



Idioma de los números

La inteligencia humana es muy compleja. Tan complejo que todavía no hemos roto su piel. Sin embargo, está claro que uno de los pilares de esta inteligencia es el lenguaje. El lenguaje nos ha permitido expresar conceptos complejos, dar forma a las ideas y transmitirlas a nuestros compañeros, estructurar culturas ricas y dejar huella en las siguientes generaciones.
Teniendo en cuenta la importancia del lenguaje en nuestra mente, se ha convertido en un tema fundamental de investigación en el campo de la inteligencia artificial. Lo llamamos procesamiento de lenguajes naturales (LNP) y muchos lo podemos ver en más aplicaciones de las que pensamos: El LNP se utiliza en traductores automáticos para identificar los mensajes spam y clasificar el comentario de un producto que hemos comprado en Amazon.
En los últimos años la revolución de las redes neuronales artificiales ha llegado también al ámbito del LNP, con espectaculares conclusiones prácticas [1]. Pero no sólo eso: nos ha puesto de manifiesto interesantes pistas sobre cómo se relacionan palabras y números.
Representación de palabras para máquinas
Supongamos que somos directores de marketing de una empresa de gafas. Hemos lanzado unas gafas nuevas y queremos recoger las opiniones de los compradores. Para ello se nos ha ocurrido utilizar la red social Twitter. Crearemos el hashtag que lleva el nombre de nuestras nuevas gafas para saber qué escriben nuestros clientes sobre las gafas. El problema es que, como nuestra empresa vende en todo el mundo, esperamos muchos tweets. ¡Así que no puedes leer todos los tuits! Nos gustaría que todo este trabajo lo hiciera el ordenador.
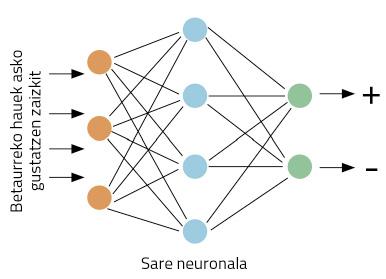
Vamos a concretar mejor los trabajos: tomando un pájaro, nuestro ordenador debe decidir si se da una opinión positiva o negativa sobre nuestras gafas. Empecemos trabajando. Este tipo de problemas son adecuados para redes neuronales. La idea es sencilla: enseña a la red neuronal varios tweets, indicando si son positivos o negativos; a través de la visualización de ejemplos, la red aprenderá a distinguir entre positivos y negativos (Figura 1).
Pero tenemos otro problema: las redes neuronales trabajan con números, no con palabras. ¿Cómo representamos las palabras con números? En el mundo del LNP se ha hecho un gran trabajo al respecto, lo que hace que haya muchas formas de representación de palabras. La idea más sencilla es la denominada one-hot vector en inglés.
Imaginemos cuatro palabras: arriba, abajo, izquierda y derecha. Para ello utilizaremos vectores de cuatro números y asignaremos una posición a cada palabra. Nuestro vector de cuatro elementos estará formado por ceros, excepto en la posición que hemos asignado a cada palabra, donde pondremos uno (Figura 2).
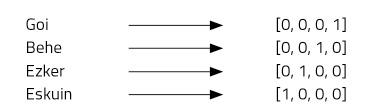
Este tipo de representación es muy simple y distingue bien cada palabra, pero tiene algunos inconvenientes. Por ejemplo, todos sabemos que las palabras arriba y abajo son antónimos. ¿Los vectores de ambas palabras demuestran esta relación? No. El uso de “one-hot vector” no permite imaginar relaciones entre palabras. Otro problema: el euskera, por ejemplo, tiene unas 37 mil palabras [2]. ¡Para representarlas necesitaríamos vectores de 37 mil dimensiones! No parece, por tanto, una idea muy buena.
Word2Vec
Es una idea atractiva utilizar vectores para representar palabras, ya que las redes neuronales trabajan bien con vectores. Pero tenemos que mejorar los vectores one-hot. Así lo pensaron Mikolov y sus compañeros cuando inventaron la técnica Word2Vec [3]. Mediante esta técnica se obtienen representaciones muy interesantes de las palabras por:
1. Las palabras se pueden representar mediante pequeños vectores.

2. Se pueden representar relaciones semánticas entre palabras.
¿Cómo se consigue? Utilización extraña de redes neuronales. Supongamos que tomamos como texto toda la Wikipedia en euskera. En ella aparecerán la mayoría de las palabras en euskera, en frases bien estructuradas. Tomaremos las palabras de estas frases y codificaremos one-hot vector mediante una representación simple. Ahora viene el truco. Tomaremos una palabra para pasar a una red neuronal, cuyo objetivo es inventar las dos palabras que están por delante y por detrás de esa palabra. Es decir, entrenaremos la red neuronal para adivinar su contexto con una palabra, tal y como se muestra en la Figura 3.
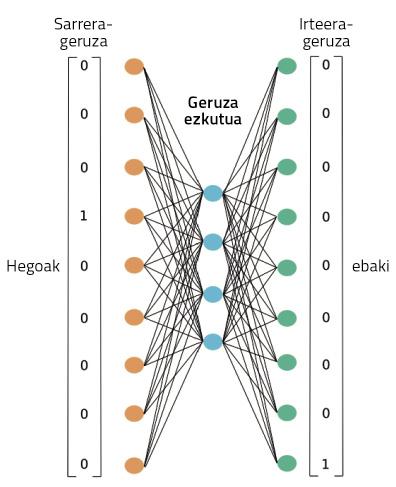
En la figura 4 se puede observar la red neuronal utilizada para realizar este entrenamiento. Procesará el texto completo de nuestra Wikipedia en euskera, tal y como se muestra. A través de una palabra, trabajará en este entrenamiento la capacidad de adivinar su contexto. Al principio, la palabra contexto no acertará, por lo que cometerá grandes errores. Pero estos errores se utilizan para entrenar la red. Así, la red reducirá sus errores de invención a través de la observación de textos de millones de palabras.
Durante este proceso, sin embargo, ¿dónde están las representaciones de las palabras aprendidas? En la figura 4, en la casilla que hemos representado como proyección. Quizá para entenderlo mejor, tenemos que mirar la figura 5. En ella se puede observar la estructura más precisa de la red neuronal en un caso en el que sólo se han tomado dos palabras: una de entrada y otra de salida. Una vez finalizado el proceso de entrenamiento, para obtener la representación de una palabra basta con pasar esa palabra a la red neuronal que acabamos de entrenar y tomar activaciones ocultas de capa. Al igual que las neuronas de nuestros cerebros, las neuronas artificiales también se activan de forma diferente según diferentes estímulos. Pues bien, las activaciones que se obtienen para una palabra diferente serán la representación adecuada de esa palabra. ¿No es sorprendente?
En definitiva, la red neuronal que hemos entrenado para realizar una tarea concreta ha aprendido de forma automática algunas representaciones numéricas de las palabras. Y estas representaciones son muy poderosas.

Jugando con las palabras
Las activaciones de estas neuronas ocultas son números. Por tanto, colocando 300 neuronas en esta capa, obtendremos un vector de 300 números para cualquier palabra. Teniendo en cuenta que en la representación de One-hot vector necesitábamos más de 37 mil números, hemos ganado mucho, ¿no? Pero eso no es lo mejor. Estos nuevos vectores de palabras tienen propiedades casi mágicas. Vamos a jugar con ellos, ¡os quedáis abiertos!
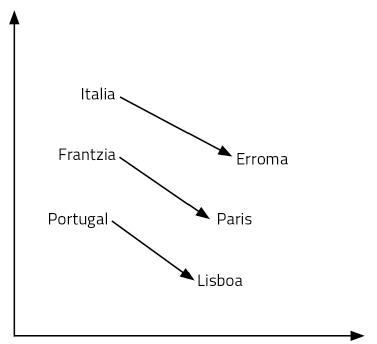
Empecemos con una pregunta: Lo que para Italia es Roma, ¿qué es para Francia? Tu respuesta será París. ¿Por qué? Porque has visto país y capital en la relación Italia-Roma. Utilizando su significado, ha hecho ese razonamiento. Así que has pensado cuál es la capital de Francia: París. Para encontrar la respuesta a la pregunta ha sido necesario manejar el lenguaje y los conceptos. Parece un proceso bastante complejo.
Los vectores de palabras que acabamos de aprender nos permiten responder con facilidad a este tipo de preguntas. En este caso, basta con realizar la operación Italia – Roma + Francia. Es decir, al vector Italia le restamos el vector Roma y después le añadimos el vector Francia. ¡Y sí, el resultado es el vector París! Otro ejemplo: Rey – hombre + mujer = reina. Alucinante, ¿no?
¿Cómo es posible? ¿Es así que añadir y eliminar vectores equivale a razonar? Las representaciones de las palabras que hemos aprendido son sólo puntos de un espacio de 300 dimensiones. Pensemos en dos dimensiones para facilitar su visualización. En la figura 6 se representan algunos países y capitales en un plano de 2 dimensiones. Como se puede observar, los países aparecen cerca, incluso las capitales, que forman parte de una categoría semántica de estas características. Pero además, la distancia entre un país y su capital es igual para todos los pares de capitales de país. Por eso funcionan nuestras sumas y restas. Eso mismo pasa con todas las palabras de una lengua, pero en un espacio de 300 dimensiones. Finalmente, las relaciones entre palabras, su significado y matices son propiedades geométricas.
Hay que tener en cuenta que nadie ha diseñado ese espacio semántico que forman esas representaciones de las palabras. Una red neuronal ha aprendido por sí misma, una red neuronal que se ha entrenado para inventar su contexto con una palabra. Es sorprendente pensar cómo una compleja representación es aprendida por una red que entrenamos para aprender una tarea sencilla. Pero así sucede.
Para terminar
La representación de las palabras mediante redes neuronales es la base del LNP actual. Por ejemplo, las redes complejas utilizadas en la traducción automática consideran estos vectores de palabras como introducción. Tomar vectores en euskera y crear vectores en inglés, por ejemplo. En estos procesos se ha observado que las propiedades geométricas entre palabras aprendidas en diferentes lenguas son muy similares. Es decir, las posiciones relativas de los vectores king, man, woman y queen en inglés son prácticamente iguales a los vectores rey, hombre, mujer y reina en euskera. Investigadores del Grupo Ixa de la UPV, Elhuyar y Vicomtech, entre otros, están estudiando estas vías y proponiendo técnicas innovadoras de traducción.
Otros investigadores han demostrado que en las propiedades geométricas de los vectores se pueden detectar tendencias sexistas en nuestra lengua. Así, se han propuesto técnicas para eliminar las tendencias sexistas de estas palabras para que las máquinas no repitan nuestros errores [5].
Todos estos trabajos cambian radicalmente nuestra visión de la relación entre palabras y números. Ten en cuenta que nuestras neuronas trabajan con la tensión eléctrica. Con números, de alguna manera. Nuestros recuerdos, sentimientos, lenguaje y razonamiento están presentes en los desplazamientos de los electrones entre neuronas. Al igual que ocurre con las redes neuronales artificiales, ¿no hablo, sin darme cuenta, operando con un montón de números? ¿No será nuestro otro idioma?
Bibliografía
Trabajo presentado a los premios CAF-Elhuyar.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







