



Outil pour scanner les textes basques en basque

Lorsque nous utilisons le logiciel OCR, chaque caractère est scanné comme s'il s'agissait d'une photo, puis analysé cette image scannée et retourné à un code de caractères normal (par exemple ASCII).
La précision du système OCR est limitée par trois facteurs: la qualité du document original, la qualité de l'image créée par le scanner et l'interprétation que fait le logiciel OCR sur ce dernier. ELEKA a développé un outil pour réaliser cette interprétation en basque.
Pour transformer l'image numérisée en texte, l'OCR analyse les points qui la composent et distingue les trous entre eux. Ce processus est appelé segmentation et se fait en trois étapes: d'abord les lignes sont séparées, puis les mots sont isolés et finalement les caractères sont séparés. Cette dernière phase est plus simple si tous les caractères sont de la même largeur, et se complique beaucoup s'ils sont joués entre eux, s'ils sont mélangés avec d'autres marques de ponctuation ou si la largeur dépend de la forme du caractère.
La singularité de l'euskera
Pour réaliser la connaissance de caractère, il est nécessaire que le système OCR connaisse tous les caractères de la langue du texte scanné. Si des doutes survenaient avec les caractères, j'attendrais que le mot soit complété, processus dans lequel il sera utile d'avoir un dictionnaire de cette langue pour pouvoir l'assimiler. Ainsi, en utilisant un jeu de probabilités et en évaluant si c'est un mot du dictionnaire, le système sélectionnera un ou l'autre caractère.
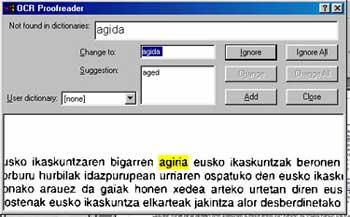
En théorie, il suffit d'avoir un alphabet et un dictionnaire dans cette langue pour appliquer correctement l'OCR, mais dans le cas de l'euskera ce n'est pas le cas. On ne peut pas donner une liste complète des mots possibles, c'est-à-dire qu'on ne peut pas créer un dictionnaire, car étant une langue déclinée, de chacune des racines sortent trop de formes de mots. Les outils linguistiques apporteront une grande aide à cette étape, c'est-à-dire en travaillant les principales caractéristiques du basque on peut obtenir de grandes améliorations pour développer un système OCR. Par exemple, les combinaisons de caractères ou de mots qui sont faites en basque (utilisation de ts, tz, tx, ou rayures) sont moins fréquentes dans les autres langues européennes.
Avec la plupart des logiciels OCR actuellement utilisés, lorsque nous voulons analyser un texte en basque, nous devons utiliser le vocabulaire d'une langue en espagnol. Cependant, dans ces cas, il est préférable de ne pas utiliser de vocabulaire que celui d'une autre langue pour ne pas faire plus d'erreurs dans le texte. Par exemple, si nous utilisons un dictionnaire anglais, il est presque certain qu'il remplacera la plupart des "six" par "set". Si vous utilisez l'espagnol, le mot "énergie" est remplacé par "énergie" (avec tilde).
Correcteur pour le basque
ELEKA a développé un plug-in de correction en euskera pour le programme Omnipage, le logiciel OCR le plus utilisé. Ce programme était prêt à convertir en caractères l'image scannée aussi dans le cas de l'euskera, mais pas pour la phase postérieure de vérification et de correction de mots. ELEKA a ajouté au programme des informations morphologiques du basque pour numériser au mieux les textes en basque.
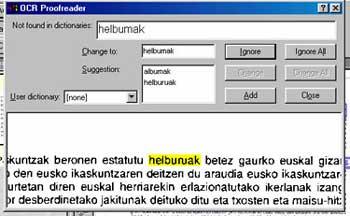
Les intentions suivantes consisteront à ajouter un correcteur OCR comme Xuxen pour les processeurs de texte Microsoft Word et OpenOffice, pour mettre à la disposition des utilisateurs qui n'utilisent pas Omnipage le système OCR en basque.
Le projet a été développé en collaboration avec la Vice-conseillère de Politique Linguistique du Gouvernement Basque et sera bientôt dans la rue.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







