



Creació automàtica de contrnarrativas en basca i castellà
En els últims anys s'ha incrementat la presència del discurs d'odi (GD) en els mitjans de comunicació a través de l'anonimització que generen les xarxes socials. El GD s'ha definit com “el llenguatge utilitzat per a expressar l'odi contra un grup determinat”, “el llenguatge que pretén insultar, humiliar o menysprear als seus membres”[1].
En l'actualitat, les xarxes socials actualitzen contínuament les seves polítiques per a fer front als missatges d'odi, bloquejant o eliminant missatges. Per a alleujar la càrrega de treball que això implica, la detecció automàtica de GD té interès en el desenvolupament de conjunts de dades[2] i en l'ús de tècniques d'aprenentatge automàtic i profund[1]. No obstant això, aquests mètodes de moderació del GD han creat controvèrsia, ja que molts argumenten que poden limitar la llibertat d'expressió[3]. Com a alternativa, s'han proposat contra-narratives (KN) com a mesures eficaces per a fer front i pal·liar l'expansió del GD. El KN és donar una resposta no agressiva a un comentari d'odi amb feedback no negatiu basat en arguments i fets[3]. En la figura 1 es pot veure un exemple.

En aquest context, la recerca entorn de la generació automàtica de KN ha crescut de manera notable en els últims anys. Aquest estudi l'aborda, analitzant aquesta tasca per primera vegada en basca i castellà, utilitzant diversos recursos i mètodes.
Creació automàtica de contrnarrativas
La recerca sobre KN ha augmentat considerablement en els últims anys, però hi ha una dificultat que dificulta la recerca: l'escassetat de dades. Precisament amb el propòsit de fer front a aquest repte neix CONAN, el conjunt de dades que s'han pres com a base per a aquesta recerca. Chung i els seus companys van reunir en tres idiomes a parelles de GD-KN entorn de la islamofòbia. A través d'ella, van obtenir un corpus sòlid de parelles GD-KN, no transitori, basat en experts i multilingüe. Mitjançant el mètode Nichesourcing es va contractar personal expert en la matèria per a la recollida de dades, prioritzant la qualitat del CN i recollint dades no estereotipades i variats. Aquest mètode triga molt i és car, per la qual cosa es va dur a terme un procés per a augmentar la quantitat de dades: tres no experts van crear dos parafrasias de cada KN original i les parelles GD-KN originals van ser traduïdes a l'anglès. D'aquesta manera, un total de 6654 parelles de GD-KN van ser definitivament agrupades en la part del corpus en anglès.
A pesar que aquest conjunt de dades abasta diverses llengües, cal destacar que els treballs sobre la creació automàtica de KN s'han desenvolupat principalment en anglès, a causa de l'escassetat de dades recollides a mà i a l'escassetat de models lingüístics generadors. Sabem que s'han publicat pocs treballs sobre la creació de KNs en llengües diferents a l'anglès.
Recollida de dades en basca i castellà
Per tant, no és d'estranyar que en aquest camp on la majoria dels treballs s'han realitzat en anglès no hagin fet res en basc i castellà. Aquest buit ens va portar a crear CONAN-EUS, el primer conjunt de dades paral·lel en basca i castellà que serveix per a la creació automàtica de KN.
Per a això, les 6654 GD-KN del corpus en anglès CONAN van ser traduïdes automàticament al basc i al castellà a través de Google API. Posteriorment, aquestes dades traduïdes automàticament en castellà i basc van ser posteditats per 3 traductors professionals. Es va decidir realitzar una postedició manual, encara que costosa, perquè era més ràpid i més fàcil que construir un recurs des de zero. A més, disposar d'un conjunt de dades paral·lel amb CONAN en anglès original permet realitzar recerques innovadores utilitzant mètodes de transferència multilingüe e i interlingüïstica.
En aquest estudi, hem utilitzat CONAN-EUS per a crear automàticament KNs utilitzant dades traduïdes automàticament, però també mitjançant dades posteditades. D'aquesta manera, el nostre objectiu és contrastar les contranarrativas generades amb la traducció automàtica i les dades posteditades, per a analitzar l'impacte de la postedició en els KN generats de manera automàtica.
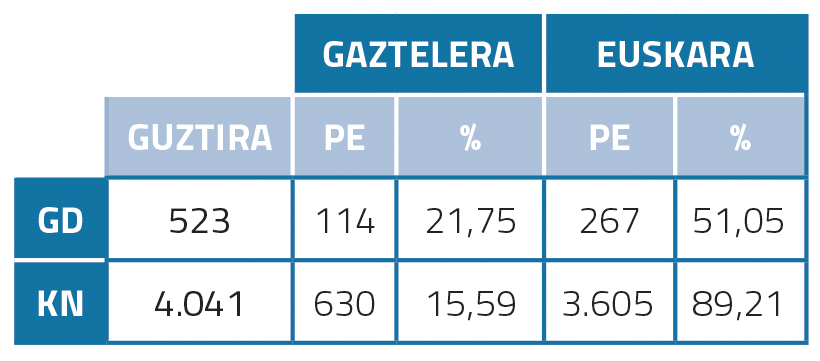
Postedició en basca i castellà
Si ens fixem en les estadístiques de postedició del basc (taula 1), veiem que el percentatge és molt alt: 51,05% en el cas de GD, 89,21% en el cas de KN. Es tracta de la hipòtesi que això pot deure's a la mala qualitat de la traducció automàtica. A més, va caldre posteditar més KN que GD, probablement perquè els KN en general són més llargs i complexos i per tant van necessitar més postedicions. En castellà, per contra, els percentatges posteditats per GD i KN són molt més baixos que els imports en basc: 21,75% i 15,59%. Això pot ser pel fet que la qualitat de la traducció automàtica entre l'anglès i l'espanyol és major.
Com crear i avaluar automàticament el text?
En aquest estudi s'ha utilitzat el model lingüístic plurilingüe mT5[7] de tipus transformador per a la creació automàtica de KNs. L'arquitectura d'aquesta mena de models es pot veure en la figura 2. Aquests models han estat entrenats amb una part del nostre conjunt de dades, de manera que en la part no visible es pugui crear automàticament un KN per a cada ED.
Per a avaluar la qualitat dels KN generats, hem utilitzat tres mètriques automàtiques: BLEU (mesurament de la correlació dels n-gramas entre els textos d'entrada i sortida), Rouge-L (càlcul de l'Equació de W.C. més llarga entre la referència i el text de sortida) i Repetition Rate (RR, càlcul dels n-grams que es repeteixen en el text generat).
Influència de la postedició en els resultats de la creació
Començant amb models monolingües, el resultat més destacat és que la postedició de les dades traduïdes automàticament millora la creació de KN tant en basca com en castellà (Taula 2). A més, a pesar que els és-PEN aconsegueixen millors resultats en BLEU i ROUGE-L, els resultats d'RR són millors amb dades en anglès (7,79 en castellà i 5,73 en anglès). Això ens indica que els alts resultats obtinguts en les mètriques de superposició del n-grama en castellà han pogut ser generats per les repeticions. Quant als resultats en basc, encara que els resultats d'eu-PE són millors que els d'eu-MT, són notablement inferiors als d'anglès i castellà. La nostra hipòtesi és que el basc no està tan present com l'anglès o el castellà en el diccionari del model mT5.
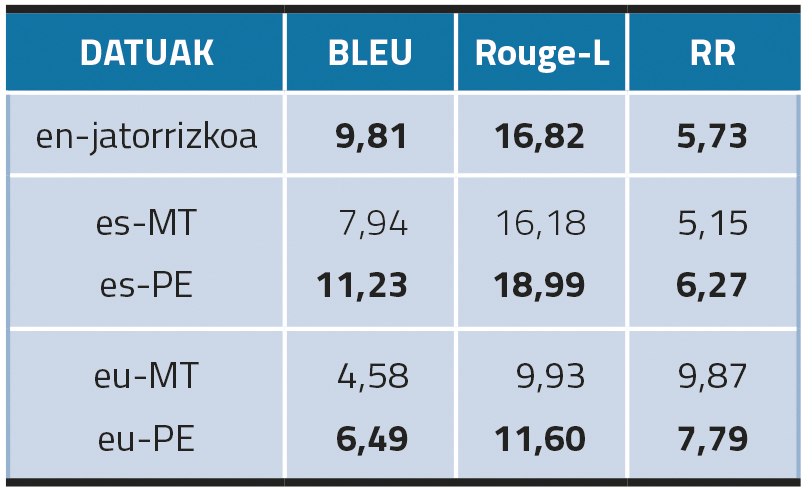
En resum, els resultats de l'avaluació automàtica mostren que en aquests experiments amb models monolingües (és a dir, refinats amb conjunts de dades traduïdes a l'idioma de destí) és necessari un pas de postedició per a obtenir resultats òptims, ja que els models refinats amb dades traduïdes automàticament no aconsegueixen el mateix nivell de rendiment.
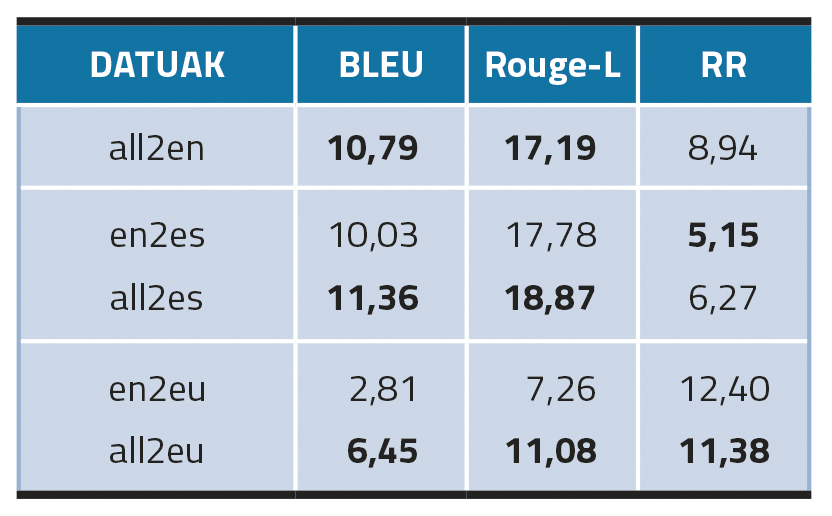
En models plurilingües, en el cas de l'anglès i el castellà (all2en i all2es) s'ha vist que afinar en els tres idiomes ha donat millors resultats, sobretot en el cas de l'anglès. Tanmateix, això no ocorre en el cas del basc (all2eu), la qual cosa pot suggerir que l'ampliació de dades multilingües pot funcionar millor en llengües estructuralment similars, en el nostre cas l'anglès i el castellà.
Quant a l'entorn de transferència interlingüïstica, aquest mètode (en2es) ha funcionat bé en castellà, ja que ha superat els resultats dels models monolingües (és-MT). En basc, no obstant això, la transferència de models interlingüïstics (en2eu) falla completament i s'ha quedat molt per sota d'eu-MT.
Avaluació manual
Un problema en la generació de KN és la fiabilitat de les mètriques automàtiques. Per això, realitzem una avaluació manual per a analitzar la fiabilitat dels nostres resultats.
Per a això, es van analitzar cinc criteris: la relació (DG i KN estan relacionats), l'especificitat (el KN és general o específic), la riquesa (quant a l'idioma, la riquesa que té), la coherència (les frases tenen sentit comú) i la gramaticalidad (correcció gramatical de les frases). En aquest treball van treballar dos lingüistes que tenien com a llengua materna el basc o el castellà.
Així, en els models monolingües observem que existeix una correlació entre les mètriques automàtiques i manuals: en basc i castellà, l'avaluació manual també prioritza els resultats de les dades posteditades. Això ens indica que, per al nostre cas, aquestes mètriques automàtiques són fiables.
Conclusions
El conjunt de dades CONAN-EUS és un nou conjunt paral·lel de dades per a la creació de KN-EUS en basca i castellà, creat a través de la traducció automàtica i la postedició de la parella GD-KN en anglès original. Aquest recurs ha permès realitzar recerques innovadores des d'una perspectiva multilingüe i interlingüïstica en el camp de la creació de KNs.
Els experiments han demostrat que la generació de KN és millor si el model es refina amb dades posteditades, en lloc d'amb dades traduïdes automàticament. A més, els deficients resultats obtinguts en els experiments interlingüïstics en basc han incidit en la importància de disposar de dades d'entrenament en la llengua de destí, sobretot en les llengües de menys recursos com el basc. No obstant això, el mètode de transferència interlingüïstica continua sent un problema obert i complex d'indagació en els models creatius, la qual cosa deixa oberta la línia de treball per al futur.
Bibliografia
1] Davidson, T., Warmsley, D. Macy, M.W. i Weber, I. 2017. “Automated Hate Speech Detection and the Problem of Offensive Language”. International Conference on Web and Mitjà social.
[2] Basile, V. Bosco, C., Fersini, E. Noció, D., Patti, V. Marró, F.M., Rosso, P. I Sanguinetti, M. 2019. “SemEval-2019 Task 5: multilingual Detection of Hate Speech Against Etorkants and Women in Twitter”. International Workshop on Semantic Evaluation.
3) Schieb, C., i Preuss, M. 2016. “Governing hate speech by means of counterspeech on Facebook”. 66th ica annual conference, 1-23.
[4] Benesch, S. 2014. “Countering dangerous speech: New idees for genocide prevention”. SSRN 3686876.
5] Chung, I., Kuzmenko, E. Tekirocarriles, S. S., i Guerini, M. 2019. “CONAN - COunter NArratives through nichesourcing: a multilingual dataset of responses to fight en línia hate speech”. Proceedings of the 57th annual Meeting of the Association for Computational Linguistics, 2819–2829.
6] Chung, I. L., Teciroglu, S. M., Guerini. 2020. “Italian Counter Narrative Generation to Fight En línia Hate Speech”. Clic.
[7] Xue, L., Constant, N. Roberts, A., Carrer, M., "Al-Rfou, R. Siddhant A. El Bàrbar, A., i Raffel, C. 2020. “mT5: A Massively multilingual Pre-trained Text-to-Text Transformer”. North American Chapter of the Association for Computational Linguistics.
[8] Vaswani, A. Shazeer, N.M., Parmar, N., Uszkoreit, J. Jones, L. Gomez, A.N., Kaiser, L., i Polosukhin, I. 2017. “Attention is All you Need”. Neural Information Processing Systems
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










