



Langue Basque et Ingénierie Linguistique
Étapes pour organiser l'industrie linguistique
A moyen terme, la communication entre personnes et machines peut être réalisée dans notre langue, pas dans celle des machines. Il ne fait aucun doute que le langage naturel est la clé de notre vie quotidienne. Non et quand nous disons que votre traitement informatique devient de plus en plus important. Chaque jour, les bases de données documentaires se développent, changent les façons de communiquer avec les ordinateurs et numérisent tous les systèmes multimédia. Par conséquent, il nous est indispensable d'explorer les voies pour travailler informatiquement le langage naturel. Certes, les technologies linguistiques sont fondamentales dans ce que nous appelons société de l'information et de la communication.
Ces outils seront limités et travailleront toujours avec un degré d'erreur, mais néanmoins ils nous aideront beaucoup. D'une part, ils seront économiquement rentables; il est moins cher de corriger un brouillon de traduction avec des erreurs que de traduire tout le texte. D'autre part, ces outils permettront d'améliorer la communication entre les humains (par exemple, parler au téléphone avec une personne qui utilise une autre langue, traduisant les mots un par un système).
Il existe actuellement plusieurs applications linguistiques disponibles : correcteurs orthographiques et stylistiques, consultations de vocabulaire en ligne, aides à la traduction, moteurs de recherche Internet, systèmes qui convertissent la parole en texte, lecteurs de textes, systèmes d’apprentissage de seconde langue, etc.
Cependant, la plupart de ces systèmes fonctionnent uniquement en anglais, pas dans d'autres langues. Les autres langues doivent faire un grand effort pour ne pas rester en arrière, plus encore le basque et le reste des langues minoritaires.
Si vous regardez la page Internet du service Natural Language Software Registry, nous recevrons des informations sur le programme 167 actuellement disponible pour travailler en langues (voir figure 1). Parmi eux, 75% sont disponibles en anglais et seulement 30% peuvent être utilisés dans n'importe quelle langue. La plupart des applications qui peuvent être trouvées sur le marché visent des langues “grandes”, principalement l’anglais, mais aussi, bien qu’en arrière-plan, le français, l’allemand et l’espagnol.
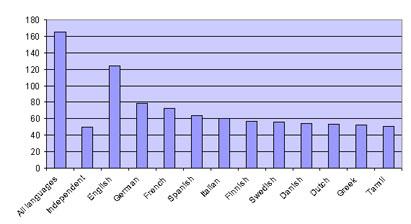
Application de l'ingénierie linguistique
En près de 50 ans d'histoire, le PTP a connu de grands hauts et des bas. Aux moments euphoriques où l'on considérait qu'ils étaient sur le point d'atteindre des objectifs fascinants, des moments pragmatiques ont été suivis à plusieurs reprises pour abaisser les oreilles et les limiter à des objectifs inférieurs mais abordables. Le jour où les ordinateurs comprendront la langue telle que nous la comprenons, les gens sont encore loin, mais cela ne signifie pas que des applications intéressantes et très utiles ne peuvent pas être faites.
Cependant, pour le développement de ces applications, il est nécessaire de partir d'une base solide. En général, nous pouvons représenter la structure des technologies linguistiques avec une sorte de pyramide.
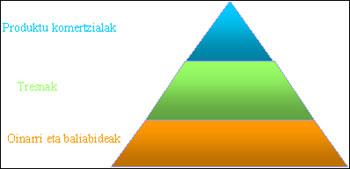
À la base de cette pyramide se trouvent les ressources de base nécessaires pour travailler en ingénierie linguistique. Ces ressources nous permettront de développer des outils qui, une fois développés, nous permettent de lancer des produits commerciaux travaillant dans différents domaines de l'ingénierie linguistique. Il faut garder à l'esprit, cependant, que le chemin inverse n'est pas possible si nous ne voulons pas construire la maison par le toit.
Quelle infrastructure est nécessaire pour développer des applications ?
Les applications, bien sûr. Nous vivons dans une société multilingue et rêvons d'outils qui nous aident à ce plurilinguisme : traduction automatique en basque, connaissance de la
parole, correcteurs de style. Mais si nous les créons, nous aurons d'abord besoin d'une base solide. Par exemple, pour le développement d'un outil semi-automatique qui peut aider les traducteurs, nous devons d'abord développer une série de ressources et d'outils.
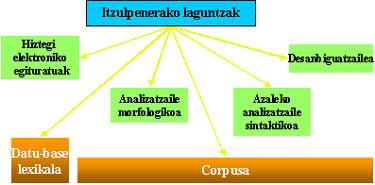
Dans le cas de l'euskera, les principaux outils et ressources de base que nous avons développés jusqu'ici sont :
Outils et outils
- Un outil qui nous transforme en texte écrit. Au Pays Basque, il existe deux ou trois groupes de recherche qui travaillent sur ce sujet - l'un à l'École d'Ingénierie de Bilbao, le Conseil, l'autre à la Faculté des Sciences de Leioa.
- Analyseur morphologique. Dans toutes les langues, il est nécessaire et indispensable dans l'euskera, car il est une langue pliée et autocollant. La fonction de l'analyseur (et synthétiseur) morphologique
est de connaître (et composer) les morphèmes formant la forme de mot et de fournir l'information morphologico-lexicale correspondant à chaque morphème. Cet outil est basé sur des applications telles que correcteur orthographique, reconnaissance optique de caractères (OCR) et des applications plus sophistiquées telles que la traduction automatique. L'analyseur/synthétiseur morphologique
général pour l'euskera est réalisé et Xuxen est l'essence du correcteur orthographique en euskera. - Lematizador/étiqueteur. Le lemmatiseur/étiqueteur dérive de l'analyseur morphologique et fournit la devise et la catégorie d'une forme de mot pour éviter ou réduire l'ambiguïté dans le contexte.Bien que la tâche principale soit la déviation, une autre tâche d'un tel instrument est l'identification d'unités lexicales plurilingues (locutions, unions de mots, noms de personnes, etc.). ). ). Les applications des lematizadores sont très intéressantes : indexation — dans les chercheurs d'Internet, par exemple — terminologie et lexicographie, etc. Le lematizador général d'euskera a été dénommé FormatLem et est déjà implanté dans plusieurs chercheurs d'internet.

- Analyseur syntaxique. La fonction des analyseurs syntaxiques est de connaître les composants syntaxiques des textes : phrases, syntagmes
nominaux, noms et amis, etc. L'analyse sera basée sur le lexique et la grammaire, qui définiront les caractéristiques des mots et les possibles compositions des structures syntaxiques. Il est également un outil indispensable dans de nombreuses applications linguistiques, telles que la traduction automatique. Dans le cas de l'euskera, nous avons élaboré un analyseur syntaxique général de surface — NouveauMG —, et les études qui nous donneront l'arbre syntaxique complet sont assez avancées.
Ressources et bases linguistiques
Nous avons d'abord besoin d'outils pour développer des applications, mais leur base est les ressources. Les principales sont:
- Base de données lexicale et description de la morphologie. La base de données lexicale du basque EDBL recueille actuellement environ 75.000 entrées.
- Dictionnaires électroniques. Sur la base d'une base de données lexicale générale de la langue on peut regrouper d'autres outils lexicaux comme dictionnaires de définition, dictionnaires terminologiques spécialisés, dictionnaires bilingues, etc.
- Grammaires informatiques: descriptions de la syntaxe. Dans le cas de l'euskera, en outre, il faut tenir compte de l'étroite relation entre morphologie et syntaxe. Cela nous a amené à intégrer le traitement morphosyntaxique dans l'analyseur morphologique, résultat d'un analyseur morphosyntaxique général appelé Morfeus.
- Taxonomies sémantiques. Cependant, quand il s'agit de comprendre le langage, il ne suffit pas avec la morphologie et la syntaxe, car le programme doit également connaître la sémantique. Ces relations lexico-sémantiques sont explicitement exprimées dans une sorte de réseau sémantique. Parmi les réseaux sémantiques en anglais, nous avons la connue sous le nom de WordNet et son adaptation au basque s'appelle Euskal WordNet.
- Corpus textuels. Les corpus textuels sont de grandes masses de texte, la principale source d'information linguistique, et les testeurs indispensables pour les applications, outils et bases mentionnées ci-dessus
Comme mentionné ci-dessus, sans ces ressources et outils de base, nous ne serons pas en mesure de développer les applications que nous poursuivons.
Dans le cas de l'euskera nous avons des outils et des ressources, mais si nous voulons voir les technologies linguistiques comme l'anglais, nous avons encore un long chemin à parcourir.

Conclusions
Il y a des produits qui combinent le basque et le logiciel. Dans le catalogue de logiciels de l'Euskera, 105 ont été collectés. 26 d'entre eux sont liés à l'industrie de la langue. Ce n'est rien, mais très peu ; nous devons faire un grand effort pour que le basque ne reste pas en arrière dans ce monde de la société de l'information.
Chacune des bases linguistiques que nous créerons sur notre chemin, chacun des outils et applications devra être bien conçu pour être utile dans les produits suivants.
Dans le but de travailler sur la recherche et le développement de l'ingénierie linguistique et de créer une industrie solide au niveau international, nous avons conçu une stratégie à moyen terme basée sur 15 ans d'expérience du Groupe IXA.
Les équipes de recherche, l'industrie et les organismes officiels doivent être coordonnés pour atteindre cet objectif.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







