



Creación automática de contrnarrativas en eúscaro e castelán
Nos últimos anos incrementouse a presenza do discurso de odio (GD) nos medios de comunicación a través da anonimización que xeran as redes sociais. O GD definiuse como “a linguaxe utilizada para expresar o odio contra un grupo determinado”, “a linguaxe que pretende insultar, humillar ou menosprezar aos seus membros”[1].
Na actualidade, as redes sociais actualizan continuamente as súas políticas para facer fronte ás mensaxes de odio, bloqueando ou eliminando mensaxes. Para aliviar a carga de traballo que iso implica, a detección automática de GD ten interese no desenvolvemento de conxuntos de datos[2] e no uso de técnicas de aprendizaxe automática e profunda[1]. Con todo, estes métodos de moderación do GD crearon controversia, xa que moitos argumentan que poden limitar a liberdade de expresión[3]. Como alternativa, propuxéronse contra-narrativas (KN) como medidas eficaces para facer fronte e paliar a expansión do GD. O KN é dar unha resposta non agresiva a un comentario de odio con feedback non negativo baseado en argumentos e feitos[3]. Na figura 1 pódese ver un exemplo.

Neste contexto, a investigación ao redor da xeración automática de KN creceu de forma notable nos últimos anos. Este estudo abórdao, analizando esta tarefa por primeira vez en eúscaro e castelán, utilizando diversos recursos e métodos.
Creación automática de contrnarrativas
A investigación sobre KN aumentou considerablemente nos últimos anos, pero hai unha dificultade que dificulta a investigación: a escaseza de datos. Precisamente co propósito de facer fronte a este reto nace CONAN, o conxunto de datos que se tomaron como base para esta investigación. Chung e os seus compañeiros reuniron en tres idiomas a parellas de GD-KN ao redor da islamofobia. A través dela, obtiveron un corpus sólido de parellas GD-KN, non transitorio, baseado en expertos e multilingüe. Mediante o método Nichesourcing contratouse persoal experto na materia para a recollida de datos, priorizando a calidade do CN e recollendo datos non estereotipados e variados. Este método tarda moito e é caro, polo que levou a cabo un proceso para aumentar a cantidade de datos: tres non expertos crearon dous parafrasias de cada KN orixinal e as parellas GD-KN orixinais foron traducidas ao inglés. Deste xeito, un total de 6654 parellas de GD-KN foron definitivamente agrupadas na parte do corpus en inglés.
A pesar de que este conxunto de datos abarca varias linguas, cabe destacar que os traballos sobre a creación automática de KN desenvolvéronse principalmente en inglés, debido á escaseza de datos recolleitos a man e á escaseza de modelos lingüísticos xeradores. Sabemos que se publicaron poucos traballos sobre a creación de KNs en linguas distintas ao inglés.
Recollida de datos en eúscaro e castelán
Por tanto, non é de estrañar que neste campo onde a maioría dos traballos realizáronse en inglés non fagan nada en eúscaro e castelán. Este baleiro levounos a crear CONAN-EUS, o primeiro conxunto de datos paralelo en eúscaro e castelán que serve para a creación automática de KN.
Para iso, as 6654 GD-KN do corpus en inglés CONAN foron traducidas automaticamente ao eúscaro e ao castelán a través de Google API. Posteriormente, estes datos traducidos automaticamente en castelán e eúscaro foron posteditados por 3 tradutores profesionais. Decidiuse realizar unha postedición manual, aínda que custosa, porque era máis rápido e máis fácil que construír un recurso desde cero. Ademais, dispor dun conxunto de datos paralelo con CONAN en inglés orixinal permite realizar investigacións innovadoras utilizando métodos de transferencia multilingüe e e interlingüística.
Neste estudo, utilizamos CONAN-EUS para crear automaticamente KNs utilizando datos traducidos automaticamente, pero tamén mediante datos posteditados. Desta maneira, o noso obxectivo é contrastar as contranarrativas xeradas coa tradución automática e os datos posteditados, para analizar o impacto da postedición nos KN xerados de forma automática.
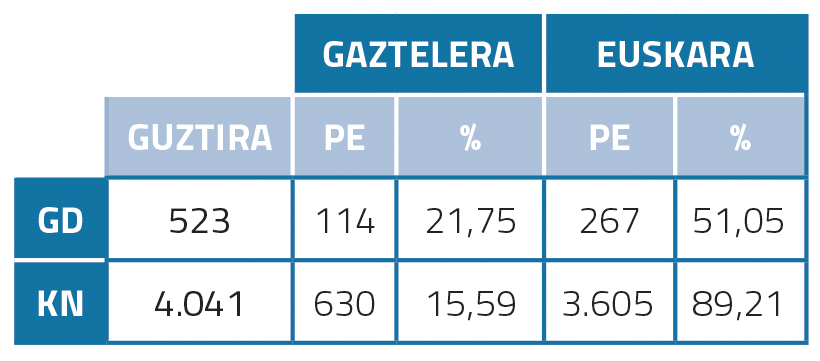
Postedición en eúscaro e castelán
Se nos fixamos nas estatísticas de postedición do eúscaro (táboa 1), vemos que a porcentaxe é moi alto: 51,05% no caso de GD, 89,21% no caso de KN. Trátase da hipótese de que isto pode deberse á mala calidade da tradución automática. Ademais, houbo que posteditar máis KN que GD, probablemente porque os KN en xeral son máis longos e complexos e por tanto necesitaron máis postediciones. En castelán, pola contra, as porcentaxes posteditados por GD e KN son moito máis baixos que os importes en eúscaro: 21,75% e 15,59%. Isto pode ser debido a que a calidade da tradución automática entre o inglés e o español é maior.
Como crear e avaliar automaticamente o texto?
Neste estudo utilizouse o modelo lingüístico plurilingüe mT5[7] de tipo transformador para a creación automática de KNs. A arquitectura deste tipo de modelos pódese ver na figura 2. Estes modelos foron adestrados cunha parte do noso conxunto de datos, de maneira que na parte non visible póidase crear automaticamente un KN para cada ED.
Para avaliar a calidade dos KN xerados, utilizamos tres métricas automáticas: BLEU (medición da correlación dos n-gramas entre os textos de entrada e saída), Rouge-L (cálculo da Ecuación de W.C. máis longa entre a referencia e o texto de saída) e Repetition Rate (RR, cálculo dos n-grams que se repiten no texto xerado).
Influencia da postedición nos resultados da creación
Comezando con modelos monolingües, o resultado máis destacado é que a postedición dos datos traducidos automaticamente mellora a creación de KN tanto en eúscaro como en castelán (Táboa 2). Ademais, a pesar de que os é-PEN logran mellores resultados en BLEU e ROUGE-L, os resultados de RR son mellores con datos en inglés (7,79 en castelán e 5,73 en inglés). Isto indícanos que os altos resultados obtidos nas métricas de superposición do n-grama en castelán puideron ser xerados polas repeticións. En canto aos resultados en eúscaro, aínda que os resultados de eu-PE son mellores que os de eu-MT, son notablemente inferiores aos de inglés e castelán. A nosa hipótese é que o eúscaro non está tan presente como o inglés ou o castelán no dicionario do modelo mT5.
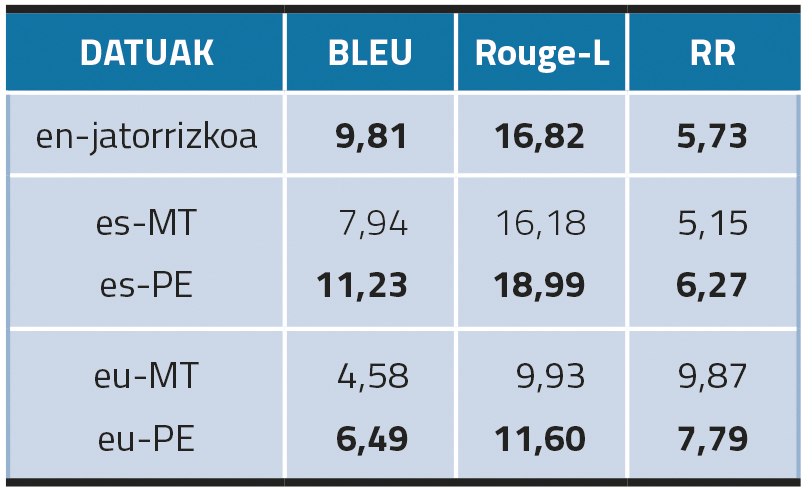
En resumo, os resultados da avaliación automática mostran que nestes experimentos con modelos monolingües (é dicir, refinados con conxuntos de datos traducidos ao idioma de destino) é necesario un paso de postedición para obter resultados óptimos, xa que os modelos requintados con datos traducidos automaticamente non alcanzan o mesmo nivel de rendemento.
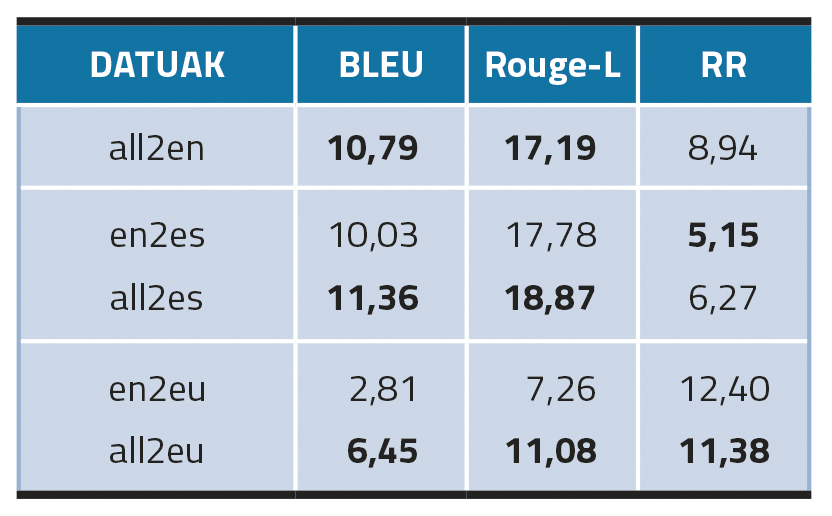
En modelos plurilingües, no caso do inglés e o castelán (all2en e all2es) hase visto que afinar nos tres idiomas deu mellores resultados, sobre todo no caso do inglés. Con todo, isto non ocorre no caso do eúscaro (all2eu), o que pode suxerir que a ampliación de datos multilingües pode funcionar mellor en linguas estruturalmente similares, no noso caso o inglés e o castelán.
En canto á contorna de transferencia interlingüística, este método (en2es) funcionou ben en castelán, xa que superou os resultados dos modelos monolingües (é-MT). En eúscaro, con todo, a transferencia de modelos interlingüísticos (en2eu) falla completamente e quedouse moi por baixo de eu-MT.
Avaliación manual
Un problema na xeración de KN é a fiabilidade das métricas automáticas. Por iso, realizamos unha avaliación manual para analizar a fiabilidade dos nosos resultados.
Para iso, analizáronse cinco criterios: a relación (DG e KN están relacionados), a especificidad (o KN é xeral ou específico), a riqueza (en canto ao idioma, a riqueza que ten), a coherencia (as frases teñen sentido común) e a gramaticalidad (corrección gramatical das frases). Neste traballo traballaron dous lingüistas que tiñan como lingua materna o eúscaro ou o castelán.
Así, nos modelos monolingües observamos que existe unha correlación entre as métricas automáticas e manuais: en eúscaro e castelán, a avaliación manual tamén prioriza os resultados dos datos posteditados. Isto indícanos que, para o noso caso, estas métricas automáticas son fiables.
Conclusións
O conxunto de datos CONAN-EUS é un novo conxunto paralelo de datos para a creación de KN-EUS en eúscaro e castelán, creado a través da tradución automática e a postedición da parella GD-KN en inglés orixinal. Este recurso permitiu realizar investigacións innovadoras desde unha perspectiva multilingüe e interlingüística no campo da creación de KNs.
Os experimentos demostraron que a xeración de KN é mellor se o modelo se refina con datos posteditados, en lugar de con datos traducidos automaticamente. Ademais, os deficientes resultados obtidos nos experimentos interlingüísticos en eúscaro incidiron na importancia de dispor de datos de adestramento na lingua de destino, sobre todo nas linguas de menos recursos como o eúscaro. Con todo, o método de transferencia interlingüística segue sendo un problema aberto e complexo de indagación nos modelos creativos, o que deixa aberta a liña de traballo para o futuro.
Bibliografía
1] Davidson, T., Warmsley, D. Macy, M.W. e Weber, I. 2017. “Automated Hate Speech Detection and the Problem of Offensive Language”. International Conference on Web and Social Media.
[2] Basile, V. Bosco, C., Fersini, E. Noción, D., Patti, V. Pardo, F.M., Rosso, P. E Sanguinetti, M. 2019. “SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Etorkants and Women in Twitter”. International Workshop on Semantic Evaluation.
3) Schieb, C., e Preuss, M. 2016. “Governing hate speech by means of counterspeech on Facebook”. 66th ica annual conference, 1-23.
[4] Benesch, S. 2014. “Countering dangerous speech: New ideas for genocide prevention”. SSRN 3686876.
5] Chung, E., Kuzmenko, E. Tekirocarriles, S.S., e Guerini, M. 2019. “CONAN - COunter NArratives through nichesourcing: a multilingual dataset of responses to fight online hate speech”. Proceedings of the 57th annual Meeting of the Association for Computational Linguistics, 2819–2829.
6] Chung, E. L., Teciroglu, S. M., Guerini. 2020. “Italian Counter Narrative Generation to Fight Online Hate Speech”. CLiC.
[7] Xue, L., Constant, N. Roberts, A., Rúa, M., "Ao-Rfou, R. Siddhant A. O Bárbaro, A., e Raffel, C. 2020. “mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer”. North American Chapter of the Association for Computational Linguistics.
[8] Vaswani, A. Shazeer, N.M., Parmar, N., Uszkoreit, J. Jones, L. Gomez, A.N., Kaiser, L., e Polosukhin, I. 2017. “Attention is All you Need”. Neural Information Processing Systems
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










