



Corrector ortogràfic per al basc XUXEN
El mes de setembre passat va tenir lloc en el centre cultural Koldo Mitxelena de Donostia la presentació del corrector ortogràfic per al basc Xuxen. Vam tenir l'oportunitat de parlar amb calma sobre el que allí s'havia vist amb Iñaki Alegría, un dels autors. El resultat d'aquesta entrevista és el següent.
Elhuyar.- Què és el programa Xuxen?
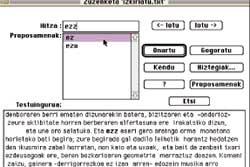
I. Alegria.- Corrector ortogràfic per a textos escrits en basc, Xuxen pretén detectar i corregir l'ortografia de textos en basc, és a dir, detectar i corregir errors tipogràfics i ortogràfics. Per a aquest objectiu el basc unificat és el que aprova el programa. Pot analitzar un o diversos documents en cada execució. Els documents es tracten literalment i mentre coneix les paraules continua treballant, però quan no coneix alguna paraula s'avisa i es deté. Davant el possible buit, l'usuari podrà acceptar, dirigir als usuaris, sol·licitar les propostes que ofereix el programa de correcció o, de nou, accedir al diccionari personal perquè reconegui totes les formes derivades d'aquest lema (veure figura 1).
Elh.- Quant temps heu trigat a completar el programa? i qui heu participat?
I.A.- L'elaboració del programa ha estat una gran labor principalment per dues raons: la pròpia complexitat morfològica del basc i la falta d'una descripció sistemàtica de la morfologia del basc.
Aprofitant l'analitzador morfològic automàtic realitzat anteriorment, aquest programa desenvolupat durant els últims tres anys ha estat fruit de la col·laboració entre la Facultat d'Informàtica de la UPV/EHU, UZEI i l'empresa Hizkia de Baiona. L'equip de la Facultat d'Informàtica ha desenvolupat i coordinat el prototip, UZEI li ha atorgat una garantia lingüística i Hizkia ha assumit la responsabilitat del producte comercial. S'han preparat versions per a Macintosh i PC. En aquest treball no es pot obviar la col·laboració de: IVAP/IVAP, Departament d'Economia de la Diputació Foral de Guipúscoa i Programa de Cooperació Euskadi/Aquitània.
Elh.- Quines són les característiques de disseny del programa Xuxen?
I.A.- A causa de la complexitat morfològica del basc, no es pot consultar una llista de paraules com es fa per a altres llengües per a decidir si una paraula està bé o no, i es va acabar; atès que les formes legítimes que es poden crear a partir d'un lema són moltes, la llista seria enorme. Per exemple, si partim d'un nom, afegint un sol sufix de declinació es poden obtenir 135 formes legals (si tenim en compte les el·lipsis aquest número puja enormement). A més, si s'hagués actuat d'aquesta manera, en lloc de comprendre tota la seva declinació introduint només el lema en el diccionari de l'usuari, igual que succeeix en Xuxen, l'usuari hauria d'introduir una a una totes les formes que corresponen a aquest lema. Per tot l'anterior ha estat necessari realitzar una anàlisi morfològica que permeti identificar correctament les paraules lícites.
Signat- Comenta que l'anàlisi morfològica ha estat fonamental, quins passos han donat per a abordar-lo?
I.A.- L'anàlisi morfològica es basa en el formalisme a dos nivells proposat pel professor Koskenniemi de la Universitat d'Hèlsinki en 1.983. Encara que aquest formalisme es va proposar inicialment per al suomés, ha estat un èxit per a qualsevol altra llengua i per a llengües annexes com el basc. Les característiques principals d'aquest formalisme són la separació clara entre les paraules que apareixen en els textos, el nivell superficial, i el lèxic, el nivell lèxic, que serveix per a l'anàlisi i la síntesi, i la distinció entre el programa i el descobriment lingüístic. La informació lingüística està formada per lèxics morfemos i regles morfofónicas.
El lèxic compta amb més de 60.000 entrades, emmagatzemades en una base de dades i distribuïdes en 120 submuestras. A cada entrada se li assigna una classe de continuació que defineix el conjunt de sufixos que poden venir darrere d'ella. Les alteracions superficials en la recol·lecció de morfemes es manifesten en vint-i-quatre regles morf-fonològiques. Cadascuna d'aquestes regles indica quan es produeix una inserció, eliminació o modificació d'un caràcter. Per exemple, en la regla vuitena es descriu la següent modificació: la lletra k del lèxic es transforma en g de la portada si la lletra k és un sufix “ko”, i si l'anterior és un lema acabat amb n lletres o un nom de lloc acabat amb l, m o n lletres. Per exemple, en recollir els morfemes de, es crea la forma.
Amb les paraules més utilitzades per a augmentar la velocitat s'ha elaborat una llista per a evitar la seva anàlisi morfològica.
Signat- La proposta de correcció és una de les opcions que ofereix el programa, en què consisteix?

I.A.- Davant un error l'usuari pot sol·licitar propostes al programa. En aquest treball els errors tipogràfics i ortogràfics tenen un tractament diferent. En els tipogràfics es considera com a font de l'error la pèrdua d'un caràcter, la inserció o la variació o l'intercanvi de dos caràcters continus, buscant de manera inversa les paraules apropiades per a proposar.
Els errors provocats per l'escàs coneixement del basc, la falta de coneixement dels últims canvis en la unitat o l'ús dialectal es denominen ortogràfics o típics. Per a la seva detecció i correcció, Xuxen compta amb una sola i unes regles especials. Per exemple, haundi està relacionat amb la forma gran preferida en una forma lèxica especial; en realitzar l'anàlisi de la “gran” s'obté d'haundi+, però quan haundi està marcat com a error es fa gran i, per tant, sorgeix com a proposta una gran generació de gran+sorra. Entre les regles especials es troben les que descriuen la pèrdua d'h i la variació de x-s. D'aquesta manera, en analitzar en zuaitxe s'obté automàticament arbre + ko i amb creació la proposta d'arbre.
Elh.- Quin model lingüístic heu utilitzat?
I.A.- Tenint en compte la flexió del basc, s'ha hagut de construir un sistema de declinació útil per ordinador. Per a això ens hem basat en la taula proposada per Euskaltzaindia i l'hem adaptat al nostre sistema, és a dir, hem pres aquesta taula i hem agrupat els casos que s'ajusten a cada categoria de lèxic. Així, a cada base li correspon un únic sufix, compost pels sufixos que pot prendre.
En la derivació hi ha alguns prefixos i sufixos treballats, però els més comuns són com a entrades de diccionari. No obstant això, l'usuari pot introduir en el seu diccionari noves paraules derivades. En l'associació de paraules s'ha treballat de moment el més habitual i sistematizable segons els criteris marcats per la Comissió LEF d'Euskaltzaindia. El verb factitiu també està tractat sistemàticament
Quant al verb, Xuxen coneix les formes tant del verb auxiliar com del massís, sempre que Euskaltzaindia decideixi. Reconeix formes neutres, no marcades o hitanas.
Si en l'apartat de gramàtica l'única font normativa ha estat la Reial Acadèmia de la Llengua Basca-Euskaltzaindia, no és així quan es comença a treballar el lèxic. Les recomanacions i decisions en cada cas s'han formulat en alguns punts: Lletra H, -a pròpia, composició i escriptura dels números, etc. Aquests són els que hem seguit a l'hora de completar el lèxic, encara que en el cas dels números, de moment, mantenim totes dues opcions (admetent vint-i-cinc i vint-i-cinc). Un altre punt ha ocorregut amb els noms de persones i llocs, així com en l'escriptura dels préstecs.
Per a crear el vocabulari bàsic, és a dir, la llista de lemes més freqüents en qualsevol lèxic, hem hagut de recórrer a altres fonts actuals: Diccionari Basc de Lliure Elecció d'Ibon Sarasola, banc de dades Euskalterm d'UZEI i base de dades lexicogràfica EEBS, Xabier Kintana i altres Hiztegia 2000, J.M. Diccionari de Freqüència i Disponibilitat d'Etxebarria, etc. Quan no s'ajustaven als criteris d'Euskaltzaindia, les entrades s'han “adaptat”, i en les quals no han estat acordades per Euskaltzaindia, el diccionari d'Ibon Sarasola ha estat la font de criteris.
Per a completar el vocabulari bàsic, des del SEE d'UZEI s'han adoptat expressions, locucions i formes complexes. Les sigles i abreviatures també s'han treballat segons els criteris d'UZEI. Partint del vocabulari comú, a vegades ha estat necessari arribar a la terminologia. Euskalterm ha estat imprescindible en aquests casos.
Per a completar la llista de noms propis (encara que els noms propis no procedeixen de diccionaris comuns) s'ha recorregut a dues fonts: la primera ha estat la llista de noms bascos i de llocs proposats per Euskaltzaindia, però per a obtenir la llista de noms de lloc del món s'ha recorregut a Elhuyar.
A partir de totes aquestes fonts hem elaborat un vocabulari de gran grandària que conté almenys un lèxic de textos comuns. No obstant això, la terminologia dels temes específics serà de lliure inclusió en el seu vocabulari personal.
Elh.- Què mirem al futur?
I.A.- En grup volem fer front a l'anàlisi sintàctica automàtica en els pròxims anys. D'aquesta manera, XUXEN del futur tindrà l'oportunitat de realitzar una correcció avançada. D'altra banda, el nostre grup treballa també en l'elaboració de diccionaris, amb l'objectiu d'obtenir un major rendiment en l'aplicació de recursos informàtics als diccionaris. No obstant això, sobre la base de l'anàlisi morfològica, pretenem extreure el lematizador automàtic EUSLEM dins d'un any.

Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










