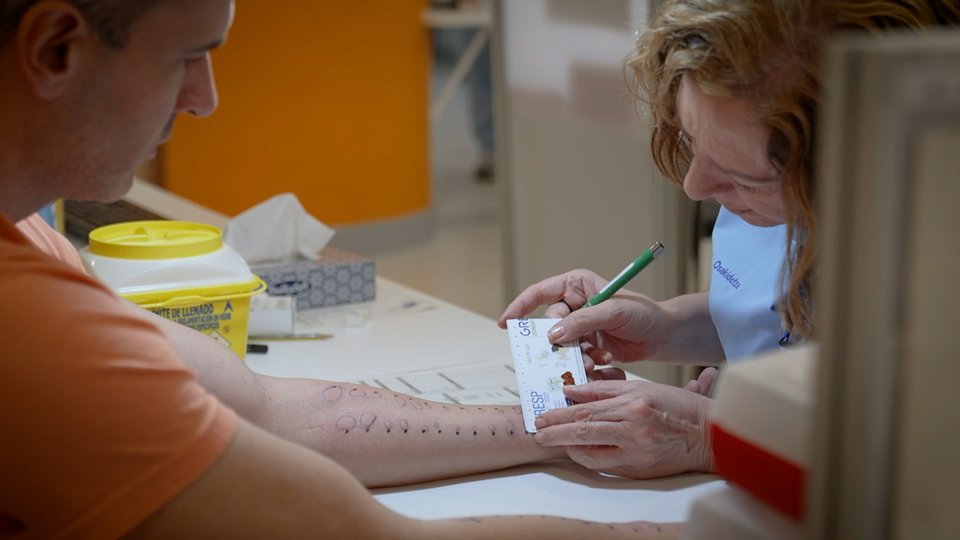
Ressources linguistiques sur Internet
Les programmes qui effectuent le traitement du langage par ordinateur sont de plus en plus nombreux. La communication avec les ordinateurs à travers les langues naturelles (en basque dans notre cas) sera de plus en plus fréquente. D'autre part, l'ordinateur devient une personne spéciale pour pallier les déplacements de cette société multilingue entre les langues.
En outre, l'énorme avancée éprouvée dans les télécommunications (surtout les phénomènes Internet) a augmenté la nécessité d'un traitement automatique du langage. En fait, grâce au réseau, vous pouvez obtenir beaucoup d'informations, mais il n'est pas facile de trouver cette donnée concrète dont nous avons besoin. Dans ce travail, le traitement linguistique n'est qu'auxiliaire.
Le champ de recherche sur le traitement automatique du langage est appelé Traitement du langage naturel (LNP). Toute une nouvelle industrie est créée autour de la langue, dont le but est de traiter le langage à travers l'ordinateur. On parle déjà de technologie linguistique, d'ingénierie linguistique. Ses principaux domaines d'application sont quatre: i) Édition de textes ou gestion textuelle (correcteurs orthographiques et stylistiques, aides à la création et utilisation de textes multilingues, consultations de dictionnaires, ...); ii) Traitement et gestion de grandes masses de texte (recherche de concepts, classification documentaire, extraction d'information et création automatique de textes); iii) Traduction automatique ou traduction assistée, et iv) Connaissance.
Dans le groupe IXA, nous avons travaillé pendant dix ans dans ce domaine, toujours du point de vue de l'euskera. En ajoutant les membres de la Faculté d'Informatique de Donostia de l'UPV-EHU et ceux de l'UZEI nous sommes un total de 21 personnes. Notre stratégie n'a jamais été de faire un système très complexe, par exemple, faire un système de traduction. Nous avons préféré commencer par des objectifs simples mais fondamentaux, comme la morphologie, comprise comme un problème trop simple pour d'autres langues, et construire sur ce chemin des bases linguistiques larges et solides.
Plus tard, nous avons entrepris des projets plus complexes comme la lemmatisation, la syntaxe ou l'utilisation de dictionnaires, mais travailler sur une large base construite précédemment nous permet d'économiser du temps et de cohérence sur de nouveaux produits. Étant donné que nos ressources linguistiques peuvent également être utiles à d’autres collectifs, nous avons décidé de diffuser l’“exposition électronique”, qui est l’objectif du projet que nous présentons dans cet article. Le projet a été approuvé lors de la convocation de 1997 de projets de recherche Université-Entreprise du Gouvernement Basque (référence UE97/8) et se déroulera durant les années 1998-99.
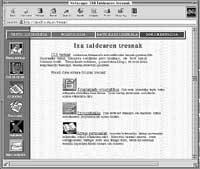
Les ressources que nous voulons localiser sur Internet à moyen terme sont la base de données lexicale, le correcteur orthographique, l'analyseur morphologique, le lematizateur et l'analyseur syntaxique. Mais dans cette première étape, seules les trois premières apparaîtront. Le projet est en cours et des tests peuvent déjà être effectués avec un correcteur orthographique dans l'adresse http://ixa.si.ehu.es/tresna (voir les écrans d'ordinateur qui apparaissent dans ce même article ou les voir directement sur votre ordinateur).
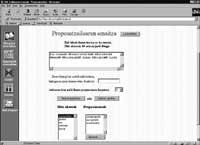
Essayez d'entrer vos mots inconnus dans votre vocabulaire personnel et vérifiez qu'à partir de là vous connaîtrez également d'autres formes de déclinaison de ces mots.
Enfin, nous expliquerons ce qu'est la Base de Données Lexical de l'Euskera (EDBL) qui est mentionnée au nom du projet. La base de données lexicale est un grand entrepôt lexical. Il s'agit d'une sorte de dictionnaire électronique, conçu pour le traitement automatique de la langue et donc organisé en tenant compte des exigences de cet objectif d'automatiser le traitement de la langue. Cela exige, bien sûr, que l'organisation du lexique se réalise en tenant compte de l'utilisation qui sera faite ultérieurement, et une systématisation de la description lexicale : utilisation d'un système de catégories de revenus unifié et homogène, définition des caractéristiques nécessaires pour décrire correctement les éléments de chaque catégorie, etc.
Dans le cas de l'euskera, le besoin de ce type d'entrepôt lexique a surgi quand nous avons commencé la préparation du correcteur orthographique Xuxen dans le groupe IXA. Comme mentionné précédemment, ce correcteur était plus fondamental pour nous comme sous-produit de l'analyseur morphologique, et nous ne voulions pas non plus organiser la base de données lexicale comme un dictionnaire ou une simple liste de mots pour ce correcteur, mais comme base lexicale solide pour tout autre outil ou application dans le domaine du traitement automatique de l'euskera à l'avenir. C'est ainsi que naquit l'EDBL, la Base de Données Lexical de l'Euskera, qui depuis a été la base lexicale pour nos travaux, qui a été constamment mise à jour, et qui aujourd'hui ou demain ouvrira ses portes à une communauté plus large, afin que les bases soient également exploitées par d'autres.
Lors de la conception de la base de données, il a été donné une grande importance, donc, d'être suffisamment flexible pour accepter d'éventuelles extensions futures et, en particulier, de décrire de la manière la plus neutre possible l'information linguistique contenue dans le même, à savoir, de la manière la plus indépendante possible des formalismes ou des théories linguistiques.
EDBL regroupe actuellement environ 70.000 entrées, classées en trois grands points : entrées de dictionnaire (noms, adjectifs, verbes, etc.) ). ), verbes (formes verbales jouées) et morphèmes non indépendants (suffixes, préfixes, etc. ).
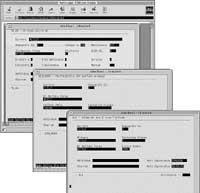
Les caractéristiques ou attributs prédéfinis de chaque catégorie d'entrée sont enregistrés, décrivant dans tous les cas, comme déjà mentionné ci-dessus, la morphologie d'entrée (information morphotactique) par un formalisme à deux niveaux largement utilisé dans la morphologie de calcul.
Actuellement l'EDBL est sous un système commercial de gestion de bases de données qui offre au linguiste les facilités habituelles dans ce type de systèmes, puisque les linguistes sont ses principaux utilisateurs : une interface agréable pour le travail, des facilités pour maintenir l'information à jour et garantir sa consistance, des possibilités de filtrer adéquatement l'information pour les applications nécessaires, etc. La base de données est également devenue un outil indispensable pour maintenir à jour les derniers événements survenus dans le processus d'unification de l'euskera, en particulier les décisions d'Euskaltzaindia, et l'une des tâches importantes à accomplir dans le futur EDBL peut être l'outil qui rend compte des dernières décisions.
- Titre du projet: Environnement d'utilisation publique de la Base de Données Lexical de l'Euskera (EDBL).
- Objectif du projet: Diffusion sur Internet de l'utilisation de certains produits du groupe IXA pour leur incorporation au basque.
- Directeur: Xabier Artola Zubillaga.
- Équipe de travail: Groupe IXA E. Agirre, I. Aldezabal, I. Alegria, O. Ansa, X. Arregi, J.M. Arriola, X. Artola, A. Diaz de Ilrace, N. Ezeiza, K. Gojenola,J.M. Intxausti, M. Lersundi, A. Maritxal,M. Maritxalar, M. Oronoz, K. Sarasola, A. Soroa, R. Uriser et M. Bouleau.
- Département: Langages et systèmes informatiques
- Centre: Informatique de l'UPV-EHU (Saint-Sébastien)
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian