



Correcteur orthographique pour l'euskera XUXEN
En septembre dernier a eu lieu au centre culturel Koldo Mitxelena de Donostia la présentation du correcteur orthographique pour l'euskera Xuxen. Nous avons eu l'occasion de parler calmement de ce qu'il avait vu avec Iñaki Alegria, l'un des auteurs. Le résultat de cette interview est le suivant.
Elhuyar.- Qu'est-ce que le programme Xuxen?
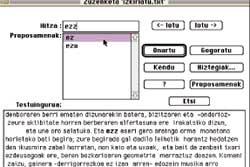
I. Alegria.- Correcteur orthographique pour textes écrits en basque, Xuxen vise à détecter et corriger l'orthographe des textes en basque, c'est-à-dire à détecter et corriger les erreurs typographiques et orthographiques. Pour ce but l'euskera unifié est celui qui approuve le programme. Vous pouvez analyser un ou plusieurs documents dans chaque exécution. Les documents sont traités littéralement et pendant que vous connaissez les mots, vous continuez à travailler, mais quand vous ne connaissez pas un mot, vous êtes averti et arrêté. Face au vide potentiel, l'utilisateur peut accepter, diriger les utilisateurs, demander les propositions offertes par le programme de correction ou encore accéder au dictionnaire personnel pour qu'il reconnaisse toutes les formes dérivées de ce slogan (voir figure 1).
Elh.- Combien de temps avez-vous pris pour compléter le programme? et qui avez-vous participé ?
I.A.- L'élaboration du programme a été un grand travail principalement pour deux raisons: la complexité morphologique du basque elle-même et le manque d'une description systématique de la morphologie du basque.
Profitant de l'analyseur morphologique automatique réalisé précédemment, ce programme développé au cours des trois dernières années a été le fruit de la collaboration entre la Faculté d'Informatique de l'UPV/EHU, UZEI et la société Hizkia de Baiona. L'équipe de la Faculté d'Informatique a développé et coordonné le prototype, UZEI lui a accordé une garantie linguistique et Hizkia a assumé la responsabilité du produit commercial. Des versions pour Macintosh et PC ont été préparées. Dans ce travail, la collaboration de: IVAP/IVAP, Département d'Économie de la Députation Forale de Gipuzkoa et Programme de Coopération Euskadi/Aquitaine.
Elh.- Quelles sont les caractéristiques de conception du programme Xuxen ?
I.A.- En raison de la complexité morphologique de l'euskera, on ne peut pas consulter une liste de mots comme on le fait pour d'autres langues pour décider si un mot est bien ou pas, et il est terminé; puisque les formes légitimes qui peuvent être créées à partir d'une devise sont nombreuses, la liste serait énorme. Par exemple, si nous partons d'un nom, en ajoutant un seul suffixe de déclin, nous pouvons obtenir 135 formes légales (si nous prenons en compte les ellipses ce nombre augmente énormément). De plus, s'il avait agi de cette façon, au lieu de comprendre tout son déclin en introduisant seulement la devise dans le dictionnaire de l'utilisateur, comme dans Xuxen, l'utilisateur devrait introduire une à une toutes les formes qui correspondent à cette devise. Pour tout ce qui précède, il a été nécessaire d'effectuer une analyse morphologique permettant d'identifier correctement les mots licites.
Fdo.- Commente que l'analyse morphologique a été fondamentale, quelles mesures avez-vous prises pour y remédier?
I.A.- L'analyse morphologique est basée sur le formalisme à deux niveaux proposé par le professeur Koskenniemi de l'Université d'Helsinki en 1983. Bien que ce formalisme ait été proposé initialement pour le suomais, il a été un succès pour toute autre langue et pour les langues annexes comme le basque. Les caractéristiques principales de ce formalisme sont la séparation claire entre les mots qui apparaissent dans les textes, le niveau superficiel, et le lexique, le niveau lexique, qui sert à l'analyse et la synthèse, et la distinction entre le programme et la découverte linguistique. L'information linguistique est composée de lexiques morphèmes et de règles morphophoniques.
Le lexique a plus de 60.000 entrées, stockées dans une base de données et distribuées dans 120 sous-échantillons. Chaque entrée est attribuée à une classe de suite qui définit l'ensemble des suffixes qui peuvent venir derrière elle. Les altérations superficielles de la collecte des morphes se manifestent dans vingt-quatre règles morpho-phonologiques. Chacune de ces règles indique quand une insertion, une suppression ou une modification d'un caractère se produit. Par exemple, la règle octave décrit la modification suivante : la lettre k du lexique est transformée en g de la couverture si la lettre k est un suffixe « ko », et si la précédente est un slogan fini avec n lettres ou un nom de lieu fini avec l, m ou n lettres. Par exemple, lors de la collecte des morphèmes, la forme est créée.
Avec les mots les plus utilisés pour augmenter la vitesse, une liste a été élaborée pour éviter son analyse morphologique.
Fdo.- La proposition de correction est l'une des options offertes par le programme, en quoi consiste?

I.A.- En cas d'erreur, l'utilisateur peut demander des propositions au programme. Dans ce travail, les erreurs typographiques et orthographiques ont un traitement différent. Dans les typographiques on considère comme source de l'erreur la perte d'un caractère, l'insertion ou la variation ou l'échange de deux caractères continus, en cherchant de façon inverse les mots appropriés à proposer.
Les erreurs provoquées par la faible connaissance de l'euskera, le manque de connaissance des derniers changements dans l'unité ou l'usage dialectal sont appelées orthographiques ou typiques. Pour la détection et la correction, Xuxen a une semelle et des règles spéciales. Par exemple, haundi est lié à la grande forme préférée dans une forme lexicale spéciale ; en effectuant l'analyse de la « grande » on obtient de haundi+, mais quand haundi est marqué comme erreur il devient grand et, par conséquent, apparaît comme proposition une grande génération de grande + sable. Parmi les règles spéciales on trouve celles qui décrivent la perte de h et la variation de x-s. Ainsi, lors de l'analyse en zuaitxe on obtient automatiquement arbre + ko et avec création la proposition d'arbre.
Elh.- Quel modèle linguistique avez-vous utilisé?
I.A.- Compte tenu de la flexion de l'euskera, il a fallu construire un système de déclinaison utile par ordinateur. Pour cela, nous nous sommes basés sur le tableau proposé par Euskaltzaindia et nous l'avons adapté à notre système, c'est-à-dire que nous avons pris ce tableau et avons regroupé les cas qui correspondent à chaque catégorie de lexique. Ainsi, à chaque base correspond un suffixe unique, composé des suffixes qu'il peut prendre.
Dans la dérivation il y a quelques préfixes et suffixes travaillés, mais les plus communs sont comme des entrées de dictionnaire. Cependant, l'utilisateur peut introduire dans son dictionnaire de nouveaux mots dérivés. Dans l'association de mots on a travaillé pour le moment le plus habituel et systématisant selon les critères marqués par la Commission LEF d'Euskaltzaindia. Le verbe factif est également traité systématiquement
Quant au verbe, Xuxen connaît les formes tant du verbe auxiliaire que du massif, à condition que Euskaltzaindia décide. Il reconnaît des formes neutres, non marquées ou hitaniennes.
Si dans la partie grammaire la seule source normative a été la Real Academia de la Lengua Vasca-Euskaltzaindia, ce n'est pas quand on commence à travailler le lexique. Les recommandations et décisions dans chaque cas ont été formulées à quelques points: Lettre H, -a propre, composition et écriture des nombres, etc. Ce sont ceux que nous avons suivis au moment de compléter le lexique, bien que dans le cas des nombres, pour le moment, nous maintenons les deux options (admettant vingt-cinq et vingt-cinq). Un autre point est arrivé avec les noms des personnes et des lieux, ainsi que dans l'écriture des prêts.
Pour créer le vocabulaire de base, c'est-à-dire la liste des lemmes les plus fréquents dans n'importe quel lexique, nous avons dû recourir à d'autres sources actuelles : Dictionnaire Basque de Libre Choix d'Ibon Sarasola, banque de données Euskalterm d'UZEI et base de données lexicographique EEBS, Xabier Kintana et autres Hiztegia 2000, J.M. Dictionnaire de Fréquence et Disponibilité d'Etxebarria, etc. Quand ils ne sont pas conformes aux critères d'Euskaltzaindia, les entrées ont été “adaptés”, et où ils n'ont pas été convenus par Euskaltzaindia, le dictionnaire d'Ibon Sarasola a été la source de critères.
Pour compléter le vocabulaire de base, des expressions, locutions et formes complexes ont été adoptées depuis le SEE de l'UZEI. Les acronymes et abréviations ont également été travaillés selon les critères de l'UZEI. En partant du vocabulaire commun, il a parfois fallu arriver à la terminologie. Euskalterm a été indispensable dans ces cas.
Pour compléter la liste des noms propres (bien que les noms propres ne proviennent pas de dictionnaires communs) on a recouru à deux sources : la première a été la liste des noms basques et des lieux proposés par Euskaltzaindia, mais pour obtenir la liste des noms de lieu du monde on a recouru à Elhuyar.
A partir de toutes ces sources, nous avons élaboré un vocabulaire de grande taille contenant au moins un lexique de textes communs. Cependant, la terminologie des sujets spécifiques sera de libre inclusion dans votre vocabulaire personnel.
Elh.- Que regardons-nous vers l'avenir?
I.A.- En groupe, nous voulons faire face à l'analyse syntaxique automatique dans les prochaines années. De cette façon, XUXEN du futur aura la possibilité d'effectuer une correction avancée. D'autre part, notre groupe travaille également à l'élaboration de dictionnaires, dans le but d'obtenir une meilleure performance dans l'application de ressources informatiques aux dictionnaires. Cependant, sur la base de l'analyse morphologique, nous prétendons extraire le lemmatiseur automatique EUSLEM dans un an.

Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










