



Creación automática de contrnarrativas en euskera y castellano
En los últimos años se ha incrementado la presencia del discurso de odio (GD) en los medios de comunicación a través de la anonimización que generan las redes sociales. El GD se ha definido como “el lenguaje utilizado para expresar el odio contra un grupo determinado”, “el lenguaje que pretende insultar, humillar o menospreciar a sus miembros”[1].
En la actualidad, las redes sociales actualizan continuamente sus políticas para hacer frente a los mensajes de odio, bloqueando o eliminando mensajes. Para aliviar la carga de trabajo que ello implica, la detección automática de GD tiene interés en el desarrollo de conjuntos de datos[2] y en el uso de técnicas de aprendizaje automático y profundo[1]. Sin embargo, estos métodos de moderación del GD han creado controversia, ya que muchos argumentan que pueden limitar la libertad de expresión[3]. Como alternativa, se han propuesto contra-narrativas (KN) como medidas eficaces para hacer frente y paliar la expansión del GD. El KN es dar una respuesta no agresiva a un comentario de odio con feedback no negativo basado en argumentos y hechos[3]. En la figura 1 se puede ver un ejemplo.

En este contexto, la investigación en torno a la generación automática de KN ha crecido de forma notable en los últimos años. Este estudio lo aborda, analizando esta tarea por primera vez en euskera y castellano, utilizando diversos recursos y métodos.
Creación automática de contrnarrativas
La investigación sobre KN ha aumentado considerablemente en los últimos años, pero hay una dificultad que dificulta la investigación: la escasez de datos. Precisamente con el propósito de hacer frente a este reto nace CONAN, el conjunto de datos que se han tomado como base para esta investigación. Chung y sus compañeros reunieron en tres idiomas a parejas de GD-KN en torno a la islamofobia. A través de ella, obtuvieron un corpus sólido de parejas GD-KN, no transitorio, basado en expertos y multilingüe. Mediante el método Nichesourcing se contrató personal experto en la materia para la recogida de datos, priorizando la calidad del CN y recogiendo datos no estereotipados y variados. Este método tarda mucho y es caro, por lo que se llevó a cabo un proceso para aumentar la cantidad de datos: tres no expertos crearon dos parafrasias de cada KN original y las parejas GD-KN originales fueron traducidas al inglés. De este modo, un total de 6654 parejas de GD-KN fueron definitivamente agrupadas en la parte del corpus en inglés.
A pesar de que este conjunto de datos abarca varias lenguas, cabe destacar que los trabajos sobre la creación automática de KN se han desarrollado principalmente en inglés, debido a la escasez de datos recogidos a mano y a la escasez de modelos lingüísticos generadores. Sabemos que se han publicado pocos trabajos sobre la creación de KNs en lenguas distintas al inglés.
Recogida de datos en euskera y castellano
Por lo tanto, no es de extrañar que en este campo donde la mayoría de los trabajos se han realizado en inglés no hayan hecho nada en euskera y castellano. Este vacío nos llevó a crear CONAN-EUS, el primer conjunto de datos paralelo en euskera y castellano que sirve para la creación automática de KN.
Para ello, las 6654 GD-KN del corpus en inglés CONAN fueron traducidas automáticamente al euskera y al castellano a través de Google API. Posteriormente, estos datos traducidos automáticamente en castellano y euskera fueron posteditados por 3 traductores profesionales. Se decidió realizar una postedición manual, aunque costosa, porque era más rápido y más fácil que construir un recurso desde cero. Además, disponer de un conjunto de datos paralelo con CONAN en inglés original permite realizar investigaciones innovadoras utilizando métodos de transferencia multilingüe e e interlingüística.
En este estudio, hemos utilizado CONAN-EUS para crear automáticamente KNs utilizando datos traducidos automáticamente, pero también mediante datos posteditados. De esta manera, nuestro objetivo es contrastar las contranarrativas generadas con la traducción automática y los datos posteditados, para analizar el impacto de la postedición en los KN generados de forma automática.
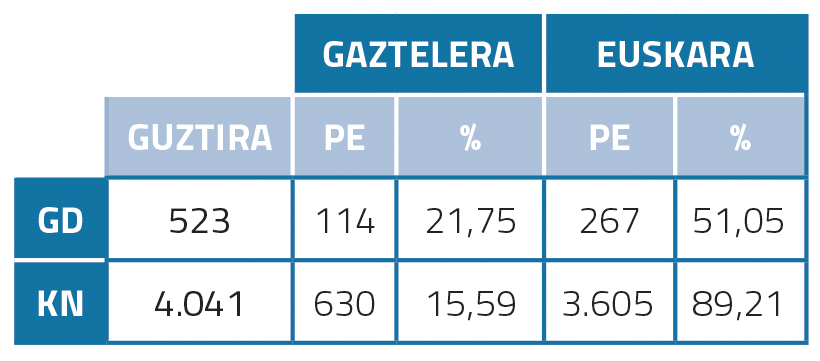
Postedición en euskera y castellano
Si nos fijamos en las estadísticas de postedición del euskera (tabla 1), vemos que el porcentaje es muy alto: 51,05% en el caso de GD, 89,21% en el caso de KN. Se trata de la hipótesis de que esto puede deberse a la mala calidad de la traducción automática. Además, hubo que posteditar más KN que GD, probablemente porque los KN en general son más largos y complejos y por lo tanto necesitaron más postediciones. En castellano, por el contrario, los porcentajes posteditados por GD y KN son mucho más bajos que los importes en euskera: 21,75% y 15,59%. Esto puede ser debido a que la calidad de la traducción automática entre el inglés y el español es mayor.
¿Cómo crear y evaluar automáticamente el texto?
En este estudio se ha utilizado el modelo lingüístico plurilingüe mT5[7] de tipo transformador para la creación automática de KNs. La arquitectura de este tipo de modelos se puede ver en la figura 2. Estos modelos han sido entrenados con una parte de nuestro conjunto de datos, de manera que en la parte no visible se pueda crear automáticamente un KN para cada ED.
Para evaluar la calidad de los KN generados, hemos utilizado tres métricas automáticas: BLEU (medición de la correlación de los n-gramas entre los textos de entrada y salida), Rouge-L (cálculo de la Ecuación de W.C. más larga entre la referencia y el texto de salida) y Repetition Rate (RR, cálculo de los n-grams que se repiten en el texto generado).
Influencia de la postedición en los resultados de la creación
Comenzando con modelos monolingües, el resultado más destacado es que la postedición de los datos traducidos automáticamente mejora la creación de KN tanto en euskera como en castellano (Tabla 2). Además, a pesar de que los es-PEN logran mejores resultados en BLEU y ROUGE-L, los resultados de RR son mejores con datos en inglés (7,79 en castellano y 5,73 en inglés). Esto nos indica que los altos resultados obtenidos en las métricas de superposición del n-grama en castellano han podido ser generados por las repeticiones. En cuanto a los resultados en euskera, aunque los resultados de eu-PE son mejores que los de eu-MT, son notablemente inferiores a los de inglés y castellano. Nuestra hipótesis es que el euskera no está tan presente como el inglés o el castellano en el diccionario del modelo mT5.
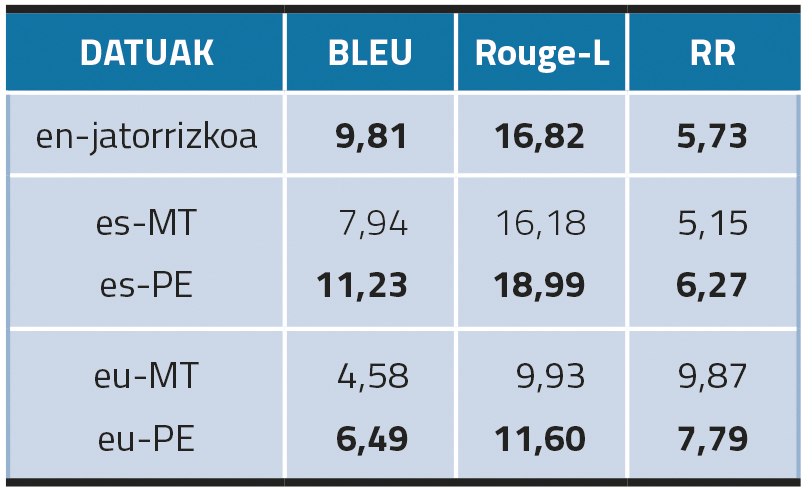
En resumen, los resultados de la evaluación automática muestran que en estos experimentos con modelos monolingües (es decir, refinados con conjuntos de datos traducidos al idioma de destino) es necesario un paso de postedición para obtener resultados óptimos, ya que los modelos refinados con datos traducidos automáticamente no alcanzan el mismo nivel de rendimiento.
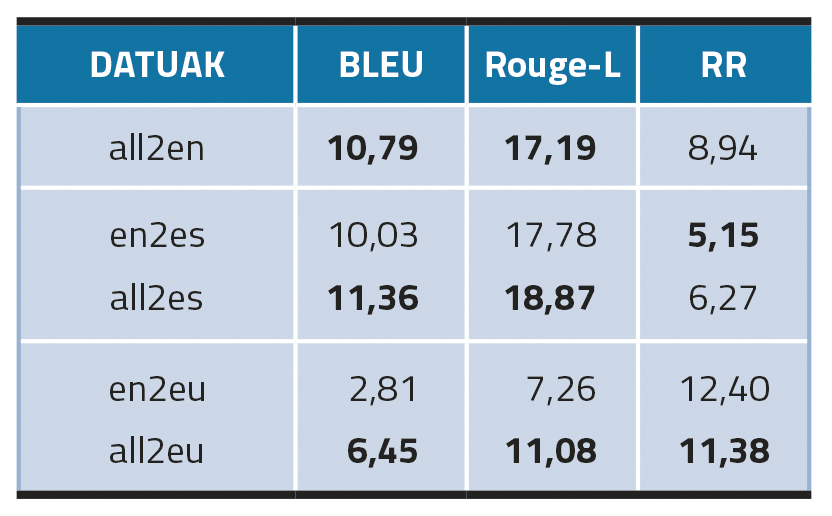
En modelos plurilingües, en el caso del inglés y el castellano (all2en y all2es) se ha visto que afinar en los tres idiomas ha dado mejores resultados, sobre todo en el caso del inglés. Sin embargo, esto no ocurre en el caso del euskera (all2eu), lo que puede sugerir que la ampliación de datos multilingües puede funcionar mejor en lenguas estructuralmente similares, en nuestro caso el inglés y el castellano.
En cuanto al entorno de transferencia interlingüística, este método (en2es) ha funcionado bien en castellano, ya que ha superado los resultados de los modelos monolingües (es-MT). En euskera, sin embargo, la transferencia de modelos interlingüísticos (en2eu) falla completamente y se ha quedado muy por debajo de eu-MT.
Evaluación manual
Un problema en la generación de KN es la fiabilidad de las métricas automáticas. Por ello, realizamos una evaluación manual para analizar la fiabilidad de nuestros resultados.
Para ello, se analizaron cinco criterios: la relación (DG y KN están relacionados), la especificidad (el KN es general o específico), la riqueza (en cuanto al idioma, la riqueza que tiene), la coherencia (las frases tienen sentido común) y la gramaticalidad (corrección gramatical de las frases). En este trabajo trabajaron dos lingüistas que tenían como lengua materna el euskera o el castellano.
Así, en los modelos monolingües observamos que existe una correlación entre las métricas automáticas y manuales: en euskera y castellano, la evaluación manual también prioriza los resultados de los datos posteditados. Esto nos indica que, para nuestro caso, estas métricas automáticas son fiables.
Conclusiones
El conjunto de datos CONAN-EUS es un nuevo conjunto paralelo de datos para la creación de KN-EUS en euskera y castellano, creado a través de la traducción automática y la postedición de la pareja GD-KN en inglés original. Este recurso ha permitido realizar investigaciones innovadoras desde una perspectiva multilingüe e interlingüística en el campo de la creación de KNs.
Los experimentos han demostrado que la generación de KN es mejor si el modelo se refina con datos posteditados, en lugar de con datos traducidos automáticamente. Además, los deficientes resultados obtenidos en los experimentos interlingüísticos en euskera han incidido en la importancia de disponer de datos de entrenamiento en la lengua de destino, sobre todo en las lenguas de menos recursos como el euskera. Sin embargo, el método de transferencia interlingüística sigue siendo un problema abierto y complejo de indagación en los modelos creativos, lo que deja abierta la línea de trabajo para el futuro.
Bibliografía
1] Davidson, T., Warmsley, D. Macy, M.W. y Weber, I. 2017. “Automated Hate Speech Detection and the Problem of Offensive Language”. International Conference on Web and Social Media.
[2] Basile, V. Bosco, C., Fersini, E. Noción, D., Patti, V. Pardo, F.M., Rosso, P. Y Sanguinetti, M. 2019. “SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Etorkants and Women in Twitter”. International Workshop on Semantic Evaluation.
3) Schieb, C., y Preuss, M. 2016. “Governing hate speech by means of counterspeech on Facebook”. 66th ica annual conference, 1-23.
[4] Benesch, S. 2014. “Countering dangerous speech: New ideas for genocide prevention”. SSRN 3686876.
5] Chung, Y., Kuzmenko, E. Tekirocarriles, S.S., y Guerini, M. 2019. “CONAN - COunter NArratives through nichesourcing: a multilingual dataset of responses to fight online hate speech”. Proceedings of the 57th annual Meeting of the Association for Computational Linguistics, 2819–2829.
6] Chung, Y. L., Teciroglu, S. M., Guerini. 2020. “Italian Counter Narrative Generation to Fight Online Hate Speech”. CLiC.
[7] Xue, L., Constant, N. Roberts, A., Calle, M., "Al-Rfou, R. Siddhant A. El Bárbaro, A., y Raffel, C. 2020. “mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer”. North American Chapter of the Association for Computational Linguistics.
[8] Vaswani, A. Shazeer, N.M., Parmar, N., Uszkoreit, J. Jones, L. Gomez, A.N., Kaiser, L., y Polosukhin, I. 2017. “Attention is All you Need”. Neural Information Processing Systems
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










