



Herramienta para escanear textos vascos en euskera

Cuando utilizamos el software OCR, cada carácter se escanea como si fuera una foto y después se analiza esa imagen escaneada y se vuelve a un código de caracteres normal (por ejemplo ASCII).
La precisión del sistema OCR está limitada por tres factores: la calidad del documento original, la calidad de la imagen creada por el escáner y la interpretación que sobre este último hace el software OCR. ELEKA ha desarrollado una herramienta para realizar esta interpretación en euskera.
Para transformar la imagen escaneada en texto, la OCR analiza los puntos que la componen y distingue los huecos que hay entre ellos. Este proceso se denomina segmentación y se realiza en tres pasos: primero se separan las líneas, luego se aíslan las palabras y finalmente se separan los caracteres. Esta última fase es más sencilla si todos los caracteres son de la misma anchura, y se complica mucho si se tocan entre sí, si se mezclan con otras marcas de puntuación o si el ancho depende de la forma del carácter.
La singularidad del euskera
Para realizar el conocimiento de carácter es necesario que el sistema OCR conozca todos los caracteres del idioma del texto escaneado. Si surgieran dudas con los caracteres, esperaría a que se complete la palabra, proceso en el que será útil disponer de un diccionario de esa lengua para poder equipararla. Así, mediante un juego de probabilidades y evaluando si se trata de una palabra del diccionario, el sistema seleccionará uno u otro carácter.
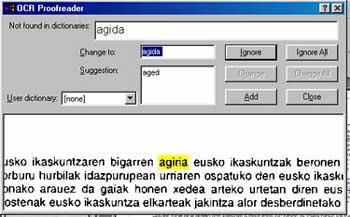
En teoría, basta con tener un alfabeto y un diccionario en esa lengua para aplicar correctamente el OCR, pero en el caso del euskera no es así. No se puede dar una lista completa de palabras posibles, es decir, no se puede crear un diccionario, ya que al ser una lengua declinada, de cada una de las raíces salen demasiadas formas de palabra. Las herramientas lingüísticas aportarán gran ayuda en este paso, es decir, trabajando las principales características del euskera se pueden conseguir grandes mejoras para desarrollar un sistema OCR. Por ejemplo, las combinaciones de caracteres o palabras que se hacen en euskera (uso de ts, tz, tx, o rayas) son menos comunes en el resto de lenguas europeas.
Con la mayoría de los software OCR que se utilizan actualmente, cuando queremos analizar un texto en euskera, debemos utilizar el vocabulario de una lengua en castellano. Sin embargo, en estos casos es preferible no utilizar vocabulario que el de otra lengua para no cometer más errores en el texto. Por ejemplo, si estamos utilizando un diccionario en inglés, casi seguro que sustituirá la mayoría de las apariciones de "seis" por "set". Si se está usando el castellano, la palabra "energía" se sustituye por "energía" (con tilde).
Corrector para el euskera
ELEKA ha desarrollado un plug-in de corrección en euskera para el programa Omnipage, el software OCR más utilizado. Este programa estaba preparado para convertir en caracteres la imagen escaneada también en el caso del euskera, pero no para la fase posterior de verificación y corrección de palabras. ELEKA ha añadido al programa información morfológica del euskera para digitalizar de la mejor manera posible los textos en euskera.
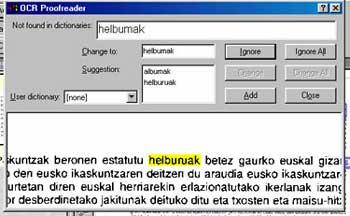
Las siguientes intenciones consistirán en añadir un corrector OCR como Xuxen para los procesadores de textos Microsoft Word y OpenOffice, para poner a disposición de los usuarios que no utilicen Omnipage el sistema OCR en euskera.
El proyecto ha sido desarrollado en colaboración con la Viceconsejería de Política Lingüística del Gobierno Vasco y estará en breve en la calle.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian
Bizitza

Uzta teknologikoa
Teknologia

Laborategia sukaldean
Teknologia

Agrovoltaikoa: eguzki-plakak soroan
Teknologia




