



Création automatique de contre-narrations en basque et en espagnol
Ces dernières années, la présence de discours haineux (GD) dans les médias s’est intensifiée sous l’effet de l’anonymat généré par les réseaux sociaux. Le GD a été défini comme « un langage utilisé pour exprimer la haine contre un groupe particulier », un langage qui « vise à insulter, humilier ou dénigrer les membres de ce groupe »[1].
Aujourd'hui, les réseaux sociaux mettent constamment à jour leurs politiques de lutte contre les messages de haine en bloquant ou en supprimant les messages. Pour alléger la charge de travail qui en résulte, la détection automatique de la GD est intéressante car elle développe des ensembles de données[2] et utilise des techniques d'apprentissage automatique et approfondi[1]. Cependant, ces méthodes de modération de la GD ont suscité des controverses, car beaucoup affirment qu’elles peuvent limiter la liberté d’expression[3]. Les contre-narrations (KN) ont été proposées comme des mesures efficaces pour contrer et atténuer la propagation de la GD[4]. Le KN est une réponse non agressive à un commentaire haineux avec des commentaires non négatifs basés sur des arguments et des faits[3]. un exemple peut être vu dans la figure 1.

Dans ce contexte, la recherche sur la génération automatique de KN a considérablement augmenté ces dernières années. Cette étude aborde cette tâche en étudiant pour la première fois cette tâche en basque et en espagnol, en utilisant différents moyens et méthodes pour le faire.
Création automatique de contre-narrations
La recherche sur les KNs a considérablement augmenté ces derniers temps, mais il y a une difficulté qui fait obstacle à la recherche évidente: le manque de données. C'est précisément dans ce but que le CONAN a été créé, un ensemble de données qui a servi de base à cette étude. Chung et ses associés[5] ont rassemblé des couples GD-KN sur l'islamophobie dans les trois langues. Grâce à cela, ils ont obtenu un corpus solide de couples GD-KN, non transitoire, basé sur des experts et multilingue. La méthode de nichesourcing a permis de recruter du personnel expérimenté dans le domaine de la collecte de données, en privilégiant la qualité des KN et en collectant des données non stéréotypées et variées. Cette méthode, qui prend beaucoup de temps et est coûteuse, a conduit à un processus d'augmentation de la quantité de données: trois non-experts ont créé deux paraphrases de chaque KN original et ont traduit les paires GD-KN original en français et italien en anglais. Ainsi, 6654 paires de GD-KN ont été définitivement rassemblées dans le corpus anglais.
Bien que cet ensemble de données couvre plusieurs langues, il convient de noter que les travaux sur la génération automatique des KN ont été réalisés principalement en anglais, en raison de la rareté des données collectées manuellement et de la rareté des modèles linguistiques créatifs[6]. D'après ce que nous savons, peu d'ouvrages ont été publiés sur la création des KN dans des langues autres que l'anglais.
Collecte de données en basque et en espagnol
Par conséquent, dans ce domaine où la plupart des travaux ont été réalisés en anglais, il n'est pas surprenant que rien n'ait été fait en basque et en espagnol. Cette lacune a conduit à la création de CONAN-EUS, le premier ensemble parallèle de données en basque et en espagnol utile pour la création automatique de KN.
Pour ce faire, ces instances GD-KN 6654 du corpus anglais CONAN ont été traduites automatiquement en basque et en espagnol via l'API Google. Ces données traduites automatiquement en espagnol et en basque ont ensuite été postées par 3 traducteurs professionnels. Il a été décidé de faire une post-édition manuelle, bien que coûteuse, car une telle ressource était plus rapide et plus facile à construire à partir de zéro. En outre, l'existence d'un ensemble de données parallèles avec le CONAN original en anglais permet d'effectuer des recherches innovantes en utilisant des méthodes de transfert multilingues et interlinguistiques.
Dans cette étude, nous avons utilisé CONAN-EUS pour générer automatiquement des KNs en utilisant des données traduites automatiquement, mais aussi des données post-traduites. Ainsi, notre objectif est de comparer les contre-récits générés avec la traduction automatique et les données post-titrées afin d’analyser l’impact de la post-édition sur les KN générés automatiquement.
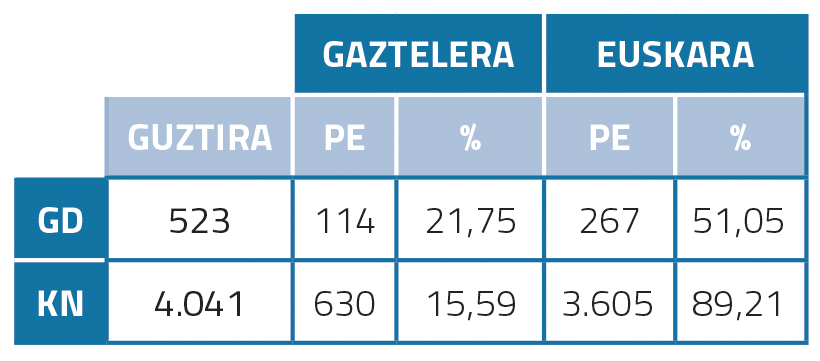
Post-scriptum en basque et en espagnol
Si l'on regarde les statistiques de post-édition de l'euskara (tableau 1), on peut voir que le pourcentage est très élevé : 51,05 % pour les GD, 89,21 % pour les KN. Nous pensons que cela peut être dû à la qualité médiocre de la traduction automatique. En outre, il a fallu publier plus de KN que de GD, probablement parce que les KN sont généralement plus longs et plus complexes et ont donc nécessité plus de post-édition. En espagnol, par contre, les pourcentages publiés en GD et KN sont beaucoup plus bas que les montants en basque : 21,75 % et 15,59 %. Cela pourrait être dû au fait que la qualité de la traduction automatique vers l'anglais-espagnol est plus élevée.
Comment créer et évaluer automatiquement du texte ?
Dans cette étude, nous avons utilisé un modèle linguistique multilingue de type transformer mT5[7] pour générer automatiquement des KN. L'architecture de ces types de modèles est illustrée à la figure 2. Nous avons formé ces modèles avec une partie de notre ensemble de données afin que vous puissiez créer automatiquement un KN pour chaque GD dans la partie que vous n'avez pas vue.
Pour évaluer la qualité de ces KN générés, nous avons utilisé trois métriques automatiques: BLEU (mesure de la corrélation des n-grammes entre les textes d’entrée et de sortie), Rouge-L (calcul de la Sous-équation Commune La plus Longue entre la référence et le texte de sortie (LCS)) et Repetition Rate (RR, calcul des n-grammes répétés dans le texte généré).
Effet de la post-édition sur les résultats de la création
En commençant par les modèles monolingues, le résultat le plus remarquable est que la post-édition des données traduites automatiquement améliore la création des KN en basque et en espagnol (Tableau 2). En outre, bien que les PE aient obtenu de meilleurs résultats dans les mesures BLEU et ROUGE-L, les résultats RR sont meilleurs avec des données en anglais (7,79 en espagnol, 5,73 en anglais). Cela nous indique que les résultats élevés obtenus dans les mesures de chevauchement n-gramme en espagnol ont pu être générés par des répétitions. Dans les résultats du basque, d'autre part, bien que les résultats de l'eu-PE soient meilleurs que ceux de l'eu-MT, ils sont nettement inférieurs à ceux de l'anglais et de l'espagnol. Notre hypothèse est que le basque n’est pas aussi présent que l’anglais ou l’espagnol dans le vocabulaire du modèle mT5.
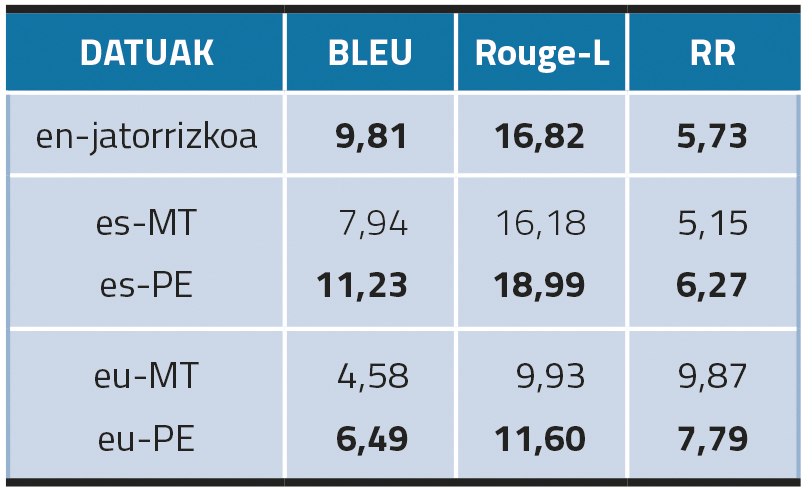
En résumé, les résultats de l'évaluation automatique montrent que, dans le cadre de ces expériences avec des modèles monolingues (c'est-à-dire des modèles affinés avec des ensembles de données traduits dans la langue cible), une étape de post-édition est nécessaire pour obtenir des résultats optimaux, étant donné que les modèles affinés avec des données traduites automatiquement n'atteignent pas le même niveau de performance.
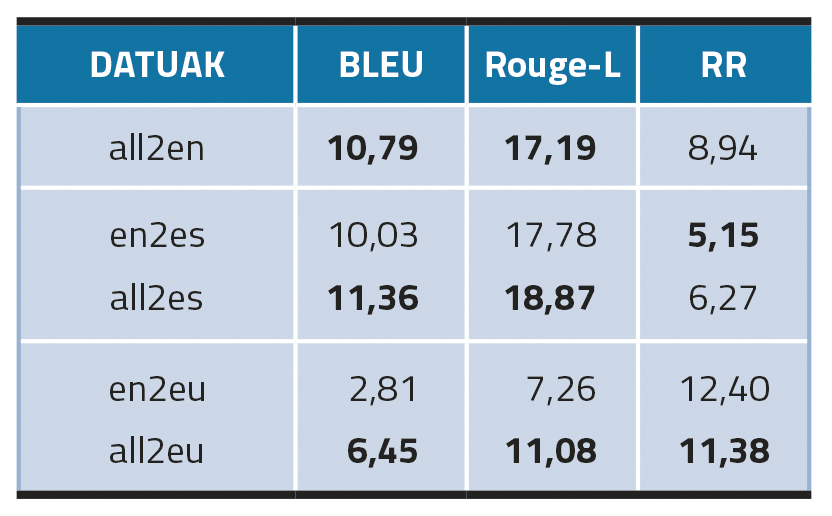
Dans les modèles multilingues, il a été constaté que le raffinement de l'anglais et du castillan (all2en et all2es) dans les trois langues a donné de meilleurs résultats, en particulier dans le cas de l'anglais. En revanche, ce n'est pas le cas pour le basque (all2eu), ce qui peut suggérer que l'augmentation des données multilingues peut mieux fonctionner dans des langues structurellement similaires, dans notre cas, l'anglais et l'espagnol.
En ce qui concerne l'environnement de transfert interlinguistique, cette méthode (en2es) a bien fonctionné en espagnol, surpassant les résultats des modèles monolingues (es-MT). En basque, cependant, le transfert de modèle interlinguistique (en2eu) échoue complètement et est nettement inférieur à eu-MT.
Évaluation manuelle
Il y a un problème dans la génération de KN : la fiabilité des métriques automatiques. C’est pourquoi nous avons effectué une évaluation manuelle afin d’évaluer la fiabilité de nos résultats.
Pour ce faire, cinq critères ont été analysés: la relation (GD et KN sont liés), la spécificité (KN est générale ou spécifique), la richesse (en termes linguistiques, quel type de richesse elle a), la cohérence (les phrases ont un sens ensemble) et la grammaire (correction grammaticale des phrases). Deux linguistes dont la langue maternelle était le basque ou le castillan y ont travaillé.
Ainsi, dans les modèles monolingues, nous avons constaté qu’il existe une corrélation entre les métriques automatiques et manuelles : en basque et en espagnol, l’évaluation manuelle privilégie également les résultats des données publiées. Cela nous indique que, dans notre cas, ces métriques automatiques sont fiables.
Conséquences
L'ensemble de données CONAN-EUS est un nouvel ensemble parallèle de données en basque et en espagnol pour la génération KN-créé en traduisant automatiquement 6654 paires GD-KN originales en anglais et en postant par des professionnels. Cette ressource a permis de mener des recherches innovantes d'un point de vue multilingue et interlinguistique dans le domaine de la création de KN.
Des expériences ont montré que la création de KN est préférable si le modèle est affiné avec des données post-éditées plutôt qu'avec des données traduites automatiquement. En outre, les résultats médiocres obtenus en basque dans les expériences interlinguistiques ont souligné l'importance de disposer de données d'entraînement dans la langue cible, notamment dans les langues à faibles ressources comme le basque. Toutefois, la méthode de transfert interlinguistique reste un problème de recherche ouvert et complexe dans les modèles créatifs, ce qui laisse ouverte la voie à suivre pour l'avenir.
Bibliographie
[1] Davidson, T., Warmsley, D., Macy, M.W., et Weber, I. 2017. “Automated Hate Speech Detection and the Problem of Offensive Language”. International Conference on Web and Social Media.
[2] Basile, V., Bosco, C., Fersini, E., Nozza, D., Patti, V Pardo, F.M., Rosso, P., et Sanguinetti, M. 2019. “SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter.» International Workshop on Semantic Evaluation.
[3] Schieb, C., et Preuss, M. 2016. governing hate speech by means of counterspeech on Facebook. 66th ica annual conference, 1-23.
[4] Benesch, S. 2014. “Countering dangerous speech: Nouvelles idées pour la prévention du génocide». SSRN 3686876.
[5] Chung, Y., Kuzmenko, E Tekiroğlu, S.S., et Guerini, M. 2019. “CONAN - COunter NAratives through nichesourcing: a multilingual dataset of responses to fight online hate speech”. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2819-2829.
[6] Chung, Y. L., Tekiroglu, S. S., et Guerini, M. 2020. “Italian Counter Narrative Generation to Fight Online Hate Speech”. CLiC-it.
[7] Xue, L., Constant, N., Roberts, A Kale, M Rfou, R., Siddhant, A., Barua, A, et Raffel, C. 2020. “mT5: A Massively Multilingual Pré-trained Text-to-Text Transformer.” North American Chapter of the Association for Computational Linguistics.
[8] Vaswani, A., Shazeer, N.M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., et Polosukhin, I. 2017. "Attention is all you need." Systèmes de traitement de l'information neurale.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










