



Corrector ortográfico para el euskera XUXEN
El pasado mes de septiembre tuvo lugar en el centro cultural Koldo Mitxelena de Donostia la presentación del corrector ortográfico para el euskera Xuxen. Tuvimos la oportunidad de hablar con calma sobre lo que allí se había visto con Iñaki Alegría, uno de los autores. El resultado de esta entrevista es el siguiente.
Elhuyar.- ¿Qué es el programa Xuxen?
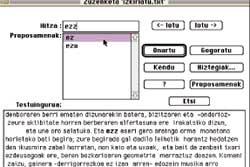
I. Alegria.- Corrector ortográfico para textos escritos en euskera, Xuxen pretende detectar y corregir la ortografía de textos en euskera, es decir, detectar y corregir errores tipográficos y ortográficos. Para este objetivo el euskera unificado es el que aprueba el programa. Puede analizar uno o varios documentos en cada ejecución. Los documentos se tratan literalmente y mientras conoce las palabras sigue trabajando, pero cuando no conoce alguna palabra se avisa y se detiene. Ante el posible vacío, el usuario podrá aceptar, dirigir a los usuarios, solicitar las propuestas que ofrece el programa de corrección o, de nuevo, acceder al diccionario personal para que reconozca todas las formas derivadas de este lema (ver figura 1).
Elh.- ¿Cuánto tiempo habéis tardado en completar el programa? ¿y quiénes habéis participado?
I.A.- La elaboración del programa ha sido una gran labor principalmente por dos razones: la propia complejidad morfológica del euskera y la falta de una descripción sistemática de la morfología del euskera.
Aprovechando el analizador morfológico automático realizado anteriormente, este programa desarrollado durante los últimos tres años ha sido fruto de la colaboración entre la Facultad de Informática de la UPV/EHU, UZEI y la empresa Hizkia de Baiona. El equipo de la Facultad de Informática ha desarrollado y coordinado el prototipo, UZEI le ha otorgado una garantía lingüística y Hizkia ha asumido la responsabilidad del producto comercial. Se han preparado versiones para Macintosh y PC. En este trabajo no se puede obviar la colaboración de: IVAP/IVAP, Departamento de Economía de la Diputación Foral de Gipuzkoa y Programa de Cooperación Euskadi/Aquitania.
Elh.- ¿Cuáles son las características de diseño del programa Xuxen?
I.A.- Debido a la complejidad morfológica del euskera, no se puede consultar una lista de palabras como se hace para otras lenguas para decidir si una palabra está bien o no, y se acabó; dado que las formas legítimas que se pueden crear a partir de un lema son muchas, la lista sería enorme. Por ejemplo, si partimos de un nombre, añadiendo un solo sufijo de declinación se pueden obtener 135 formas legales (si tenemos en cuenta las elipsis este número sube enormemente). Además, si se hubiera actuado de esta manera, en lugar de comprender toda su declinación introduciendo sólo el lema en el diccionario del usuario, al igual que sucede en Xuxen, el usuario debería introducir una a una todas las formas que corresponden a ese lema. Por todo lo anterior ha sido necesario realizar un análisis morfológico que permita identificar correctamente las palabras lícitas.
Fdo.- Comenta que el análisis morfológico ha sido fundamental, ¿qué pasos han dado para abordarlo?
I.A.- El análisis morfológico se basa en el formalismo a dos niveles propuesto por el profesor Koskenniemi de la Universidad de Helsinki en 1.983. Aunque este formalismo se propuso inicialmente para el suomés, ha sido un éxito para cualquier otra lengua y para lenguas anejas como el euskera. Las características principales de este formalismo son la separación clara entre las palabras que aparecen en los textos, el nivel superficial, y el léxico, el nivel léxico, que sirve para el análisis y la síntesis, y la distinción entre el programa y el descubrimiento lingüístico. La información lingüística está formada por léxicos morfemos y reglas morfofónicas.
El léxico cuenta con más de 60.000 entradas, almacenadas en una base de datos y distribuidas en 120 submuestras. A cada entrada se le asigna una clase de continuación que define el conjunto de sufijos que pueden venir detrás de ella. Las alteraciones superficiales en la recolección de morfemas se manifiestan en veinticuatro reglas morfo-fonológicas. Cada una de estas reglas indica cuándo se produce una inserción, eliminación o modificación de un carácter. Por ejemplo, en la regla octava se describe la siguiente modificación: la letra k del léxico se transforma en g de la portada si la letra k es un sufijo “ko”, y si el anterior es un lema acabado con n letras o un nombre de lugar terminado con l, m o n letras. Por ejemplo, al recoger los morfemas de, se crea la forma.
Con las palabras más utilizadas para aumentar la velocidad se ha elaborado una lista para evitar su análisis morfológico.
Fdo.- La propuesta de corrección es una de las opciones que ofrece el programa, ¿en qué consiste?

I.A.- Ante un error el usuario puede solicitar propuestas al programa. En este trabajo los errores tipográficos y ortográficos tienen un tratamiento diferente. En los tipográficos se considera como fuente del error la pérdida de un carácter, la inserción o la variación o el intercambio de dos caracteres continuos, buscando de forma inversa las palabras apropiadas para proponer.
Los errores provocados por el escaso conocimiento del euskera, la falta de conocimiento de los últimos cambios en la unidad o el uso dialectal se denominan ortográficos o típicos. Para su detección y corrección, Xuxen cuenta con una suela y unas reglas especiales. Por ejemplo, haundi está relacionado con la forma grande preferida en una forma léxica especial; al realizar el análisis de la “grande” se obtiene de haundi+, pero cuando haundi está marcado como error se hace grande y, por lo tanto, surge como propuesta una gran generación de grande+arena. Entre las reglas especiales se encuentran las que describen la pérdida de h y la variación de x-s. De este modo, al analizar en zuaitxe se obtiene automáticamente árbol + ko y con creación la propuesta de árbol.
Elh.- ¿Qué modelo lingüístico habéis utilizado?
I.A.- Teniendo en cuenta la flexión del euskera, se ha tenido que construir un sistema de declinación útil por ordenador. Para ello nos hemos basado en la tabla propuesta por Euskaltzaindia y la hemos adaptado a nuestro sistema, es decir, hemos tomado esta tabla y hemos agrupado los casos que se ajustan a cada categoría de léxico. Así, a cada base le corresponde un único sufijo, compuesto por los sufijos que puede tomar.
En la derivación hay algunos prefijos y sufijos trabajados, pero los más comunes son como entradas de diccionario. Sin embargo, el usuario puede introducir en su diccionario nuevas palabras derivadas. En la asociación de palabras se ha trabajado de momento lo más habitual y sistematizable según los criterios marcados por la Comisión LEF de Euskaltzaindia. El verbo factitivo también está tratado sistemáticamente
En cuanto al verbo, Xuxen conoce las formas tanto del verbo auxiliar como del macizo, siempre que Euskaltzaindia decida. Reconoce formas neutras, no marcadas o hitanas.
Si en el apartado de gramática la única fuente normativa ha sido la Real Academia de la Lengua Vasca-Euskaltzaindia, no es así cuando se empieza a trabajar el léxico. Las recomendaciones y decisiones en cada caso se han formulado en algunos puntos: Letra H, -a propia, composición y escritura de los números, etc. Estos son los que hemos seguido a la hora de completar el léxico, aunque en el caso de los números, por el momento, mantenemos ambas opciones (admitiendo veinticinco y veinticinco). Otro tanto ha ocurrido con los nombres de personas y lugares, así como en la escritura de los préstamos.
Para crear el vocabulario básico, es decir, la lista de lemas más frecuentes en cualquier léxico, hemos tenido que recurrir a otras fuentes actuales: Diccionario Vasco de Libre Elección de Ibon Sarasola, banco de datos Euskalterm de UZEI y base de datos lexicográfica EEBS, Xabier Kintana y otros Hiztegia 2000, J.M. Diccionario de Frecuencia y Disponibilidad de Etxebarria, etc. Cuando no se ajustaban a los criterios de Euskaltzaindia, las entradas se han “adaptado”, y en las que no han sido acordadas por Euskaltzaindia, el diccionario de Ibon Sarasola ha sido la fuente de criterios.
Para completar el vocabulario básico, desde el SEE de UZEI se han adoptado expresiones, locuciones y formas complejas. Las siglas y abreviaturas también se han trabajado según los criterios de UZEI. Partiendo del vocabulario común, en ocasiones ha sido necesario llegar a la terminología. Euskalterm ha sido imprescindible en estos casos.
Para completar la lista de nombres propios (aunque los nombres propios no proceden de diccionarios comunes) se ha recurrido a dos fuentes: la primera ha sido la lista de nombres vascos y de lugares propuestos por Euskaltzaindia, pero para obtener la lista de nombres de lugar del mundo se ha recurrido a Elhuyar.
A partir de todas estas fuentes hemos elaborado un vocabulario de gran tamaño que contiene al menos un léxico de textos comunes. Sin embargo, la terminología de los temas específicos será de libre inclusión en su vocabulario personal.
Elh.- ¿Qué miramos al futuro?
I.A.- En grupo queremos hacer frente al análisis sintáctico automático en los próximos años. De esta manera, XUXEN del futuro tendrá la oportunidad de realizar una corrección avanzada. Por otro lado, nuestro grupo trabaja también en la elaboración de diccionarios, con el objetivo de obtener un mayor rendimiento en la aplicación de recursos informáticos a los diccionarios. Sin embargo, en base al análisis morfológico, pretendemos extraer el lematizador automático EUSLEM dentro de un año.

Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










