesmo ano o corpus denominado Actualidade de Prosa Exemplar, composto actualmente por 25,1 millóns de palabras. O Observatorio do Léxico de Euskaltzaindia, posto en marcha en 2010, conta na actualidade con 26,5 millóns de palabras. En canto aos corpus paralelos, as empresas de tradución probablemente son as máis grandes nas súas memorias de tradución. Pero hai moi poucos dispoñibles paira o público e dispoñibles en tecnoloxías lingüísticas; as memorias de tradución dos servizos de tradución dalgunhas institucións públicas (Servizo Oficial de Tradución do IVAP, Deputación Foral de Gipuzkoa, Deputación Foral de Bizkaia...) ou asociacións de vocación social (EIZIE, Librezale), e o corpus da revista Consumer de Eroski, que están por baixo de 5 millóns de palabras.
Solución web
A receita paira solucionar este problema proporcionábaa o experto en corpus Adam Kilgarriff no artigo antes mencionado: a web é a mellor forma de compor os corpus grandes dunha forma sinxela, económica e rápida. De feito, os xigantescos corpus dos últimos anos que mencionamos en inglés tamén se formaron así, vendo que a formación de corpus de forma clásica (recorrendo a editoriais ou medios de comunicación) é moito máis custosa e laboriosa.
Completar os corpus automaticamente desde a web tamén ten os seus contrarios. A súa principal obxección é que nela se poden atopar moitos textos de baixa calidade. Pero desde outro punto de vista, ese é o uso real da lingua actual e os corpus creados paira analizala. Ademais, se as linguas con moitos máis recursos dirixíronse á web, iso tamén é paira o eúscaro se non quere quedar atrás.
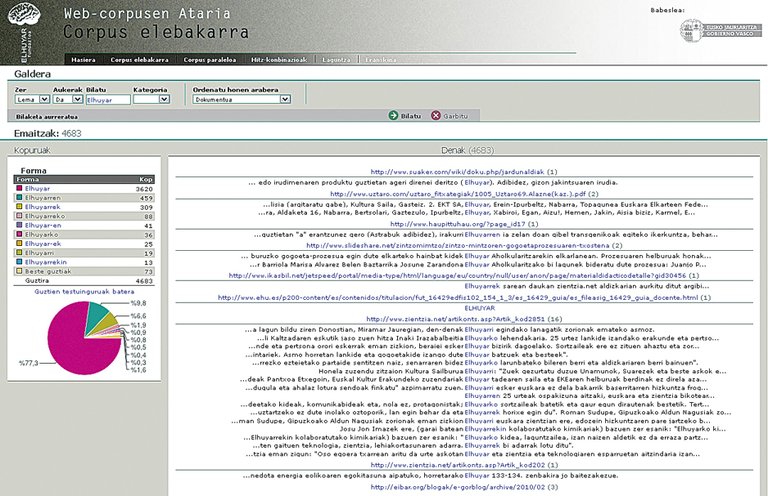
Portal de Corpus Web en Eúscaro
Os do grupo de I+D das tecnoloxías lingüísticas da Fundación Elhuyar levamos anos traballando no campo dos corpus web, é dicir, os corpus construídos utilizando métodos automáticos cos textos da web. Traballamos métodos de recompilación de diferentes tipos de corpus: corpus especializados en eúscaro (compostos por textos dunha determinada área de coñecemento), corpus multilingües comparables (compostos por textos do mesmo campo de coñecemento), corpus paralelos (compostos de textos que son traducións entre si), corpus xerais xigantescos... Paira iso é necesario desenvolver outras técnicas das tecnoloxías lingüísticas: acceso a páxinas web con certas palabras dos APIs dos buscadores, coñecemento do idioma dun texto, detección de textos repetidos ou moi similares, limpeza de páxinas web (paira eliminar pés, encabezados, menús de navegación, notas de copyright, etc.), spam extra, detección da área de coñecemento dun texto, tradución de coñecementos, etc.
A través destas ferramentas completamos moitos corpus de todos os tipos mencionados. E agora colgamos algúns destes corpus on-line no Portal de Corpus Web: Un gran corpus xeral de 125 millóns de palabras en eúscaro (o máis grande deste tipo até agora) e un corpus paralelo eúscaro-castelán de 18 millóns de palabras (tamén o máis grande dos corpus paralelos públicos). Sobre estes corpus permítese realizar diferentes tipos de procuras na web. Poden preguntarse por un lema ou forma determinada ou polo comezo ou terminación dos mesmos, en combinacións de até tres palabras a unha distancia máxima de 5 palabras. En paralelo pódense preguntar combinacións de até dúas palabras, pero se pode pedir que sexan nun, outro ou ambos os idiomas. Ambos son moi útiles paira ver como se utilizaron ou traducido as palabras.
Ademais, aplicando técnicas lingüísticas e estatísticas sobre o corpus monolingüe, calculáronse as tres combinacións máis utilizadas (nome, nome, verbo e nome adxectivo) e púxose a consulta. Desta forma podemos preguntar ao sistema con que verbo adóitase combinar una determinada palabra, con que adxectivo, etc.
A publicación do Portal de Corpus Web supón un salto cualitativo, xa que é a primeira vez que se pon a disposición do público os corpus extraídos automaticamente da web, así como cuantitativo, xa que supón un avance significativo no tamaño dos corpus. Koldo Mitxelena dicía que o verdadeiro misterio do eúscaro non é a súa orixe, senón a súa pervivencia. É máis misterio se se manterá no futuro. Nós non temos resposta a iso, pero para que se manteña o eúscaro ten que estar presente sen dúbida nas tecnoloxías lingüísticas. En Elhuyar estamos convencidos de que demos un paso máis nesta dirección co Portal de corpus web.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian