



Futura voz

Hai uns meses, con motivo da creación dunha base de datos de voz en eúscaro, Telefónica convocou a gravación de 10.000 voces de vascos. Paira iso púxose un número de teléfono gratuíto ao que o llamante debía repetir frases e números que dicía un computador. O que ía dicir o computador foi preparado polo Departamento de Filoloxía Vasca da UPV/EHU coa intención de recoller todos os sons habituais en eúscaro. Paira iso analizouse un macrotexto proporcionado por UZEI. A pesar de que os responsables do proxecto necesitaban polo menos 5.000 chamadas, recibiron preto de 19.000, a pesar de que resultaron útiles –que repetieron todo o que dixeran o computador– 11.200. O proxecto contou coa participación de EITB, que gravou todo o que dicía o computador o persoal local e realizou una campaña de captación de voz.
A información recollida nas chamadas telefónicas recolleuse en Leioa, Departamento de Electricidade e Electrónica da Universidade do País Vasco. A información dixital recompilada agora debe ser procesada e posteriormente constituirá a base de datos. Esta base de datos que se crea poderase utilizar cos coñecedores da voz, polo que poderán seguir investigando nesta materia. Pola súa banda, a Facultade de Filoloxía tamén poderá aproveitar a información recibida paira realizar investigacións sobre a fonología do eúscaro actual. Se se avanza no camiño previsto, este proxecto permitirá en breve acceder a novos servizos en eúscaro: marcas telefónicas por voz, telelectura de contadores, validación de cartóns de crédito, banca electrónica, compras telefónicas….
Sistema de recoñecemento automático de membranas
O que parece una cuestión de futuro son o pan de cada día no Departamento de Electricidade e Electrónica da UPV, xa que o equipo de Coñecemento da Voz dedica horas e horas a iso. Os computadores chegarán a falar, parece que non hai dúbida diso. Como se lles fai falar? Como se lles ensina?
O noso cerebro constrúe unha mensaxe no seu interior seguindo as regras da linguaxe. A continuación, utilizando o sistema de creación da voz do corpo, produce una onda moi rica en armónicos, o sinal de voz. Este sinal acústico ten varias características: enerxía, armónicos reducidos na banda de frecuencia de 7-8 kHz, frecuencia básica, etc. Neste sinal hai ruídos. Estes sons, segundo as regras da linguaxe, constitúen unidades léxicas. Cada ruído ten as súas características acústicas. Por tanto, estes elementos, sons e unidades léxicas que aparecen codificados no sinal de voz, deben ser descodificados paira coñecer a mensaxe xerada.

Paira poder utilizar o sinal de voz no computador é necesario muestrearla. Paira iso, o sinal analóxico convértese en dixital. A continuación se parametriza o sinal dixital paira reducir a información redundante da voz, é dicir, extráense as características máis características do sinal: enerxía, frecuencia básica, certos parámetros relacionados coas frecuencias, etc.
O recoñecemento da voz realízase mediante dúas técnicas, una baseada en palabras illadas ou silenciosas, e a outra é a denominada membrana continua. En ambos os casos, para que o sistema entenda a mensaxe, debe dispor dun descodificador de modelos acústicos: no caso de palabras illadas utilízanse modelos de palabras e no caso da lingua continua, modelos de sons e unidades léxicas.
No primeiro caso, o funcionamento do sistema é moi sinxelo: compárase o sinal cos modelos de palabras que se estudaron e elíxese o modelo de palabra máis parecido. En canto ao coñecemento da linguaxe continua, o proceso divídese en dúas fases: a descodificación acústico-fonética e a modelización da linguaxe. Na fase de descodificación acústico-fonético obtense a cadea de sons do sinal de voz. A continuación, na fase de modelización da linguaxe, obtéñense as unidades léxicas e, utilizando regras sintácticas e semánticas, se descodifica a mensaxe que contén o sinal. Nese momento xa o computador é capaz de coñecer o idioma.
O proceso leva a cabo mediante diferentes métodos matemáticos. En canto aos modelos acústicos, as aproximacións estrutural-estocásticas, modelos ocultos de Markov. Doutra banda, paira aprender modelos e coñecer a mensaxe, outros algoritmos: Baum-Welch, Viterbi.
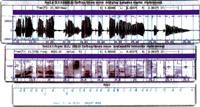
E é que para que o sistema funcione correctamente ten que coñecer cada ruído. Por tanto, debe aprender diferentes mostras de cada son, xa que os sons producidos por unha e outra persoa son diferentes. Por iso, nesta fase de coñecemento automático da linguaxe é imprescindible contar cunha gran base de datos, xa que cantos máis falantes haxa, máis características poderá recoller e coñecer o sistema. É dicir, para que o sistema poida coñecer cada un dos sons necesita una gran cantidade de mostras de cada un deles.
Eúscaro especial?
Até a data, e tamén na UPV, traballouse maioritariamente con modelos en castelán, pero o traballo do grupo de recoñecemento automático da lingua vai chegar pronto, xa que desde hai anos está a traballarse maioritariamente co eúscaro. Desde o punto de vista das características da lingua, o eúscaro pode ter peculiaridades. "En canto aos sons, di Karmele Lopez de Ipiña, integrante do Grupo de Recoñecemento Automático Mintzo, non parece que sexa máis difícil que o resto de linguas, porque niso non hai nada raro. En canto ao léxico, o eúscaro é especial, xa que a lingua é adhesivo. Por exemplo, paira nós a palabra casa é casa, pero paira eles o que é de casa —a palabra non cambia— paira nós é de casa, e iso é una palabra nova. O eúscaro ten un gran futuro no campo do coñecemento oral automático, sobre todo polo interese que espertou na comunidade científica grazas ás súas características específicas".
A base de datos de Telefónica tivo eco, pero no Departamento de Electricidade e Electrónica da UPV/EHU de Leioa colaboraron co apoio do Departamento de Filoloxía Vasca de Vitoria-Gasteiz e coa subvención do Goberno Vasco. "Desde hai moitos anos o noso grupo comezou a desenvolver un sistema de recoñecemento automático da lingua vasca. En concreto, deseñáronse dúas bases de datos de voz, una paira o seu uso en aplicacións telefónicas e outra paira o desenvolvemento de sistemas de calquera tipo. Con iso, no que respecta ás bases de datos fonéticas, conseguimos equiparalas a outras linguas. Se nos fixamos nas persoas que traballan neste campo no mundo, podemos dicir que non estamos tan mal, estamos nun par".
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










