Portal de Corpus Web: Gran magatzem de textos en basc realitzats per Elhuyar I+
Per a una llengua és molt important disposar de corpus textuals (col·leccions de textos que serveixen per a realitzar estudis lingüístics). Són imprescindibles per a l'obtenció de dades per a la realització d'estudis lingüístics o per a la presa de decisions en l'estandardització lingüística. I són molt útils també en la creació de textos o en la traducció: ens poden explicar com s'han utilitzat o traduït paraules que no apareixen en els diccionaris o que no tenen exemples suficients.
Però, a més, els corpus són de vital importància en el món de les tecnologies lingüístiques. En els sistemes de reconeixement de veu que porten els telèfons mòbils intel·ligents d'avui dia, per exemple, s'utilitzen corpus per a intentar inventar una paraula que no s'ha entès del tot bé, mirant en els corpus quin és el més probable en aquest context, o els sistemes de traducció automàtica, per exemple, utilitzen corpus paral·lels (corpus formats per textos que són traduccions recíproques) per a aprendre, com et comptem en el número de novembre de 2009.
Quants corpus més grans millor
En aquest mateix article destacàvem que com més grans siguin aquests corpus millor. Per a consultar l'ús d'una paraula estranya hi haurà més aparicions diferents o més possibilitats d'aparèixer si el corpus és major. La traducció automàtica requereix també corpus de grandària el més gran possible, per aquest motiu Google sigui referència en la traducció automàtica multilingüe, ja que amb els textos que indexa per al cercador es formen enormes corpus paral·lels.
Com en molts altres àmbits, el basc està molt per darrere d'altres llengües amb més recursos, tant en grandària com en temps. Repassem la situació de l'anglès: el corpus anglès Brown, que es considera el punt de partida de la moderna corpus, va ser creat en 1964 i tenia un milió de paraules; el British National Corpus, de 100 milions de paraules per paraula, és de 1995; i en l'actualitat existeixen corpus de milers de milions de paraules en anglès. Quant als corpus paral·lels que inclouen l'anglès, el sistema de traducció automàtica iniciat per Google en 2005 es va entrenar sobre un corpus de 200.000 milions de paraules.
En basc, per contra, el primer corpus (corpus textual del Diccionari General Basc d'Euskaltzaindia) es va elaborar en 1984 i consta de 4,6 milions de paraules. XX d'Euskaltzaindia. El Corpus Estadístic del Basc del segle XX va finalitzar en 2002 amb 6 milions de paraules. La Fundació Elhuyar i el Grup IXA de la UPV van llançar en 2006 el Corpus de Ciència i Tecnologia, amb 9 milions de paraules. La UPV-EHU també va realitzar aquest mateix any el corpus denominat Actualitat de Prosa Exemplar, compost actualment per 25,1 milions de paraules. L'Observatori del Lèxic d'Euskaltzaindia, posat en marxa en 2010, compte en l'actualitat amb 26,5 milions de paraules. Quant als corpus paral·lels, les empreses de traducció probablement són les més grans en les seves memòries de traducció. Però hi ha molt pocs disponibles per al públic i disponibles en tecnologies lingüístiques; les memòries de traducció dels serveis de traducció d'algunes institucions públiques (Servei Oficial de Traducció de l'IVAP, Diputació Foral de Guipúscoa, Diputació Foral de Bizkaia...) o associacions de vocació social (EIZIE, Librezale), i el corpus de la revista Consumer d'Eroski, que estan per sota de 5 milions de paraules.
Solució web
La recepta per a solucionar aquest problema la proporcionava l'expert en corpus Adam Kilgarriff en l'article abans esmentat: la web és la millor manera de compondre els corpus grans d'una forma senzilla, econòmica i ràpida. De fet, els gegantescos corpus dels últims anys que hem esmentat en anglès també s'han format així, veient que la formació de corpus de manera clàssica (recorrent a editorials o mitjans de comunicació) és molt més costosa i laboriosa.
Completar els corpus automàticament des de la web també té els seus contraris. La seva principal objecció és que en ella es poden trobar molts textos de baixa qualitat. Però des d'un altre punt de vista, aquest és l'ús real de la llengua actual i els corpus creats per a analitzar-la. A més, si les llengües amb molts més recursos s'han dirigit a la web, això també és per al basc si no vol quedar-se enrere.
Portal de Corpus Web en Basc
Els del grup d'I+D de les tecnologies lingüístiques de la Fundació Elhuyar portem anys treballant en el camp dels corpus web, és a dir, els corpus construïts utilitzant mètodes automàtics amb els textos de la web. Hem treballat mètodes de recopilació de diferents tipus de corpus: corpus especialitzats en basc (compostos per textos d'una determinada àrea de coneixement), corpus multilingües comparables (compostos per textos del mateix camp de coneixement), corpus paral·lels (compostos de textos que són traduccions entre si), corpus generals gegantescos... Per a això és necessari desenvolupar altres tècniques de les tecnologies lingüístiques: accés a pàgines web amb certes paraules dels APIs dels cercadors, coneixement de l'idioma d'un text, detecció de textos repetits o molt similars, neteja de pàgines web (per a eliminar peus, encapçalats, menús de navegació, notes de copyright, etc.), spam extra, detecció de l'àrea de coneixement d'un text, traducció de coneixements, etc.
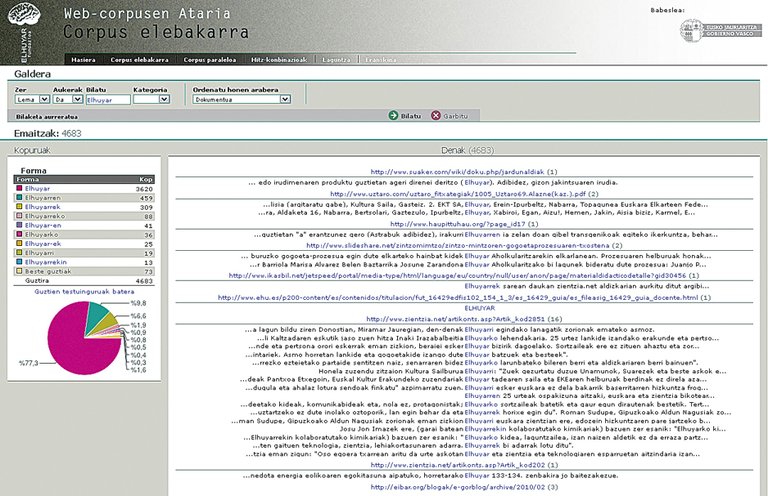
A través d'aquestes eines hem completat molts corpus de tots els tipus esmentats. I ara hem penjat alguns d'aquests corpus on-line en el Portal de Corpus Web: Un gran corpus general de 125 milions de paraules en basca (el més gran d'aquest tipus fins ara) i un corpus paral·lel basc-castellà de 18 milions de paraules (també el més gran dels corpus paral·lels públics). Sobre aquests corpus es permet realitzar diferents tipus de cerques en la web. Poden preguntar-se per un lema o forma determinada o pel començament o terminació d'aquests, en combinacions de fins a tres paraules a una distància màxima de 5 paraules. En paral·lel es poden preguntar combinacions de fins a dues paraules, però es pot demanar que siguin en un, un altre o tots dos idiomes. Tots dos són molt útils per a veure com s'han utilitzat o traduït les paraules.
A més, aplicant tècniques lingüístiques i estadístiques sobre el corpus monolingüe, s'han calculat les tres combinacions més utilitzades (nom, nom, verb i nom adjectiu) i s'ha posat a consulta. D'aquesta forma podem preguntar al sistema amb quin verb se sol combinar una determinada paraula, amb quin adjectiu, etc.
La publicació del Portal de Corpus Web suposa un salt qualitatiu, ja que és la primera vegada que es posen a la disposició del públic els corpus extrets automàticament de la web, així com quantitatiu, ja que suposa un avanç significatiu en la grandària dels corpus. Koldo Mitxelena deia que el veritable misteri del basc no és el seu origen, sinó la seva pervivència. És més misteri si es mantindrà en el futur. Nosaltres no tenim resposta a això, però perquè es mantingui el basc ha d'estar present sens dubte en les tecnologies lingüístiques. En Elhuyar estem convençuts que hem fet un pas més en aquesta adreça amb el Portal de corpus web.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian