MultiMeteo también sabe euskera

La calidad del trabajo del traductor humano será, sin duda, mejor y más rica, pero hoy en día es posible crear documentos en un campo concreto y técnico como es la meteorología, utilizando técnicas automáticas. En
este artículo presentamos el sistema interactivo Multimeteo que utiliza la creación textual multilingüe en el ámbito de la meteorología, así como la adaptación que hemos realizado a la creación en euskera. El sistema desarrollado ofrece pronósticos meteorológicos diarios en la siguiente dirección web: http://www.ingurumena.net/udala //www.inm.es/wwi/Multimeteo/Multimeteo.html
Antecedentes

Aunque no se utiliza la creación automática de textos, hay que mencionar aquí un sistema que traduce automáticamente las predicciones meteorológicas. El sistema METEO creado por el grupo TAUM de Montreal ha sido el sistema de traducción más exitoso de todos los tiempos. Era difícil encontrar traductores para traducciones aburridas que se parecían a diario, y el servicio meteorológico oficial de Canadá comenzó a investigar las vías automáticas. El sistema METEO obtenido ha estado traduciendo boletines meteorológicos del inglés al francés desde 1977, y el 80% de su traducción es totalmente directa. Sin embargo, el éxito de la meteorología no se ha extendido, ya que aunque el sistema se ha adaptado a otras cuestiones, no se han obtenido resultados de igual calidad. Parece que el ámbito de las predicciones meteorológicas tiene una especial adecuación a este tipo de procesos automáticos.
El entorno de trabajo Forecast Generator (FoG) también se puso en marcha en Canadá en 1993. En este sistema, el meteorólogo utiliza un editor gráfico para adaptar el mapa que muestra los datos meteorológicos y posteriormente el sistema genera automáticamente la predicción meteorológica en inglés y francés para la región.
Historia del sistema multiMeteo
HGMTN tWWiWpWeWtToTopToeVvpVeVtTeDT eHDFFtHNEn 1995 el Servicio Meteorológico Francés (Meteo France) impulsó el proyecto MultiMeteo para la publicación de las previsiones meteorológicas en varios idiomas. Para ello se puso en contacto con el Instituto Nacional de Meteorología (INM) de España, el Royal Meteorological Institute (RMI) de Bélgica, el Zentralanstallt für Meteorologie und Geodynamik de Austria (ZAMG) y dos empresas especializadas en la creación lingüística: Lexiquest, con sede en París, y CL Servicios Lingüísticos de Madrid. El servicio de meteorología alemán (DWD) también se unió inicialmente, pero fue abandonado posteriormente.
Estas asociaciones presentaron el proyecto denominado “Multilingual Production of Weather Forecasts” y obtuvieron financiación comunitaria. El sistema se desarrolló en cuatro idiomas: francés, inglés, castellano y alemán. Los resultados de la evaluación realizada en febrero de 1999 fueron muy positivos.
En el año 2000 INM y Lexiquest alcanzaron un acuerdo para extender el sistema a cuatro lenguas más: el holandés, el catalán, el gallego y el euskera. El Grupo Ixa y el Centro de Terminología UZEI de la Facultad de Informática de San Sebastián nos hemos encargado de la difusión al euskera, y en este momento estamos a punto de finalizar la fase de desarrollo del proyecto.
Procedimiento habitual de creación de predicciones meteorológicas

Para la recogida de datos meteorológicos se utilizan dos fuentes: la recogida superficial de datos y la recogida espacial. Los datos superficiales se toman en los observatorios meteorológicos, en los que se miden y recogen en todo momento las variables físicas que describen el estado de la atmósfera. Otros datos que se obtienen del espacio son los satélites meteorológicos, los satélites geoestacionarios METEOSAT y los satélites polares de la serie TIROS-NOAA, que no para de enviar información.
Todos los datos numéricos obtenidos se procesan mediante complejos modelos matemáticos. Los procesos automáticos simulan la evolución de las variables físicas en los próximos días, generando matrices de datos para predicciones meteorológicas. El meteorólogo tiene entonces la oportunidad de retocar estas matrices de datos, es decir, de completar y redondear la previsión con su experiencia. Como conclusión, tal y como se observa en la Tabla 1, las matrices presentan datos de temperatura (Te), dirección del viento (DD) y fuerza (FF), nubes, lluvia, etc. para diferentes horas (periodos de 3 horas en el caso del sistema del INM). Para cada punto del mapa se obtiene una matriz de este tipo.
Con estos datos los meteorólogos crean las predicciones meteorológicas manualmente. Este trabajo resulta muy largo y costoso, sobre todo cuando de una sola predicción hay que hacer varias versiones en diferentes idiomas o estilos (predicciones generales, de playas, de mar, de montaña, por comunidad, por provincia...).
Ahí está el interés de MultiMeteo. No se trata de sustituir la obra de los meteorólogos, sino de contribuir de manera interactiva a sus tareas, de manera que se puedan difundir las predicciones en diferentes idiomas y estilos. Además, permite realizar predicciones para diferentes lugares del mapa.
Una herramienta de apoyo: creación multilingüe interactiva

Esta técnica, en primer lugar, mediante la creación automática, genera un borrador a partir de datos de entrada quizá incompletos. Aunque tiene la capacidad de crear texto en varios idiomas, al meteorólogo, para actuar como corrector, se le ofrece únicamente en su lengua materna. Si el meteorólogo desea realizar una corrección en un fragmento de texto, deberá hacer clic en la parte que desee modificar. A continuación, el menú “pop-up” le ofrecerá una serie de opciones y modificadores alternativos, eligiendo uno de ellos para realizar la corrección de forma cómoda. Teniendo en cuenta los cambios realizados, el sistema generará textos predictivos en todos los idiomas.
Las ventajas de esta técnica son la rapidez (para producir cada texto en cada idioma se necesitan unos 2 segundos; un traductor humano necesita unos 10 minutos); la viabilidad de la creación, aunque algún dato no se haya recogido todavía, la alta calidad de los textos creados (a veces con toques humanos); la facilidad de mantenimiento y adaptación; y por último, la aceptación por parte de los usuarios humanos (a los meteorólogos no les quitará el puesto de trabajo, sino que les ayudará a escribir en lenguas extrañas).
Creación automática de boletines
MultiMeteo realiza la creación de dos formas:
- Para la redacción del título de cada párrafo se utiliza un texto fijo con el nombre de las provincias, y para escribir el encabezado de los boletines (ver figura 1) se utiliza una plantilla con varias variables internas, por ejemplo:
Predicción meteorológica *IS *CO. *MO *FD.
Hora Local: *FP.
Valor del anuncio: *TT.
donde:
- El valor de IS puede ser "por provincias", "por islas" o nada.
- Valor del CO - nombre de las comunidades (por ejemplo, para la "Comunidad Autónoma de Galicia").
- Mes MO ("Junio")
- Fecha de la DF, expresada en cifras.
- FP indica hora
- Periodo de predicción por TT (por ejemplo, “hoy de 06:00 a 12:00 de la medianoche”).
- Para escribir el cuerpo de los párrafos se utiliza un método mucho más complejo. En los siguientes puntos se explica la arquitectura y los módulos necesarios para abordar la creación automática a este nivel.
Arquitectura general del sistema

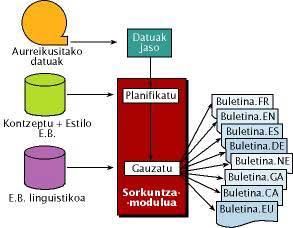
El motor de generación utilizado por el sistema se desarrolló en 1994 en francés para la generación automática de cartas comerciales. En 1995 se extendió al inglés integrándose en un prototipo de traducción de manuales técnicos. Y el mismo año también se integró en el proyecto “Multilingual Production of Weather Forecasts” para incorporar nuevos lenguajes y funcionalidades en la creación de boletines meteorológicos (creación interactiva y gestión de conocimientos estilísticos).
La arquitectura del sistema se puede ver en la figura 2. La primera fase consiste en la obtención y reformateo de una base de datos meteorológicos que permita la utilización de módulos de generación. Posteriormente, la tarea del módulo de creación se divide en dos partes: planificar y ejecutar.
Módulo de planificación
La planificación utiliza bases de conocimiento de conceptos y estilos (UE) y se divide en dos fases:
- Planificación general: el boletín se organiza en varios párrafos (cabecera, párrafo para cada provincia, etc.)
- Planificación meteorológica: a partir de los datos de entrada se determina el contenido de cada párrafo. Los eventos ( event ) que deben aparecer en el párrafo y las relaciones entre ellos se recogen en una lista utilizando un interlingua, de forma que la descripción sea independiente de los idiomas. Los siguientes módulos se realizarán para cada idioma.
El suceso es un objeto conceptual asociado a la situación meteorológica o evolución de la situación. Los fenómenos son de dos tipos: atómicos y moleculares.
El suceso atómico representa un parámetro meteorológico sin evolución, con un único valor asociado ( atributo Value). Por ejemplo, el suceso atómico que representa el cielo cubierto es:
Event_CloudCovering4: Event{} Value=Class
CloudCovering_code4; Time_Representation=
TimeRepresentationMod{};}
Class CloudCovering_code4 es un conjunto de conceptos simples: Overcast, NoSun y VeryCloudy-Overcast. Cada uno de estos conceptos está asociado a un término en cada lengua.
El suceso molecular indica más de un parámetro. Por ejemplo, cuando hablamos de viento podemos tener fuerza, dirección y datos de evolución. Pueden llevar varios valores ( Value0 , Value1 , etc. atributos), así como un operador (atributo Operator) que especifica la forma de recoger estos valores. Por ejemplo, el suceso molecular para describir el cielo sin nubes a estar cubierto es:
GrowingCloudier_Min0: Event_mol{ Value0=Event_CloudCovering0; Value1=
Event_CloudCovering4;
Operator= Class
GrowingCloudier_Min0; Time_Representation=
TimeRepresentationMod{};}
Este suceso molecular se manifiesta mediante dos episodios atómicos y un operador. Sirve para situar los eventos time - representation en el tiempo (presente, pasado o futuro) e indica el periodo (día, mañana, tarde, noche...).
A la salida del módulo de planificación se selecciona un concepto para cada evento atómico y para cada clase de atributo Operator de los eventos moleculares. Además, se pueden añadir otros atributos (automáticamente o en interacción con el meteorólogo): índice de probabilidad, fase, periodo...
Módulo de ejecución
simple
semántica ( Rsem )
UsemR1_INVIERNO= Estali1Sem
Usem = Estali1Sem
El módulo para materializar lingüísticamente los conceptos obtenidos en cada lengua está basado en la Teoría del Significado - Texto (Mel’cuk 1988, Polguère 1988). En esta fase se utiliza una base de conocimiento lingüística que se divide en cinco etapas: predenotación, semántica, sintaxis profunda, sintaxis superficial y morfología.
- Predenotación. En esta etapa se selecciona para cada concepto simple derivado de la planificación un término correspondiente a ese idioma. Por ejemplo, para el concepto simple Overcast del grupo Class CloudCovering_code4 anteriormente mencionado se seleccionará uno de los términos Cielo, Cubierto o Cubierto. Estos términos se dividen en unidades semánticas ( USem ), con las que se crea la expresión semántica ( RS ) (ver ).
- Semántica. De la expresión semántica Rsem se forma el grafo de la sintaxis profunda formada por nodos y relaciones, para lo que se selecciona la unidad lexical correspondiente a cada unidad semántica.
- Sintaxis profunda. Se construye un grafo que tiene todas las palabras de la frase a crear en los nodos.
- Sintaxis cutánea. Se ordenan los nodos para determinar el lugar que debe ocupar cada palabra en la frase.
- Morfología. La forma de palabra que le corresponde según la información morfosintáctica de cada nodo se recoge del diccionario. En el diccionario se almacenan todas las formas declinadas para evitar la creación morfológica.
Adaptación al euskera
diurna
•
•
El trabajo computacional para la difusión del sistema MultiMeteo al euskera ha sido desarrollado por el grupo IXA y el trabajo terminológico ha sido realizado por UZEI. Las adaptaciones al gallego y catalán se han realizado a partir de la versión castellana, y han tenido que trabajar sobre todo el léxico, ya que no se requería grandes cambios en sintaxis y morfología. Para el euskara, aunque hemos partido del castellano (y en ocasiones del francés), la mayoría de las estructuras de las frases han sido modificadas y hemos tenido que trabajar especialmente con marcas de declinación morfológica.
Comenzamos nuestro trabajo en tres fases:
- recogida y análisis del corpus del tiempo en euskera,
- Conocimiento del sistema multiMeteo y su arquitectura, y
- adaptación del sistema.
La adaptación la realizamos en tres subfases: primero abordamos los sucesos atómicos (por ejemplo, el “cielo, cubierto”), luego los sucesos moleculares que eran fáciles (por ejemplo, el “viento, débil, del norte”), y finalmente, los sucesos moleculares que presentaban especiales dificultades (por ejemplo, el cielo, inicialmente cubierto, con lluvia, posteriormente muy cubierto temporalmente).

En cada una de las fases de adaptación se realizó un análisis lingüístico previo, un análisis y diseño de la información a incluir en la base de conocimiento, una introducción y prueba de la información de un ejemplo representativo para cada evento y, finalmente, una introducción y prueba de todas las posibilidades para cada tipo de evento.
Las principales características de esta adaptación son:
- Teniendo en cuenta que las predicciones generadas por el sistema debían seguir el estilo telegráfico del INM, decidimos eliminar los verbos. Asimismo, los modificadores del nombre que es el área de la frase irán separados por comas como sintagma de atributos. Por ejemplo, en lugar de dar “Viento del Norte débil” o “Viento del Norte y Débil”, el sistema generará “Viento del Norte, débil”.
- Las evoluciones meteorológicas expresadas en francés y castellano por gerundio se realizan de otra manera en euskera. Por ejemplo, "Cielo despejado en aumento a nuboso" lo crearemos en euskera de la siguiente manera: “El cielo, al principio oscarbio, después nublado”.
- En el diccionario hemos escrito todas las formas de palabras (a veces unidades multi-palabra) que se pueden utilizar en los boletines. En los boletines se utilizan por momentos dos casos: absoluto y sociativo. El lema de la palabra es también posible.
Si posteriormente se quisiera ampliar el sistema con otros estilos, se deberían utilizar más casos de declinación, por lo que habría que introducir estos casos en el diccionario. Veamos, por ejemplo, la introducción del vocabulario de la palabra lluvia:
BA_Euri1 :LexemeNomBA{
CatMorph = NOM; SsCatMorph = COMMUN; UMorph=
[ morpho{Cas= ABS;
Nombre= SINGULIER;UMG= "euria"},
morpho}=
Phuns;
- La zona de la frase, por defecto, tendrá el caso de la declinación absoluta, y el caso de los modificadores de la zona se determinará en la definición del concepto o término. Por ejemplo, el concepto que crea "El cielo, cubierto, con lluvia" debe precisar que el término cubrir ocupará el absolutivo singular y la lluvia sociativa singular. En el absolutivo singular aparece el término zeru porque es el espacio de la oración.
- En euskera, el caso de declinación del sintagma se adhiere a la última palabra de cada sintagma, y el sistema no daba la oportunidad de gestionarlo de manera elegante. Por ello, hemos tenido que añadir una serie de reglas: por un lado, a nivel conceptual, el sistema pega la marca de caso a todas las palabras de cada sintagma, y luego cuando se ordenan las palabras en la etapa de sintaxis superficial, quita el caso a las que no son la última palabra. Por ejemplo, para crear la frase “El cielo, cubierto, con lluvias generales y tormentas”, se indica en un concepto que todo el sintagma de lluvia general y tormentas debe llevar el caso de lo sociativo; para ello hay que marcar todos los términos con el caso lluvia (soz)+general(soz)+ekaitz(soz) ; para que más tarde los términos lluvia, y general se desmarquen con «precediendo».
En la tabla 3 se puede observar cómo se han materializado varios conceptos atómicos en euskera (se incluye la realización en castellano y francés de referencia).
En la Tabla 4 se puede observar la ejecución de varios conceptos moleculares. Las variables indican, cuando se indican, los valores de este suceso: Variables N estado de las nubes (oscarbia, bajo nube, cubierto...); Variables DD dirección del viento (norte, suroeste, etc.); Las variables FF son la fuerza del viento (moderada, fuerte,...); Variables TS precipitaciones (lluvia, sirimiri...), Periodo PER (mañanas...)...
Obras de futuro
tormentas con granizo
Reduciendo a N2
Creciente/ Disminución N2
tormentas a N2
FF2 Avancez
pasajero FF2
El proyecto se encuentra actualmente en las últimas fases de desarrollo. El siguiente paso es una prueba masiva para analizar posibles errores en el sistema. A continuación realizar los cambios necesarios y la evaluación final. Sin embargo, la adaptación realizada está ya integrada en el sistema del INM y cada día se ofrecen las previsiones meteorológicas de las comunidades del estado español en la web http://www.inm.es/wwi/ MultiMeteo/Multimeteo.html.
Además de la escritura telegráfica del objetivo general, la realización de predicciones de propósito especial (para playas, montañeros, esquiadores...) y la elaboración de escrituras más ricas (por ejemplo, la introducción de verbos con frases completas) serían pasos factibles a medio plazo. Este tipo de versiones completas se han realizado en francés y se utilizan en la actualidad. De momento bastaría con analizar la utilidad del sistema desarrollado para el euskera, y si posteriormente se detectara la necesidad, entonces habría que abordar la organización de las mejoras mencionadas.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian