



La evolución de la traducción vasca a la luz de la tecnología

Tratemos por un momento de imaginar a Joannes Leizarraga en el siglo XVI, trabajando para traducir la Biblia al euskera. Probablemente había una pluma, un frasco de tinta y papel encima de la mesa, y un taco de latín a la par, colocado en una especie de atril. Han pasado cinco siglos desde que se creó aquello que se considera la primera vuelta al euskera, y las cosas han cambiado muy bien, ya que han cambiado... Pero quizá más de un lector se sorprenda si le decimos que algunos traductores que todavía están activos no hicieron sus primeras traducciones en condiciones tan diferentes. De hecho, la mayoría de esas características que hemos mencionado hasta hace unos cuarenta años formaban parte del día a día de los traductores vascos: además del tema de traducción, del cuaderno y del bolígrafo o o lápiz, solo tenían en la mesa algún diccionario de consulta (y, por supuesto, también de papel). La mayor parte del proceso de trabajo lo hacían a mano y, después de llenar las páginas del cuaderno de tímidos y dar por terminado el trabajo, utilizaban la máquina de escribir para pasar a limpio la última versión.
Si desde entonces tuviéramos que contar cronológicamente estos cambios, no podríamos dejar de mencionar algunas de las herramientas que han marcado la actividad de los traductores: ordenador, CD, Internet… Y, por supuesto, las tecnologías lingüísticas que han ido evolucionando cada vez más rápidamente desde hace décadas. Hagamos un repaso.
De escritorios físicos a virtuales
Los traductores trabajaban tal y como lo describían hasta mediados de la década de 1980. Sin embargo, en aquella década llegaron ordenadores personales, que pronto sustituyeron entre las herramientas de trabajo de muchos traductores. De hecho, no es de extrañar: hay una diferencia entre trabajar sobre hojas de cuaderno en forma de borrador y ver siempre limpio en la pantalla lo que se escribe, incluso si se reescribe la misma frase cuatro o cinco veces.
La revista de traducción Senez también se creó en esa misma época, en 1984, y desde sus inicios ha sido testigo de las principales tendencias que han existido entre los traductores vascos. En este sentido, puede observarse, por ejemplo, que la palabra ordenador se mencionó por primera vez en 1985,[1] mientras que la computadora se mencionó dos años más tarde,[2] como una “herramienta útil” para el trabajo de traductores. Al principio no estaba disponible para todo el mundo, pero en pocos años se convirtió en una herramienta imprescindible (casi).
Palabras subrayadas y consultas inmediatas
La transición a la pantalla aún no está hecha por todos, y qué es, y enseguida comenzaron a aparecer otros recursos que modificarían por completo la actividad de los traductores: correctores ortográficos y, en conjunto, diccionarios electrónicos. Xuxen fue el primer corrector ortográfico en euskera,[3] y se publicó en 1994, inicialmente en formato disquete. Cualquiera que se dedica a la producción de textos sabe perfectamente la ayuda que dan, ya que advierten de qué se debe prestar atención subrayando las palabras que pueden estar escritas incorrectamente. Pero Xuxen, además, no llegó a cualquier época: solo dos décadas y media antes de que se creara el euskera unificado, y todavía se estaban estableciendo normas de escritura. Se trató, por tanto, de un excelente medio para ayudar a los traductores (y a muchos otros hablantes) a difundirlas.

En cuanto a los diccionarios, el Diccionario 3000 y el Diccionario electrónico de Elhuyar fueron los primeros en aparecer en formato CD, ambos en 1996. El trabajo de consulta se simplificó enormemente: lo que se podía buscar en el papel solo en función de la entrada de diccionario, ahora se podía buscar en función de la categoría gramatical, de las subáreas y otras características, mucho más rápido que hasta entonces, y sin pasar de hoja en línea.
Una red, un mundo en grande
Sin embargo, la ola de disquetes y CDs no duró mucho: antes de la llegada del nuevo milenio, Internet explotó y en poco tiempo se convirtió en el soporte principal de muchas fuentes de información. A partir de ese momento, además de los correctores y diccionarios, comenzaron a aparecer otros recursos lingüísticos como los corpus consultables. Hoy,[7] Elhuyar y el grupo de investigación Ixa pusieron a disposición de los traductores el corpus estadístico ZT[8] y Corpeus…[9] Por decirlo de alguna manera, los corpus consultables permiten a los traductores realizar búsquedas en grandes colecciones de textos y ver en otros muchos casos, además de los diccionarios.
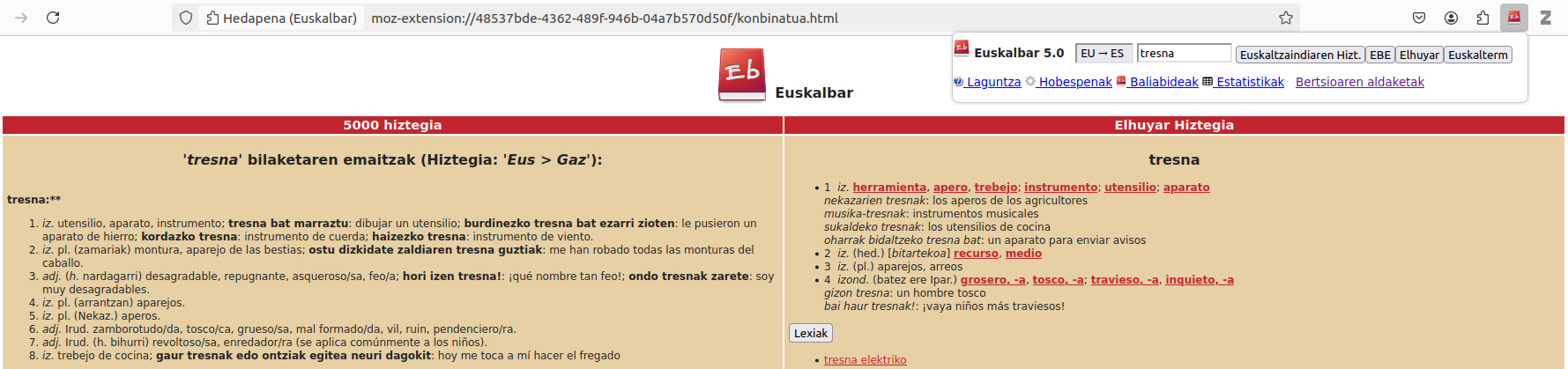
También podrían citarse más recursos generados de forma simultánea con el inicio del milenio, pero traigamos al menos otros dos a este breve repaso: Lista de correo ItzuL[10] y Euskalbar. [11] La primera de ellas, fundada en 2004 por la asociación EIZIE, cuenta con una tecnología relativamente simple detrás de la cual una lista de correo es, en definitiva... No es, por tanto, una pequeña ayuda para los traductores: si hay alguna duda que no se pueda aclarar, ahí tienen el foro para preguntar, y enseguida comienza el intercambio de opiniones por e-mail. Euskalbar, por su parte, es un suplemento para instalarlo en el navegador, creado en 2006, que permite realizar consultas de idioma de forma simultánea en diferentes recursos. En la primera versión, las búsquedas se podían hacer en cuatro diccionarios, pero a medida que se creaban nuevos recursos, los tentáculos del suplemento también se han ido extendiendo. En la actualidad, ItzuL cuenta con más de 900 suscriptores, y Euskalbarri da acceso a más de 70 recursos lingüísticos; no son cifras delicadas, ¿no?
Memorias extracerebrales...
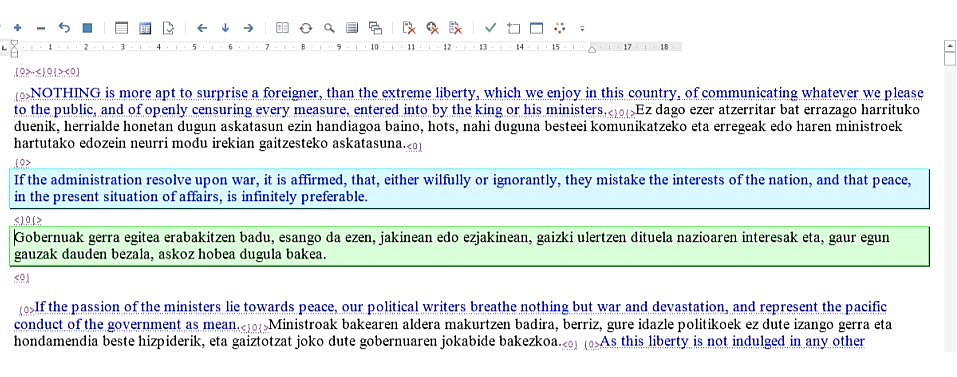
Las memorias de traducción también comenzaron a introducirse en los ordenadores de los traductores vascos en la época del cambio de milenio, y hoy en día apenas hay traductores que no las utilicen. En resumen, existen programas que almacenan de forma estructurada las obras de los traductores y las convierten en memoria, colocando de forma paralela los textos de los dos idiomas: dividir el texto por segmentos (más o menos, frase por frase) y registrar la traducción de cada uno de ellos por parte del usuario.
Pero no solo eso: además de recordarlo, también lo recuerdan. De hecho, a medida que se avanza en el trabajo, se busca en textos traducidos por uno mismo y, si se observa alguna vez que un segmento similar ha sido traducido, se muestra la traducción de ese momento como sugerencia.
En general, las memorias de traducción (y los glosarios que se utilizan junto con ellas) favorecen la coherencia interna de los textos traducidos y, si se colocan en la piel de los traductores de textos con estructuras más o menos rígidas y repetitivas, se entiende fácilmente por qué se han extendido en tan poco tiempo. Sin embargo, mentiríamos si dijéramos que son apropiadas para todo tipo de trabajos: para traducir poesía, por ejemplo, es evidente que no tendría mucho sentido traducir el texto por partes. Por ello, y por otras razones similares, también han recibido críticas, sobre todo porque limitan la creatividad, ya que si se observa lo que se ha hecho con anterioridad resulta difícil pensar en otras traducciones posibles.
...y cerebros fuera de la persona
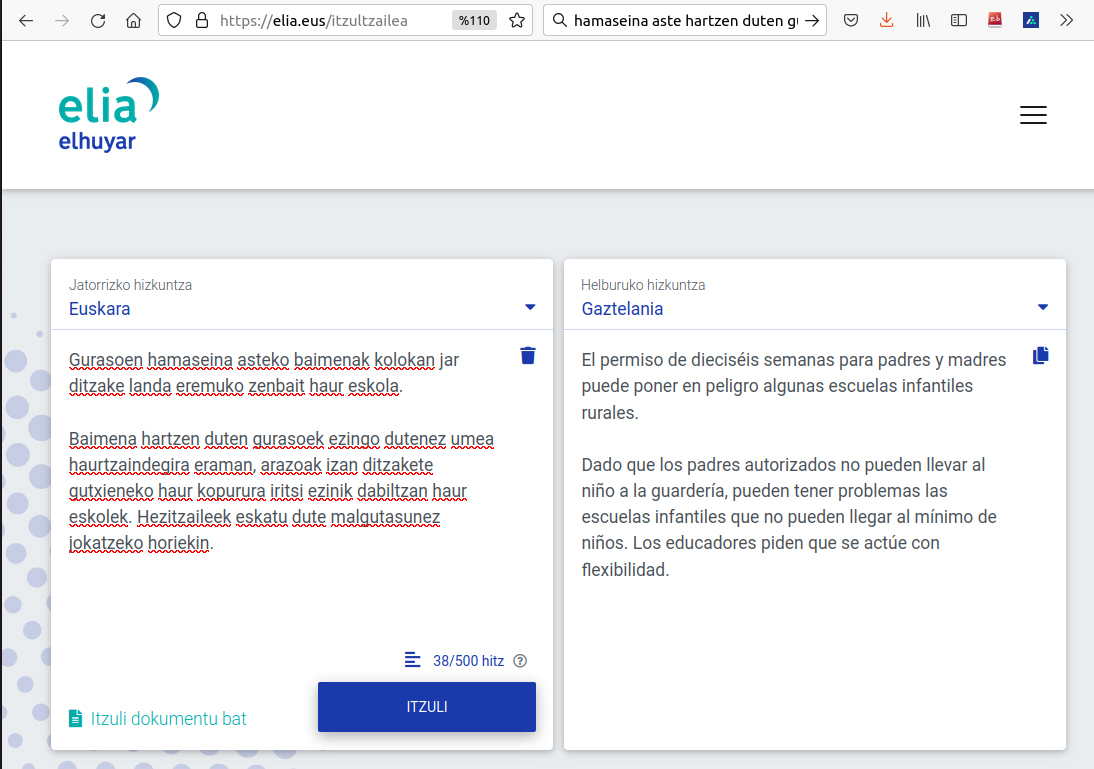
Y vamos poco a poco a la era de la inteligencia artificial, a la de hoy. Hay que decir que los traductores automáticos ya no son tan nuevos (el primero para el par de idiomas castellano-euskera, Matxin,[12] se creó en 2006), pero en el caso del euskera, los que estaban disponibles hasta hace poco no tenían una calidad muy buena, y era casi impensable que nunca hubieran sido herramientas de trabajo en nuestro país. Sin embargo, en 2018 se creó Modela,[13] el primer traductor neuronal en euskera, tras el cual han llegado los actuales: Elia,[14] Volver a España [16]
No se puede decir que todos los traductores sean aficionados (si algunos se preocupan de las memorias de traducción, algunos traductores automáticos, ¡qué digo! ), pero cada vez tienen más servicios de traducción integrados en las propias herramientas de gestión de memorias de traducción: la prioridad son los textos previamente traducidos por uno mismo, pero si en las propias memorias no hay segmentos que se correspondan con lo que está traduciendo, se ofrece la traducción automática como sugerencia.
Alguien podría pensar para qué está la persona entonces, si las traducciones son producidas por un sistema automático… Pero, aunque alguien tenga dudas, aclaremos que la intervención de la persona sigue siendo imprescindible en el proceso de traducción, y será si queremos que el texto final tenga el máximo nivel de calidad. De hecho, sí sirven para trabajar más cómodamente, pero el trabajo de corrección (o, como se dice en el caso de la traducción automática, la postedición) es un trabajo que debe hacerse utilizando todos los sentidos para evitar que, entre resultados naturales, los cambios de significado se escapen camuflados, que el lenguaje de texto completo sea coherente y, en definitiva, que todos los matices que tiene en cuenta un traductor-profesional queden correctamente.
¿Y a partir de ahora, qué?
Por lo tanto, una cosa está clara: la comunidad de traductores vascos ha vivido en las últimas décadas unos cambios tremendos y ha sabido adaptarse a lo contemporáneo. Eso sí, si todos esos cambios han sido para bien o para mal… Bueno, a quién se le pregunta: para los que les gusta jugar con la lengua, puede que una profesión que por naturaleza tiene mucho de creativo se esté convirtiendo en algo mecánico y no humano, mientras que otros verán posibilidades en el progreso tecnológico de reducir su fatiga mental y de facilitar sus trabajos.
En cualquier caso, dada la velocidad de los cambios, tendremos que seguir con cuidado para aprovechar las oportunidades que se nos presentan, pero también para recordar los riesgos. Porque una cosa es cambiar con el tiempo las tareas que forman parte de una profesión, y otra, muy distinta, dar por buena una revolución incontrolada que ahoga la nostalgia hacia las tecnologías digitales, sin tener en cuenta las consecuencias que ello puede tener no solo en la profesión, sino en la propia evolución del euskera; entre otras, en los hábitos de uso y en la calidad de los textos.
¿Qué diría Leizarraga si levantara la cabeza...?
Bibliografía
[1] Ibarzabal, A. 1985. “VI. Verano de San Sebastián. Cursos”. Senez: revista de traducción y terminología, (3), 141-143. https://eizie.eus/eu/argitalpenak/senez/19850901 [2]
Mendiguren, X. 1987. “Las casas del traductor en Europa”. Senez: revista de traducción y terminología, (6), 241-243.
[3] Agirre, E., Alegria, I., Arregi, X., Artola, X. Díaz de Ilraza, A., Maritxalar, M., Sarasola, K. y Urkia, M. 1992. “Xuxen: a spelling checker/corrector for Basque based on two-level morphology”. Conference on Applied Natural Language Processing, 119-125.
[4] Unas cinco. 1996. Diccionario 3000.
[5] Fundación Elhuyar. 1996. “Diccionario electrónico Elhuyar”. Elhuyar ciencia y tecnología, (114), 44-47.
[6] Euskaltzaindia. 2002. Corpus estadístico del euskera del siglo XX.
[7] Sarasola, I., Salaburu, P., Landa, J. y Zabaleta, J. 2007. Prosa Modélica Hoy (EPG).
[8] Fundación Elhuyar y el grupo Ixa. 2006. Corpus Científico-Tecnológico
[9] Fundación Elhuyar y Grupo Ixa 2007. Corpeus: internet como corpus en euskera.
[10] Asociación EIZIE (p.e. ). Lista de correo ItzuL.
[11] Euskalbar (consultado el 1 de julio de 2024). Wikipedia.
[12] Mayor, A., Alegria, I., Díaz de Ilraza, A., Labaka, G., Lersundi, M. y Sarasola, K. 2011. “Matxin, an open-source rule-based machine translation system for Basque”. Machine Translation, (25)
[13] Etchegoyhen, T. Martínez, E., Azpeitia, A., Labaka, G., Alegría, I. Cort-es, I., Palacio, A., Ellakuria, I., Martin, M. y Calonge, E. 2018. “Neural Machine Translation of Basque”. Proceedings of the 21st annual Conference of the European Association for Machine Translation, 139-148.
[14] Fundación Elhuyar. 2021. Elia.eus.
[15] Gobierno Vasco. 2019. Itzuli.eus.
[16] Vicomtech. 2019. Batua.eus.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







