



Automatic creation of counter-narratives in Basque and Spanish
In recent years, the presence of hate speech (GD) in the media has increased, driven by the anonymization generated by social networks. GD has been defined as “a language used to express hatred against a particular group, a language that intends to insult, humiliate or disparage members of that group.”[1]
Today, social networks are constantly updating their policies to combat hate messages by blocking or deleting them. In order to alleviate the workload involved, automatic detection of GD is of interest, as it involves the development of data sets[2] and the use of machine and deep learning techniques[1]. However, these methods of moderating GD have been controversial, with many arguing that they may limit freedom of expression.[3] As an alternative, counternarratives (KN) have been proposed as effective measures to combat and mitigate the spread of GD[4]. The KN is a non-aggressive response to a hate speech, with non-negative feedback based on arguments and facts[3]. an example is illustrated in Fig. 1 .

In this context, research on the automatic generation of KN has grown significantly in recent years. This research addresses this by analyzing this task for the first time in Basque and Spanish, using different means and methods.
Automatic creation of counter-narratives
Research on KN has grown significantly in recent times, but there is a difficulty that hinders the obvious research: data scarcity. CONAN was set up with the aim of combating this problem, a set of data that has been used as a basis for this research. There, Chung and colleagues[5] brought together GD-KN couples on Islamophobia in all three languages. Through this, they obtained a solid corpus of non-transitory, expertly based and multilingual GD-KN couples. Through the nichesourcing method, expert personnel in the field were hired to perform the data collection, prioritizing the quality of the CC and collecting non-stereotyped and varied data. This method is time-consuming and expensive, so a process was carried out to increase the amount of data: three unexperts created two paraphrases of each original KN, and the original French and Italian GD-KN pairs were translated into English. Thus, 6654 GD-KN pairs were definitively collected in the corpus fragment in English.
Although this data set covers several languages, it should be noted that work on the automatic generation of KNs has been carried out mainly in English due to the scarcity of manually collected data and the scarcity of creative language models[6]. As far as we know, few works have been published on the creation of KNs in languages other than English.
Data collection in Basque and Spanish
Therefore, in this area where most of the works have been done in English, it is not surprising that nothing has been done in Basque and Spanish. This gap led us to create CONAN-EUS, the first parallel data set in Basque and Spanish that is useful for the automatic generation of KNs.
For this purpose, these 6654 GD-KN instances of the CONAN corpus in English were automatically translated into Basque and Spanish through the Google API. Subsequently, these automatically translated data in Spanish and Basque were post-edited by 3 professional translators. It was decided to do manual post-editing, although it was expensive, as it was faster and easier than building such a resource from scratch. In addition, the availability of a parallel set of data to the CONAN in native English enables innovative research using multi-language and inter-language transfer methods.
In this study, we used CONAN-EUS to automatically generate KNs using automatically translated data, but also using post-edited data. Thus, our goal is to compare the generated counter-narratives with machine translation and post-edited data to analyze the impact of post-editing on the automatically generated KNs.
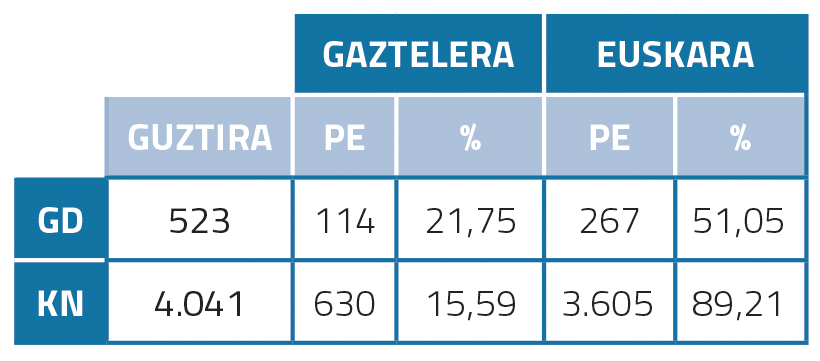
Post in Basque and Spanish
If we look at the Basque post-editing statistics (Table 1), we can see that the percentage is very high: 51.05% in the case of GD; 89.21% in the case of KN. We hypothesize that this may be due to the poor quality of machine translation. In addition, more KNs had to be post-edited than GD, probably because KNs are generally longer and more complex and therefore required more post-editing. In Spanish, on the other hand, the percentages post-edited in GD and KN are much lower than the amounts in Basque: 21.75% and 15.59%. This could be due to the fact that the quality of automatic translation into English-Spanish is higher.
How to create and evaluate text automatically?
In this study, we used the multi-lingual model mT5[7] of the transformer type to automatically generate KNs. The architecture of these types of models is illustrated in Figure 2. We have trained these models with a part of our dataset so that we can automatically generate a KN for each GD in the part you have not seen.
To evaluate the quality of the generated KN, we have used three automatic metrics: BLEU (measurement of n-gram correlation between input and output text), Rouge-L (calculation of Longest Common Subsequence (LCS) between reference and output text) and Repetition Rate (RR, calculation of n-grams that are repeated in the generated text).
The effect of post-editing on the results of creation
Starting with monolingual models, the most notable result is that the post-editing of automatically translated data improves the creation of KNs in both Basque and Spanish (Table 2). In addition, despite the fact that es-PEs achieve better results in the BLEU and ROUGE-L measurements, the RR results are better with data in English (7.79 in Spanish; 5.73 in English). This indicates that the high results in n-gram overlap metrics in Spanish may have been generated by repetitions. In the Basque language, on the other hand, although the results of eu-PE are better than those of eu-MT, they are significantly lower compared to the results of English and Spanish. Our hypothesis is that Basque is not as present in the mT5 model vocabulary as English or Spanish.
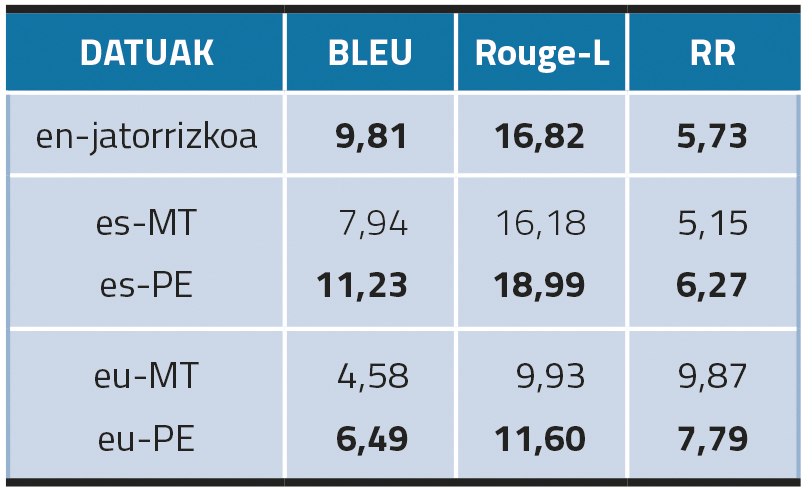
In short, the results of the automatic evaluation show that in these experiments with monolingual models (i.e. models refined with datasets translated into the target language) a post-editing step is necessary to obtain optimal results, since models refined with data translated automatically do not achieve the same level of performance.
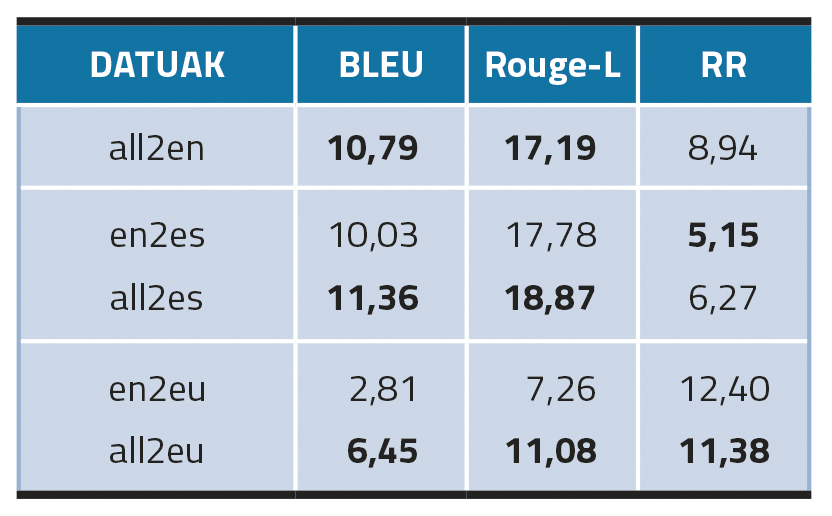
In multilingual models, in the case of English and Spanish (all2en and all2es) it has been observed that the refinement in the three languages has achieved better results, especially in the case of English. On the other hand, this does not happen in the case of Basque (all2eu), which may suggest that multi-language data augmentation may work better in structurally similar languages; in our case, English and Spanish.
As for the inter-language transfer environment, this method (en2es) has worked well in Spanish, exceeding the results of monolingual models (es-MT). In Basque, however, the inter-language model transfer (en2eu) fails completely and has fallen significantly below eu-MT.
The manual evaluation
One problem in KN generation is the reliability of automatic metrics. That’s why we conducted a manual evaluation to analyze the reliability of our results.
For this, five criteria were analyzed: relationship (GD and KN are related), specificity (KN is general or specific), richness (linguistically, what kind of richness it has), coherence (phrases make sense together) and grammaticity (grammatical correctness of phrases). There were two linguists whose mother tongue was Basque or Spanish.
Thus, in monolingual models we found that there is a correlation between automatic and manual metrics: in Basque and Spanish, manual evaluation also favors the results of post-edited data. This tells us that, for our case, these automatic metrics are reliable.
The consequences of
The CONAN-EUS dataset is a new parallel dataset in Basque and Spanish for the creation of KN, created by the automatic translation and post-editing of 6654 GD-KN pairs in original English. This resource has made it possible to carry out innovative research from a multi-lingual and inter-lingual perspective in the field of KN creation.
Experiments have shown that KN generation is better if the model is refined with post-edited data rather than automatically translated data. In addition, the poor results obtained in inter-language experiments in Basque have underlined the importance of having training data in the target language, especially in languages with few resources such as Basque. However, the inter-language transfer method remains an open and complex research problem in creative models, which leaves the line of work open for the future.
The bibliography
[1] Davidson, T., More places to stay in Warmsley, D., Macy, M.W., and Weber, I. 2017. “Automated Hate Speech Detection and the Problem of Offensive Language”. International Conference on Web and Social Media.
[2] Basile, V., We're talking about Bosco, C., Assisted by Fersini, E., Assisted by Nozza, D., Assisted by Patti, V., Assisted by Pardo, F.M., Rosso, P., and Sanguinetti, M. 2019. “SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter”. International Workshop on Semantic Evaluation.
[3] Schdeg, C., and Preuss, M. 2016. “Governing speech hate by means of counterspeech on Facebook”. 66th ica annual conference, 1-23.
[4] Benesch, S. 2014. “Countering dangerous speech: New ideas for genocide prevention”. SSRN 3686876.
[5] Chung, Y., I'm talking about Kuzmenko, E., Tekiroğlu, S.S., and Guerini, M. 2019. “CONAN - COunter NArratives through nichesourcing: a multilingual dataset of responses to fight online hate speech”. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2819–2829.
[6] Chung, Y. I'm talking about L., A review of Tekiroglu, S. S., and Guerini, M. 2020. “Italian Counter Narrative Generation to Fight Online Hate Speech”. The CLiC-it.
[7] Xue, L., Assisted by Constant, N., Assisted by Roberts, A., I'm talking about Kale, M., I'm talking about Al-Rfou, R., Assisted by Siddhant, A., Barua, A., and Raffel, C. 2020. “The mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer”. North American Chapter of the Association for Computational Linguistics.
[8] Vaswani, A., About Shazeer, N.M., We are located in Parmar, N., We're talking about Uszkoreit, J., We're talking about Jones, L., About Gómez, A.N., Kaiser, L., and Polosukhin, I. 2017. “Attention is All You Need”. Neural Information Processing Systems.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










