



Jetez le verset et nous l'analyserons

Dans les travaux qui ont lieu dans le groupe IXA de la Faculté d'Informatique de l'UPV/EHU, combinant le langage et l'informatique, ces dernières années, nous travaillons également sur le thème du bertsolarisme. Ainsi, nous avons récemment présenté en collaboration avec l'Association Bertsozale l'ardoise numérique (avec des chercheurs de rimes et synonymes, vérificateurs de mesures, etc.) pour aider à la production de berthos (bientôt disponible aussi pour mobiles). De même, dans le domaine de la création linguistique, on travaille à la création automatique de vers. Bien que nous ayons fait les premiers pas, avant de prendre des mesures plus déterminées, nous avons essayé d'analyser les berthos en détail, car leur analyse approfondie peut entraîner une meilleure création.
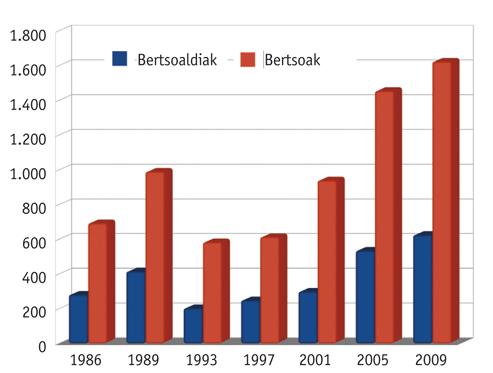
Pour la réalisation de ces études a été basée sur le corpus compilé et classé par le Centre de documentation Xenpelar. Le corpus utilisé par nous couvre les berthos des principaux tournois organisés entre 1986 et 2009. Ce corpus est composé de 6.887 versets classés en 2600 versets. Comme on peut le voir dans la figure 1, les versets - et donc les versets - sont de plus en plus nombreux.
L'analyse a été réalisée à différents niveaux, en tenant compte des principales caractéristiques du verset: rimes, mesures, mélodies, mots, catégories morphosyntaxiques et utilisation de l'euskera unifié.
Rimes
Pour analyser quels sont les rimes et les pieds les plus utilisés, nous avons pris en compte des mesures qui ne rimes que par des lignes paires, car avec ce type de vers nous obtenons 94% du corpus et que la nécessité d'obtenir des rimes de mesures plus irrégulières ajoutait une complexité qui ne valait pas la peine pour cette étude.
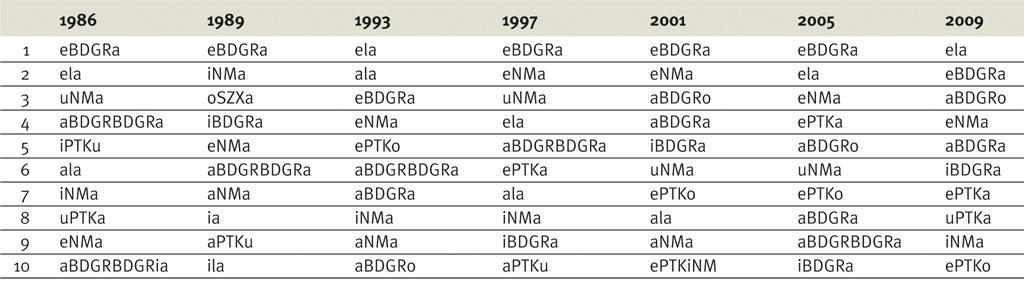
Comme on peut le voir dans le tableau de la figure 2, le championnat n'est pas toujours le même pour les rimes les plus utilisés, bien que la tendance à utiliser les unes soit plus grande que les autres (par exemple, la rime eBGD apparaît en première position).
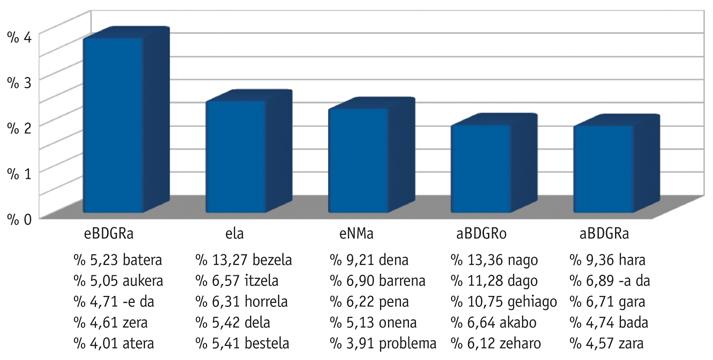
En prenant le corpus dans son intégralité (en tenant compte de tous les versets des sept tournois), nous avons également étudié quels sont les rimes et les pieds les plus utilisés (données que l'on peut voir dans la figure 3; le nombre qui apparaît à gauche des pieds indique la proportion dans laquelle ce pied a été utilisé dans ce rime, par exemple, dans 13,27% des cas où le rime "ela" a été utilisé le pied sélectionné. Notez que dans le corpus la plupart des versets appartiennent aux deux derniers tournois, de sorte que les données de ces deux tournois auront plus de poids dans ces mesures.
D'autre part, les trois pieds qui se répètent le plus dans tout le corpus et, par conséquent, les plus utilisés sont les mots "veille", "sans" et "en regardant".
Mesures à prendre
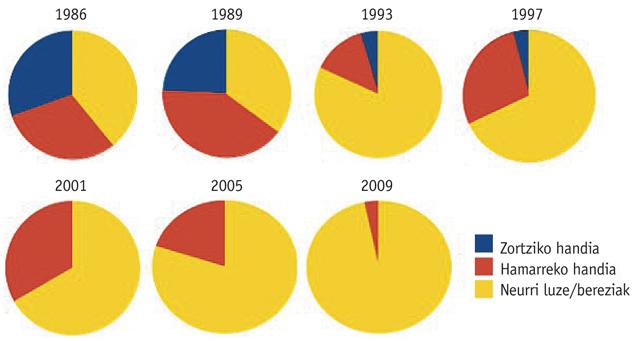
En ce qui concerne l'analyse des mesures, nous avons analysé quelles sont les plus utilisées dans l'exercice de la prison, seul exercice ponctuable qui est chanté librement.
Comme on peut le voir sur le graphique de la figure 4, la tendance à des mesures longues et spéciales augmente, comme on s'y attend. Il convient également de noter qu'à partir du championnat de l'année 2001 (selon les données du corpus) il n'a pas été chanté dans le zortziko majeur, et qu'en 2009 on n'a guère utilisé la dixième partie (3%). Avec ces données, il semble que dans les prisons du futur ils n'auront pas la place du zortziko majeur et du décimal.
Mélodies
Dans cette étude, seuls les versets qui sont chantés dans la mélodie libre ont été pris en compte, laissant les mélodies utilisées dans les réponses de points.
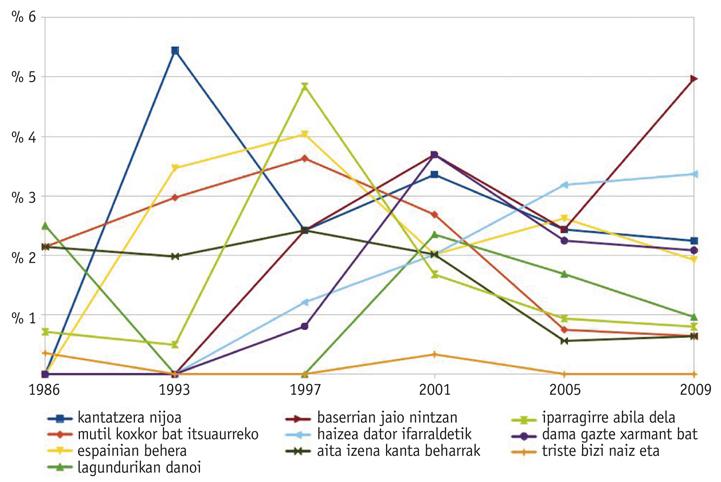
La figure 5 montre l'évolution en pourcentage de l'utilisation de dix mélodies fréquentes. Il convient de noter le faible usage de la mélodie bien connue "Triste bizi naiz eta", et le remarquable essor des mélodies "Haizea dator ifarralde" et "Baserrian jaio naiz". (Note: Nous n'avons pas tenu compte du championnat de l'année 1989 parce que près du quart des Berthsos qui apparaissent dans le corpus n'ont pas la mélodie documentée.)
Mots les plus utilisés
Quant aux mots utilisés pour le bertso, le graphique de la figure 6 montre la proportion dans laquelle le bertso peut être composé en utilisant un certain nombre de slogans. On peut y observer que les 500 slogans les plus utilisés du corpus de vers sont suffisants pour former 70% d'un verset et les 1000 slogans les plus utilisés pour compléter 80% du verset. D'une manière plus claire, un élève d'euskera comprendrait 70% d'un bertso (sans tenir compte des entraves par l'oralité ni des limites d'intelligibilité de la syntaxe) en connaissant les 500 lemmes les plus utilisés dans ce bertso corpus.
D'autre part, il faut dire que ce corpus de compétitions respecte la loi du Zipf. Du point de vue du traitement de la langue, la loi de Zipf stipule que si, prenant n'importe quel corpus de la langue naturelle, le mot le plus représenté est X fois, le mot suivant le plus fréquent apparaîtra X /2 fois et le suivant X /4 fois et le suivant X /8 fois...
Catégories morphosyntaxiques
Les catégories morphosyntaxiques des mots ont également été analysées pour savoir quelles sont les plus utilisées et voir si des changements significatifs ont eu lieu chaque année.

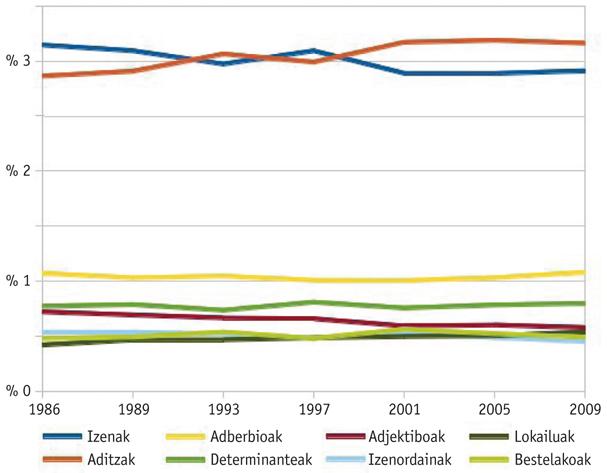
Comme on peut le voir dans la figure 7, les noms et verbes (y compris les verbes principaux, les auxiliaires et les synthétiques à la fois) sont les plus utilisés différemment. L'évolution de l'utilisation des adjectifs nous semble également importante, puisque le championnat a baissé par championnat, même si la différence n'est pas très significative.
Utilisation du basque unifié
Enfin, pour connaître l'usage de l'euskera unifié dans le corpus de vers, nous avons analysé le corpus avec le lematizador du groupe IXA, en tenant compte de l'évolution des mots que connaît le lematizador.
Comme on peut le voir sur le graphique 8, le nombre de termes connus a augmenté de championnat en championnat. Dans le championnat de 2005, avec 89%, on observe que même si en 2009 cette proportion descend légèrement, elle reste similaire. Les raisons pour lesquelles les lematizadores du groupe IXA ne connaissent pas les mots peuvent être très diverses, alors que nos estimations indiquent que l'utilisation de l'euskera batua est celle qui se produit le plus (80%). Le reste sont des noms propres inconnus (13%), des carnavals (6%) ou des erreurs de transcription (1%). Selon ces données, nous ne pouvons pas garantir que l'augmentation des mots connus est due à une plus grande utilisation de l'euskera batua (et non par exemple à une moindre utilisation de l'espagnol), mais notre intuition et un échantillon que nous avons analysé à la main nous a confirmé le sentiment que c'est la tendance.
Les mesures des derniers tournois, à notre avis, suggèrent deux types de prévisions, même si les données que nous avons ne sont pas assez précises et il nous semble qu'il est trop tôt pour tirer des conclusions: cette tendance sera inversée et les bertsolaris réutiliseront davantage le langage des dialectes; ou la limite supérieure (90%) dans l'utilisation de l'euskera unifié continuera autour de cette limite. En tout cas, nous pensons que le plus difficile est que l'utilisation du basque unifié monte encore plus dans une activité orale comme le bertsolarisme.
Conclusions

L'analyse statistique des Berthois des sept derniers tournois principaux nous a permis de montrer quelques tendances. Bien qu'il vaille la peine de faire une analyse plus tranquille et exhaustive de ces données, le premier nous a aussi laissé quelques choses significatives. Dans le choix de la mesure et dans l'utilisation de l'euskera unifié, par exemple, nous a servi à confirmer que les intuitions précédentes étaient vraies: il y a de plus en plus de propension aux mesures spéciales et longues, et même dans l'utilisation de l'euskera unifié il semble que l'augmentation a été pratiquement constante. Quant aux mélodies, il semble y avoir une tendance à une utilisation de plus en plus réduite des mélodies, mais dans ces données nous avons été révélés une caractéristique que nous n'osons pas tirer des conclusions à ce sujet.
Ces tendances sont-elles maintenues dans la compétition de cette année ou investies ? Et dans les suivants? Quelles autres interprétations intéressantes peuvent être faites à partir du corpus de vers? Quelles conséquences tireriez-vous d'analyser les berthos qui ne sont pas de compétition ? Et comparer ceux de compétition avec ceux de compétition ?
Il reste encore beaucoup à faire dans ce domaine, mais nous pensons que l'importance de continuer à documenter correctement les berthos pour réaliser une analyse exhaustive de la production de berthsos est indéniable si l'on veut voir comment évoluent dans les années à venir les tendances mentionnées dans cet article et d'autres qui méritent d'être examinées d'une manière plus tranquille.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










