



Azken urteetan, gorroto-diskurtsoaren (GD) presentzia areagotu da komunikabideetan, sare sozialek sortzen duten anonimizazioak bultzatuta. GDa “talde jakin baten aurkako gorrotoa adierazteko erabiltzen den hizkera” gisa definitu da, “talde horretako kideak iraindu, umiliatu edo gutxiesteko asmoa duen hizkera”[1].
Gaur egun, sare sozialek etengabe eguneratzen dituzte gorroto-mezuei aurre egiteko politikak, mezuak blokeatuz edo ezabatuz. Horrek dakarren lan-karga arintzeko, GDaren detekzio automatikoak badu interesa, datu-multzoak garatzen[2] eta ikasketa automatiko eta sakoneko teknikak erabiltzen baititu[1]. Hala ere, GDa moderatzeko metodo horiek eztabaida sortu dute, askok argudiatu baitute adierazpen-askatasuna mugatu dezaketela[3]. Alternatiba gisa, kontra-narratibak (KN) proposatu dira GDaren hedapenari aurre egin eta hura arintzeko neurri eraginkor gisa[4]. KNa gorroto-iruzkin bati erantzun ez-oldarkorra ematea da, argudioetan eta gertaeretan oinarritutako feedback ez-negatiboak dituena[3]. 1. irudian ikus daiteke adibide bat.

Testuinguru honetan, KNaren sorkuntza automatikoaren inguruko ikerketa nabarmen hazi da azken urteetan. Ikerketa honek hori jorratzen du, ataza hau lehen aldiz euskaraz eta gazteleraz aztertuz, horretarako hainbat baliabide eta metodo baliatuz.
Kontra-narratiben sorkuntza automatikoa
KNaren inguruko ikerketa nabarmen hazi da azkenaldian, baina bada zailtasun bat, ikerketa nabari oztopatzen duena: datu-urritasuna. Hain zuzen ere, horri aurre egiteko asmoarekin sortu zen CONAN, ikerketa honetarako oinarri gisa hartu den datu-multzoa. Bertan, Chungek eta kideek[5] islamofobiaren inguruko GD-KN bikoteak bildu zituzten, hiru hizkuntzetan. Horren bitartez, GD-KN bikoteen corpus sendo bat lortu zuten, ez-iragankorra, adituetan oinarritua eta eleaniztuna. Nichesourcing metodoaren bitartez, arloan aditu diren langileak kontratatu ziren datu-bilketa egiteko, KNaren kalitatea lehenetsiz eta datu ez-estereotipatu eta askotarikoak bilduz. Metodo horrek denbora asko behar du, eta garestia da; beraz, datu-kopurua handitzeko prozesu bat egin zen: hiru ez-adituk jatorrizko KN bakoitzaren bi parafrasi sortu zituzten, eta jatorrizko frantsesezko eta italierazko GD-KN bikoteak ingelesera itzuli zituzten. Horrela, 6654 GD-KN bikote bildu zituzten behin betiko ingelesezko corpus-zatian.
Datu-multzo horrek hainbat hizkuntza barneratzen dituen arren, aipatu behar da KNen sorkuntza automatikoari buruzko lanak nagusiki ingelesez egin direla, eskuz bildutako datuen eskasia eta hizkuntza-eredu sortzaileen urritasuna dela eta[6]. Guk dakigunaren arabera, lan gutxi argitaratu dira KNen sorkuntzaren inguruan ingelesaz besteko hizkuntzetan.
Datu-bilketa euskaraz eta gazteleraz
Beraz, lan gehienak ingelesez egin diren arlo honetan, ez da harritzekoa euskaraz eta gazteleraz ezer egin ez izana. Hutsune horrek bultzatuta, CONAN-EUS sortu genuen, KNen sorkuntza automatikorako baliagarria den euskarazko eta gaztelaniazko lehenengo datu-multzo paraleloa.
Horretarako, ingelesezko CONAN corpusaren 6654 GD-KN instantzia horiek automatikoki itzuli ziren Google APIaren bidez euskara eta gaztelaniara. Ondoren, automatikoki itzulitako gaztelaniazko eta euskarazko datu horiek 3 itzultzaile profesionalek posteditatu zituzten. Eskuzko postedizioa egitea erabaki zen, nahiz eta garestia izan, halako baliabide bat zerotik eraikitzea baino azkarragoa eta errazagoa baitzen. Gainera, jatorrizko ingelesezko CONANekiko datu-multzo paralelo bat izateak ikerketa berritzaileak egiteko aukera ematen du hizkuntza anitzeko eta hizkuntza arteko transferentzia-metodoak erabiliz.
Ikerketa honetan, CONAN-EUS erabili dugu KNak automatikoki sortzeko automatikoki itzulitako datuak erabiliz, baina baita posteditatutako datuak erabiliz ere. Horrela, gure helburua da itzulpen automatikoarekin eta posteditatutako datuekin sortutako kontra-narratibak alderatzea, postedizioak automatikoki sortutako KNetan duen eragina aztertzeko.
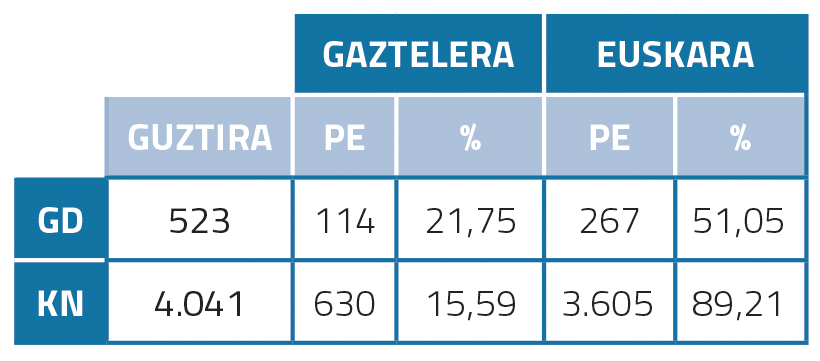
Euskarazko eta gaztelerazko postedizioa
Euskararen postedizio-estatistikei begiratuz gero (1. taula), ikus dezakegu ehunekoa oso altua dela: % 51,05, GDen kasuan; % 89,21, KNen kasuan. Hori itzulpen automatikoaren kalitate kaxkarraren ondorio izan daitekeelako hipotesia dugu. Gainera, KN gehiago posteditatu behar izan ziren GD baino, ziurrenik KNak orokorrean luzeagoak eta konplexuagoak direlako eta beraz postedizio gehiago behar izan zutelako. Gazteleraz, aldiz, GD eta KNen posteditatutako ehunekoak euskarazko zenbatekoak baino askoz ere baxuagoak dira: % 21,75 eta % 15,59. Ingelesa-gaztelera arteko itzulpen automatikoaren kalitatea altuagoa delako izan liteke hori.
Nola sortu eta ebaluatu testua automatikoki?
Ikerketa honetan, transformer motako mT5[7] hizkuntza-eredu eleaniztuna erabili dugu KNak automatikoki sortzeko. Eredu-mota horien arkitektura 2. irudian ikus daiteke. Eredu horiek gure datu-multzoaren zati batekin entrenatu ditugu; horrela, ikusi ez duen zatian GD bakoitzarentzat KN bat automatikoki sortu ahal izateko.
Sortutako KN horen kalitatea ebaluatzeko, hiru metrika automatiko erabili ditugu: BLEU (sarrera- eta irteera-testuen arteko n-gramen korrelazioa neurtzea), Rouge-L (erreferentzia eta irteera-testuaren arteko Azpisekuentzia Komun Luzeena (LCS) kalkulatzea) eta Repetition Rate (RR, sortutako testuan errepikatzen diren n-gramak kalkulatzea).
Postedizioaren eragina sorkuntzaren emaitzetan
Eredu elebakarrekin hasiz, emaitza nabarmenena da automatikoki itzulitako datuen postedizioak KNen sorkuntza hobetzen duela, bai euskaraz eta bai gaztelaniaz (2. taula). Gainera, es-PEek BLEU eta ROUGE-L neurketetan emaitza hobeak lortu arren, RR emaitzak hobeak dira ingelesezko datuekin (7,79 gazteleraz; 5,73 ingelesez). Horrek adierazten digu, gazteleraz n-grama gainjartze-metriketan lortu diren emaitza altuak errepikapenek sortu ahal izan dituztela. Euskararen emaitzetan, bestalde, eu-PEen emaitzak eu-MTrenak baino hobeak diren arren, ingelesa eta gazteleraren emaitzekin alderatuta nabarmen baxuagoak dira. Gure hipotesia da euskara ez dagoela ingelesa edo gaztelania bezain presente mT5 ereduaren hiztegian.
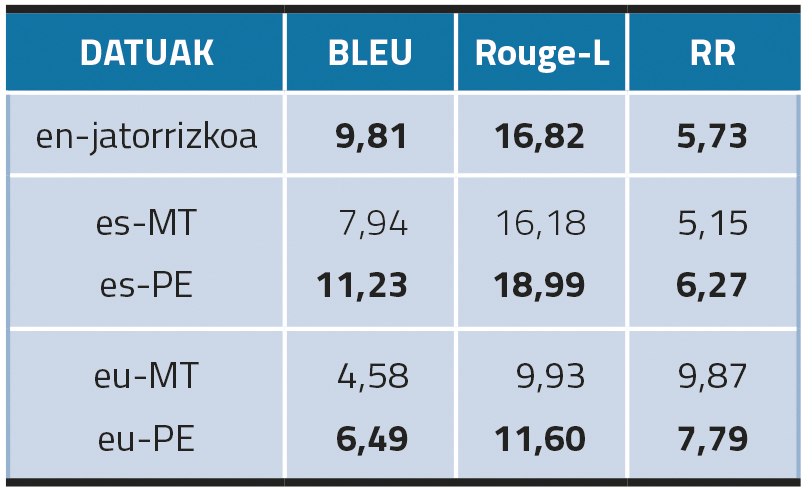
Labur esanda, ebaluazio automatikoko emaitzek erakusten dute eredu elebakarrekin egindako esperimentu hauetan (hots, xede-hizkuntzara itzulitako datu-multzoekin findutako ereduek) postedizio-pauso bat beharrezkoa dela emaitza optimoak lortzeko, automatikoki itzulitako datuekin findutako ereduek ez baitute errendimendu-maila bera lortzen.
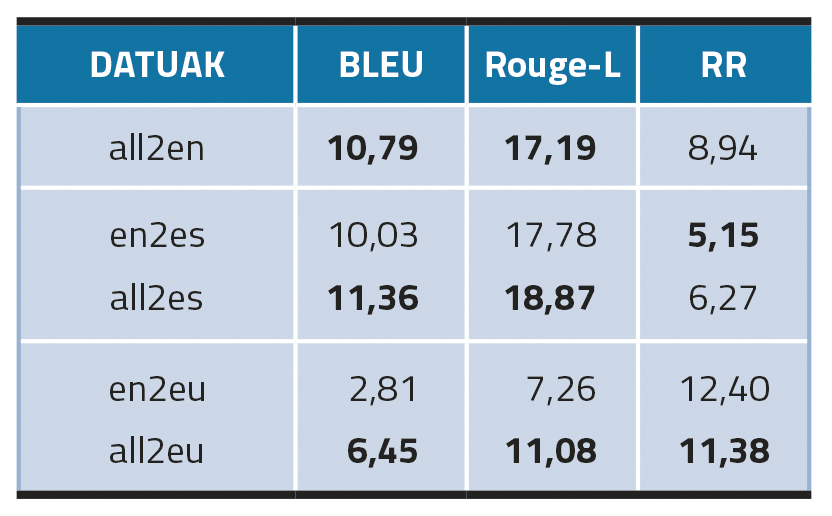
Eredu eleaniztunetan, ingelesaren eta gazteleraren kasuan (all2en eta all2es) ikusi da hiru hizkuntzetan fintzeak emaitza hobeak lortu dituela; bereziki, ingelesaren kasuan. Aldiz, hori ez da gertatzen euskararen kasuan (all2eu), eta horrek iradoki dezake hizkuntza anitzeko datu-handitzeak hobeto funtziona dezakeela egitura aldetik antzekoak diren hizkuntzetan; gure kasuan, ingelesean eta gaztelanian.
Hizkuntza arteko transferentzia-inguruneari dagokionez, metodo honek (en2es) ondo funtzionatu du gaztelaniaz, eredu elebakarren emaitzak (es-MT) gainditu baititu. Euskaraz, ordea, hizkuntza arteko eredu-transferentziak (en2eu) guztiz huts egiten du, eta eu-MTren nabarmen azpitik geratu da.
Eskuzko ebaluazioa
KN-sorkuntzan badago arazo bat: metrika automatikoen fidagarritasuna. Horregatik, eskuzko ebaluazio bat egin genuen, gure emaitzen fidagarritasuna aztertzeko.
Horretarako, bost irizpide aztertu ziren: erlazioa (GDa eta KNa erlazionatuta daude), espezifikotasuna (orokorra edo espezifikoa da KNa), aberastasuna (hizkuntza aldetik, nolako aberastasuna du), koherentzia (esaldiek zentzua dute elkarrekin) eta gramatikaltasuna (esaldien zuzentasun gramatikala). Ama-hizkuntza euskara edo gaztelera zuten bi hizkuntzalari ibili ziren lan horretan.
Horrela, eredu elebakarretan ikusi genuen badagoela korrelazio bat metrika automatiko eta eskuzkoen artean: euskaraz eta gazteleraz, eskuzko ebaluazioak ere posteditatutako datuen emaitzak hobesten ditu. Horrek adierazten digu, gure kasurako, metrika automatiko hauek fidagarriak direla.
Ondorioak
CONAN-EUS datu-multzoa KN-sorkuntzarako euskarazko eta gaztelaniazko datu-multzo paralelo berri bat da, jatorrizko ingelesezko 6654 GD-KN bikote automatikoki itzuliz eta profesionalen bitartez posteditatuz sortua. Baliabide honek ahalbidetu du hizkuntza anitzeko eta hizkuntza arteko ikuspegitik ikerketa berritzaileak egitea, KNen sorkuntzaren arloan.
Esperimentuek erakutsi dute KNen sorkuntza hobea dela eredua posteditatutako datuekin fintzen bada, automatikoki itzulitako datuekin findu beharrean. Gainera, hizkuntza arteko esperimentuetan euskaraz lortutako emaitza kaxkarrek xede-hizkuntzan entrenamendu-datuak edukitzearen garrantzia azpimarratu dute; euskara bezalako baliabide gutxiko hizkuntzetan, batez ere. Hala ere, hizkuntza arteko transferentzia-metodoak ikerketa-arazo ireki eta konplexua izaten jarraitzen du eredu sortzaileetan, eta horrek irekia uzten du etorkizunerako lan-ildoa.
Bibliografia
[1] Davidson, T., Warmsley, D., Macy, M.W., eta Weber, I. 2017. “Automated Hate Speech Detection and the Problem of Offensive Language”. International Conference on Web and Social Media.
[2] Basile, V., Bosco, C., Fersini, E., Nozza, D., Patti, V., Pardo, F.M., Rosso, P., eta Sanguinetti, M. 2019. “SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter”. International Workshop on Semantic Evaluation.
[3] Schieb, C., eta Preuss, M. 2016. “Governing hate speech by means of counterspeech on Facebook”. 66th ica annual conference, 1-23.
[4] Benesch, S. 2014. “Countering dangerous speech: New ideas for genocide prevention”. SSRN 3686876.
[5] Chung, Y., Kuzmenko, E., Tekiroğlu, S.S., eta Guerini, M. 2019. “CONAN - COunter NArratives through nichesourcing: a multilingual dataset of responses to fight online hate speech”. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2819–2829.
[6] Chung, Y. L., Tekiroglu, S. S., eta Guerini, M. 2020. “Italian Counter Narrative Generation to Fight Online Hate Speech”. CLiC-it.
[7] Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A., eta Raffel, C. 2020. “mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer”. North American Chapter of the Association for Computational Linguistics.
[8] Vaswani, A., Shazeer, N.M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., eta Polosukhin, I. 2017. “Attention is All you Need”. Neural Information Processing Systems.
Jaione Bengoetxea Azurmendi
HiTZ Hizkuntza Teknologiako Euskal Zentroa - Ixa, Euskal Herriko Unibertsitatea EHU
Itziar Gonzalez Dios
HiTZ Hizkuntza Teknologiako Euskal Zentroa - Ixa, Euskal Herriko Unibertsitatea EHU
Rodrigo Agerri Gascon
HiTZ Hizkuntza Teknologiako Euskal Zentroa - Ixa, Euskal Herriko Unibertsitatea EHU










