



A evolución da tradución vasca á luz da tecnoloxía

Tratemos por un momento de imaxinar a Joannes Leizarraga no século XVI, traballando para traducir a Biblia ao eúscaro. Probablemente había unha pluma, un frasco de tinta e papel encima da mesa, e un taco de latín á vez, colocado nunha especie de atril. Pasaron cinco séculos desde que se creou aquilo que se considera a primeira volta ao eúscaro, e as cousas cambiaron moi ben, xa que cambiaron... Pero quizá máis dun lector sorpréndase si dicímoslle que algúns tradutores que aínda están activos non fixeron as súas primeiras traducións en condicións tan diferentes. De feito, a maioría desas características que mencionamos até fai uns corenta anos formaban parte do día a día dos tradutores vascos: ademais do tema de tradución, do caderno e do bolígrafo ou ou lapis, só tiñan na mesa algún dicionario de consulta (e, por suposto, tamén de papel). A maior parte do proceso de traballo facíano a man e, despois de encher as páxinas do caderno de tímidos e dar por terminado o traballo, utilizaban a máquina de escribir para pasar a limpo a última versión.
Si desde entón tivésemos que contar cronoloxicamente estes cambios, non poderiamos deixar de mencionar algunhas das ferramentas que marcaron a actividade dos tradutores: computador, CD, Internet… E, por suposto, as tecnoloxías lingüísticas que foron evolucionando cada vez máis rapidamente desde hai décadas. Fagamos un repaso.
De escritorios físicos a virtuais
Os tradutores traballaban tal e como o describían até mediados da década de 1980. Con todo, naquela década chegaron computadores persoais, que pronto substituíron entre as ferramentas de traballo de moitos tradutores. De feito, non é de estrañar: hai unha diferenza entre traballar sobre follas de caderno en forma de borrador e ver sempre limpo na pantalla o que se escribe, mesmo si reescríbese a mesma frase catro ou cinco veces.
A revista de tradución Senez tamén se creou nesa mesma época, en 1984, e desde os seus inicios foi testemuña das principais tendencias que existiron entre os tradutores vascos. Neste sentido, pode observarse, por exemplo , que a palabra ordenador mencionouse por primeira vez en 1985,[1] mentres que a computadora se mencionou dous anos máis tarde,[2] como unha “ferramenta útil” para o traballo de tradutores. Ao principio non estaba dispoñible para todo o mundo, pero en poucos anos converteuse nunha ferramenta imprescindible (case).
Palabras subliñadas e consultas inmediatas
A transición á pantalla aínda non está feita por todos, e que é, e enseguida comezaron a aparecer outros recursos que modificarían por completo a actividade dos tradutores: correctores ortográficos e, en conxunto, dicionarios electrónicos. Xuxen foi o primeiro corrector ortográfico en eúscaro,[3] e publicouse en 1994, inicialmente en formato disquete. Calquera que se dedica á produción de textos sabe perfectamente a axuda que dan, xa que advirten de que se debe prestar atención subliñando as palabras que poden estar escritas incorrectamente. Pero Xuxen, ademais, non chegou a calquera época: só dúas décadas e media antes de que se crease o eúscaro unificado, e aínda se estaban establecendo normas de escritura. Tratouse, por tanto, dun excelente medio para axudar aos tradutores (e a moitos outros falantes) a difundilas.

En canto aos dicionarios, o Dicionario 3000 e o Dicionario electrónico de Elhuyar foron os primeiros en aparecer en formato CD, ambos en 1996. O traballo de consulta simplificouse enormemente: o que se podía buscar no papel só en función da entrada de dicionario, agora podíase buscar en función da categoría gramatical, das subáreas e outras características, moito máis rápido que até entón, e sen pasar de folla en liña.
Unha rede, un mundo en grande
Con todo, a onda de disquetes e CDs non durou moito: antes da chegada do novo milenio, Internet explotou e en pouco tempo converteuse no soporte principal de moitas fontes de información. A partir dese momento, ademais dos correctores e dicionarios, comezaron a aparecer outros recursos lingüísticos como os corpus consultables. Hoxe,[7] Elhuyar e o grupo de investigación Ixa puxeron a disposición dos tradutores o corpus estadístico ZT[8] e Corpeus…[9] Por dicilo dalgunha maneira, os corpus consultables permiten aos tradutores realizar procuras en grandes coleccións de textos e ver noutros moitos casos, ademais dos dicionarios.
Tamén poderían citarse máis recursos xerados de forma simultánea co inicio do milenio, pero traiamos polo menos outros dous a este breve repaso: Lista de correo ItzuL[10] e Euskalbar. [11] A primeira delas, fundada en 2004 pola asociación EIZIE, conta cunha tecnoloxía relativamente simple detrás da cal unha lista de correo é, en definitiva... Non é, por tanto, unha pequena axuda para os tradutores: si hai algunha dúbida que non se poida aclarar, aí teñen o foro para preguntar, e enseguida comeza o intercambio de opinións por e-mail. Euskalbar, pola súa banda, é un suplemento para instalalo no navegador, creado en 2006, que permite realizar consultas de idioma de forma simultánea en diferentes recursos. Na primeira versión, as procuras podíanse facer en catro dicionarios, pero a medida que se creaban novos recursos, os tentáculos do suplemento tamén se foron estendendo. Na actualidade, ItzuL conta con máis de 900 subscritores, e Euskalbarri dá acceso a máis de 70 recursos lingüísticos; non son cifras delicadas, non?
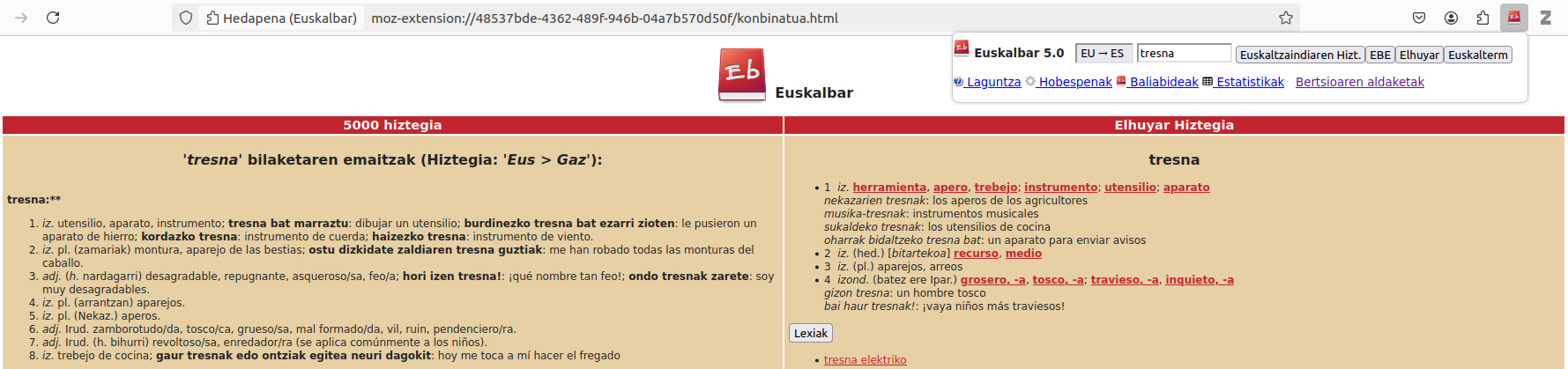
Memorias extracerebrales...
As memorias de tradución tamén comezaron a introducirse nos computadores dos tradutores vascos na época do cambio de milenio, e hoxe en día apenas hai tradutores que non as utilicen. En resumo, existen programas que almacenan de forma estruturada as obras dos tradutores e convértenas en memoria, colocando de forma paralela os textos dos dous idiomas: dividir o texto por segmentos (máis ou menos, frase por frase) e rexistrar a tradución de cada un deles por parte do usuario.
Pero non só iso: ademais de lembralo, tamén o lembran. De feito, a medida que se avanza no traballo, búscase en textos traducidos por un mesmo e, si obsérvase algunha vez que un segmento similar foi traducido, móstrase a tradución dese momento como suxestión.
En xeral, as memorias de tradución (e os glosarios que se utilizan xunto con elas) favorecen a coherencia interna dos textos traducidos e, si colócanse na pel dos tradutores de textos con estruturas máis ou menos ríxidas e repetitivas, enténdese facilmente por que se estenderon en tan pouco tempo. Con todo, mentiriamos si dixésemos que son apropiadas para todo tipo de traballos: para traducir poesía, por exemplo, é evidente que non tería moito sentido traducir o texto por partes. Por iso, e por outras razóns similares, tamén recibiron críticas, sobre todo porque limitan a creatividade, xa que si se observa o que se fixo con anterioridade resulta difícil pensar noutras traducións posibles.
...e cerebros fóra da persoa
E imos aos poucos á era da intelixencia artificial, á de hoxe. Hai que dicir que os tradutores automáticos xa non son tan novos (o primeiro para o par de idiomas castelán-euskera, Matxin,[12] creouse en 2006), pero no caso do eúscaro, os que estaban dispoñibles até hai pouco non tiñan unha calidade moi boa, e era case impensable que nunca fosen ferramentas de traballo no noso país. Con todo, en 2018 creouse Modela,[13] o primeiro tradutor neuronal en eúscaro, tras o cal chegaron os actuais: Elia,[14] Volver a España [16]
Non se pode dicir que todos os tradutores sexan afeccionados (si algúns se preocupan das memorias de tradución, algúns tradutores automáticos, que digo! ), pero cada vez teñen máis servizos de tradución integrados nas propias ferramentas de xestión de memorias de tradución: a prioridade son os textos previamente traducidos por un mesmo, pero se nas propias memorias non hai segmentos que se correspondan co que está a traducir, ofrécese a tradución automática como suxestión.
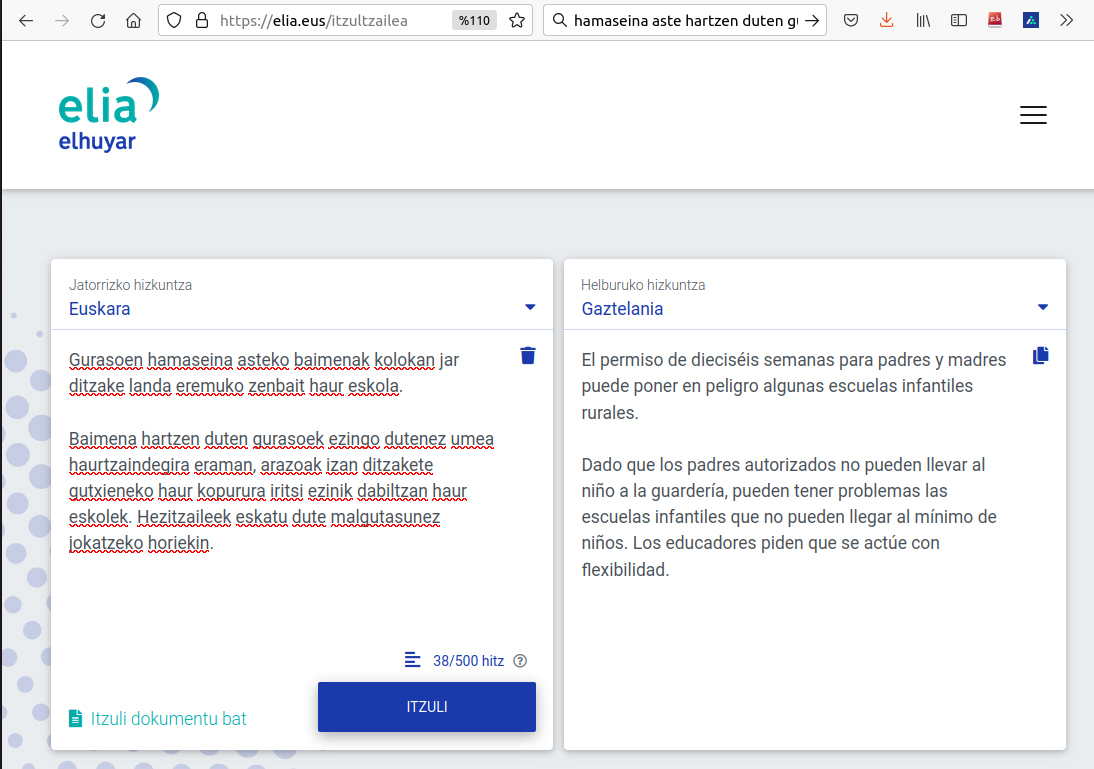
Alguén podería pensar para que está a persoa entón, si as traducións son producidas por un sistema automático… Pero, aínda que alguén teña dúbidas, aclaremos que a intervención da persoa segue sendo imprescindible no proceso de tradución, e será si queremos que o texto final teña o máximo nivel de calidade. De feito, si serven para traballar máis comodamente, pero o traballo de corrección (ou, como se di no caso da tradución automática, a postedición) é un traballo que debe facerse utilizando todos os sentidos para evitar que, entre resultados naturais, os cambios de significado escápense camuflados, que a linguaxe de texto completo sexa coherente e, en definitiva, que todos os matices que ten en conta un tradutor-profesional queden correctamente.
E a partir de agora, que?
Por tanto, unha cousa está clara: a comunidade de tradutores vascos viviu nas últimas décadas uns cambios tremendos e soubo adaptarse ao contemporáneo. Iso si, si todos eses cambios foron para ben ou para mal… Bo, a quen se lle pregunta: para os que lles gusta xogar coa lingua, poida que unha profesión que por natureza ten moito de creativo estea a converterse en algo mecánico e non humano, mentres que outros verán posibilidades no progreso tecnolóxico de reducir o seu fatiga mental e de facilitar os seus traballos.
En calquera caso, dada a velocidade dos cambios, teremos que seguir con coidado para aproveitar as oportunidades que se nos presentan, pero tamén para lembrar os riscos. Porque unha cousa é cambiar co tempo as tarefas que forman parte dunha profesión, e outra, moi distinta, dar por boa unha revolución incontrolada que afoga a nostalxia cara ás tecnoloxías dixitais, sen ter en conta as consecuencias que iso pode ter non só na profesión, senón na propia evolución do eúscaro; entre outras, nos hábitos de uso e na calidade dos textos.
Que diría Leizarraga si levantase a cabeza...?
Bibliografía
[1] Ibarzabal, A. 1985. “VIN. Verán de San Sebastián. Cursos”. Senez: revista de tradución e terminología, (3), 141-143. https://eizie.eus/eu/argitalpenak/senez/19850901 [2]
Mendiguren, X. 1987. “As casas do tradutor en Europa”. Senez: revista de tradución e terminología, (6), 241-243.
[3] Agirre, E., Alegria, I., Arregi, X., Artola, X. Díaz de Ilraza, A., Maritxalar, M., Sarasola, K. e Urkia, M. 1992. “Xuxen: a spelling checker/corrector for Basque based on two-level morphology”. Conference on Applied Natural Language Processing, 119-125.
[4] Unhas cinco. 1996. Dicionario 3000.
[5] Fundación Elhuyar. 1996. “Dicionario electrónico Elhuyar”. Elhuyar ciencia e tecnoloxía, (114), 44-47.
[6] Euskaltzaindia. 2002. Corpus estadístico do eúscaro do século XX.
[7] Sarasola, I., Salaburu, P., Landa, J. e Zabaleta, J. 2007. Prosa Modélica Hoxe (EPG).
[8] Fundación Elhuyar e o grupo Ixa. 2006. Corpus Científico-Tecnolóxico
[9] Fundación Elhuyar e Grupo Ixa 2007. Corpeus: internet como corpus en eúscaro.
[10] Asociación EIZIE (p.e. ). Lista de correo ItzuL.
[11] Euskalbar (consultado o 1 de xullo de 2024). Wikipedia.
[12] Maior, A., Alegria, I., Díaz de Ilraza, A., Labaka, G., Lersundi, M. e Sarasola, K. 2011. “Matxin, an open-source rule-based machine translation system for Basque”. Machine Translation, (25)
[13] Etchegoyhen, T. Martínez, E., Azpeitia, A., Labaka, G., Alegría, I. Cort-é, I., Palacio, A., Ellakuria, I., Martin, M. e Calonge, E. 2018. “Neural Machine Translation of Basque”. Proceedings of the 21st annual Conference of the European Association for Machine Translation, 139-148.
[14] Fundación Elhuyar. 2021. Elia.eus.
[15] Goberno Vasco. 2019. Itzuli.eus.
[16] Vicomtech. 2019. Batua.eus.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







