



Portal de Corpus Web: Large warehouse of texts in Basque made by Elhuyar I+D
For a language it is very important to have textual corpus (collections of texts that serve to perform linguistic studies). They are essential for obtaining data for the realization of linguistic studies or for decision-making in linguistic standardization. And they are very useful also in the creation of texts or translation: they can explain how words have been used or translated that do not appear in dictionaries or that do not have sufficient examples.
But, in addition, the corpus are of vital importance in the world of linguistic technologies. In the voice recognition systems brought by today's smart mobile phones, for example, corpus is used to try to invent a word that has not been fully understood, looking in the corpus what is most likely in that context, or the automatic translation systems, for example, use parallel corpus (corpus formed by texts that are reciprocal translations) to learn, as we tell you in the number of November 2009.
How many larger corpus better
In that same article we highlighted that the larger these corpus are better. To consult the use of a rare word there will be more different apparitions or more possibilities of appearing if the corpus is greater. Machine translation also requires corpus of size as big as possible, hence Google is a reference in the multilingual machine translation, since with the texts that indexa for the search engine are formed huge parallel corpus.
As in many other areas, Basque is far behind other languages with more resources, both in size and time. Let's review the situation of English: the English corpus Brown, which is considered the starting point of modern corpus, was created in 1964 and had a million words; the British National Corpus, of 100 million words per word, is of 1995; and currently there are billions of English words. As for the parallel corpus included in English, the machine translation system started by Google in 2005 was trained on a corpus of 200,000 million words.
In Basque, on the contrary, the first corpus (textual corpus of the Basque General Dictionary of Euskaltzaindia) was written in 1984 and consists of 4.6 million words. XX of Euskaltzaindia. The Statistical Corpus of the Basque Country of the twentieth century ended in 2002 with 6 million words. The Elhuyar Foundation and the IXA Group of the UPV launched the Corpus of Science and Technology in 2006, with 9 million words. The UPV-EHU also carried out that same year the corpus called Actualidad de Prosa Exemplar, currently composed of 25.1 million words. The Euskaltzaindia Lexicon Observatory, launched in 2010, currently has 26.5 million words. As for the parallel corpus, translation companies are probably the largest in their translation memories. But there are very few available to the public and available in linguistic technologies; the translation memories of the translation services of some public institutions (Official Translation Service of the IVAP, Diputación Foral de Gipuzkoa, Diputación Foral de Bizkaia...) or associations of social vocation (EIZIE, Librezale), and the corpus of the magazine Consumer de Words
Web Solution Web Solution
The recipe for solving this problem was provided by the expert in corpus Adam Kilgarriff in the aforementioned article: the web is the best way to compose large corpus in a simple, economical and fast way. In fact, the gigantic corpus of the last years we have mentioned in English have also been formed this way, seeing that the formation of corpus in a classical way (resorting to publishers or media) is much more costly and laborious.
Completing the corpus automatically from the web also has its counterparts. Its main objection is that in it you can find many texts of low quality. But from another point of view, that is the actual use of the current language and the corpus created to analyze it. In addition, if the languages with many more resources have been directed to the web, that is also for the Basque language if it does not want to stay behind.
Portal de Corpus Web en Euskera
Those of the R&D group of linguistic technologies of the Elhuyar Foundation have spent years working in the field of web corpus, that is, the corpus constructed using automatic methods with the texts of the web. We have worked methods of compilation of different types of corpus: corpus specialized in Basque (composed of texts of a certain area of knowledge), comparable multilingual corpus (composed of texts of the same field of knowledge), parallel corpus (composed of texts that are translations among themselves), gigantic general corpus... To do this it is necessary to develop other techniques of linguistic technologies: access to web pages with certain words of search engines APIs, knowledge of the language of a text, detection of repeated or very similar texts, cleaning of web pages (to remove feet, headers, navigation menus, copyright notes, etc. ), extra spam, detection of the area of knowledge of a text, translation of knowledge, etc.
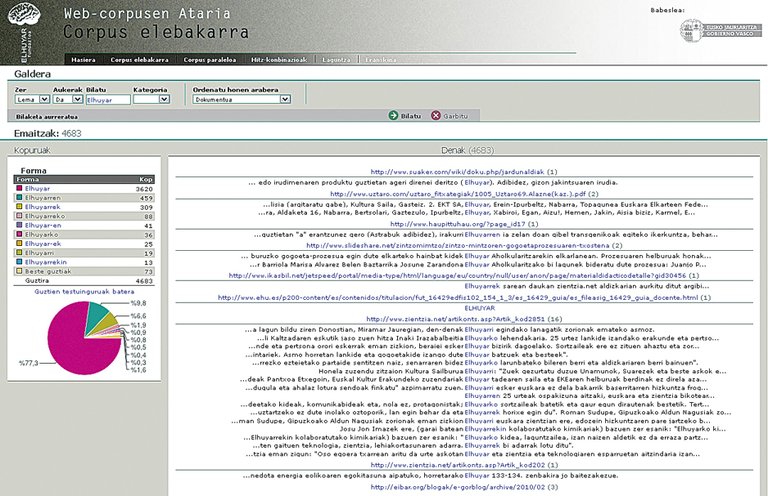
Through these tools we have completed many corpus of all the types mentioned. And now we have hung some of these on-line corpus on the Portal de Corpus Web: A large general corpus of 125 million words in Basque (the largest of this type so far) and a parallel corpus Euskera-Spanish of 18 million words (also the largest of public parallel corpus). On these corpus it is possible to perform different types of searches on the web. They can be asked by a specific motto or form or by the beginning or completion of them, in combinations of up to three words at a maximum distance of 5 words. In parallel you can ask combinations of up to two words, but you can ask them to be in one, another or both languages. Both are very useful to see how words have been used or translated.
In addition, applying linguistic techniques and statistics on monolingual corpus, the three most commonly used combinations (name, name, verb and adjective name) have been calculated and have been consulted. In this way we can ask the system with which verb is usually combined a certain word, with which adjective, etc.
The publication of the Portal de Corpus Web is a qualitative leap, since it is the first time that the corpus automatically extracted from the web and quantitative are made available to the public, since it represents a significant advance in the size of the corpus. Koldo Mitxelena said that the true mystery of the Basque language is not its origin, but its survival. It is more mystery if it will remain in the future. We have no answer to this, but for the Basque language to be maintained, it must undoubtedly be present in linguistic technologies. In Elhuyar we are convinced that we have taken another step in this direction with the Portal de corpus web.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







