



Gens, neurones i ordinadors
La naturalesa com a font d'inspiració
Concepte d'intel·ligència artificial XX. Va aparèixer entre nosaltres cap a mitjan segle XX. En els seus inicis es comença a treballar amb la intel·ligència simbòlica i els problemes de cerca. Un bon exemple van ser els jugadors artificials d'escacs. El prestigiós ordinador d'IBM, Deep Blue, va ser el que més èxit va obtenir en imposar-se en 1997 al prestigiós jugador d'escacs Gary Kasparov.
Aquestes màquines, no obstant això, no semblaven la intel·ligència de l'home. Eren capaços de fer molt bé una cosa concreta, però no altra. No estudiaven, no eren capaços de generalitzar el seu coneixement i, si canviaven lleugerament les regles del joc, no podien reaccionar. Per això, els investigadors van treballar nous camins i van treballar en un nou camp de la intel·ligència artificial: l'aprenentatge automàtic.
En aquest article no analitzarem íntegrament l'aprenentatge automàtic. Ens endinsarem en una àrea concreta però atractiva: algorismes inspirats en la naturalesa i aprenentatge. Ens acostarem a un procés molt semblant a la manera d'aprendre humà, combinant xarxes neuronals i algorismes genètics.
Xarxes neuronals
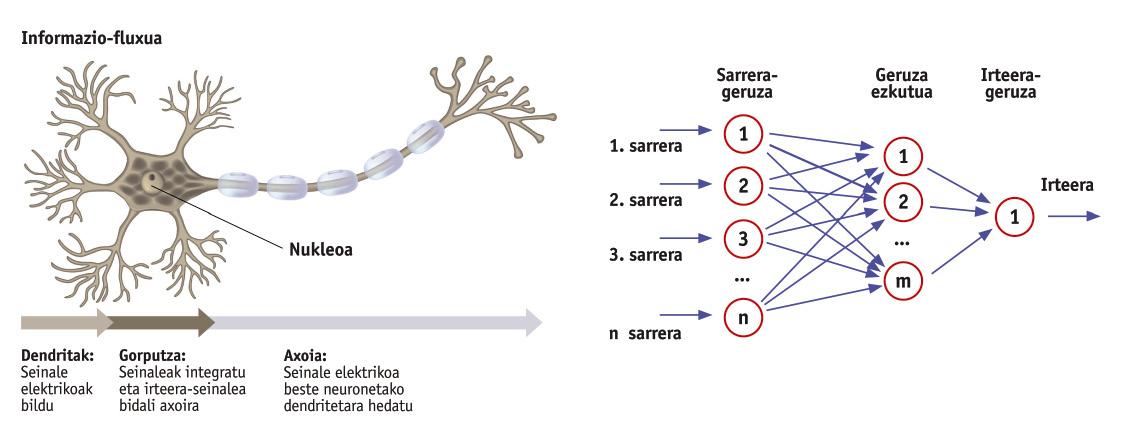
El nostre cervell està format per neurones, una pila de neurones interconnectades. Però si només analitzem una d'aquestes neurones ens sorprendrà la seva senzillesa. Des del punt de vista de la informació, les neurones reben una sèrie de dades d'entrada en forma de senyal elèctric i expulsen un altre senyal (Figura 1). Per tant, la capacitat de processament del nostre cervell es basa en la interacció d'aquestes neurones simples.
En la ment d'aquesta idea, no sembla molt difícil construir xarxes neuronals artificials. I no és difícil. Les primeres xarxes neuronals artificials es van desenvolupar entre els anys 40 i 60 del segle passat. No obstant això, el seu potencial no va quedar patent fins a finals dels 80. Actualment, les xarxes neuronals es poden trobar en onze aplicacions.
Les xarxes neuronals són un conjunt de neurones que converteixen algunes entrades de dades en sortides de dades. Com es pot observar en la figura 2, les xarxes neuronals s'organitzen en capes: capa d'entrada, capa oculta (es poden ocultar tantes capes com es desitgi) i capa de sortida. Cada capa està formada per neurones (rotllos de la figura) i totes les neurones d'una capa estan connectades a les neurones de la següent capa. Així és l'estructura d'una xarxa neuronal convencional. Tingues en compte que poden existir xarxes de tota mena per a complir diferents objectius. Per exemple, algunes xarxes connecten les neurones de la capa de sortida amb les capes ocultes perquè la xarxa tingui memòria. Però, de moment, deixarem de costat estructures complexes.
Les entrades de cada neurona són números. Quan aquests números arriben a una neurona, es multipliquen per altres números anomenats pesos i se sumen a continuació tots els resultats. Aquesta suma serà la sortida de la neurona. Com es veu, el que fa cada neurona és molt senzill. Però tota la xarxa, connectant totes les neurones, és capaç d'implementar qualsevol funció matemàtica. Aquest és el poder de la xarxa. El que acabem de dir pot demostrar-se matemàticament, però això està fora dels objectius d'aquest article.
Per tant, en el comportament d'una xarxa neuronal cobren especial importància la seva estructura (nombre de capes i naturalesa de les connexions) i el pes de cada neurona. Per a realitzar operacions senzilles n'hi ha prou amb una petita xarxa en la qual es fixen fàcilment tots els pesos i es determina l'estructura adequada. No obstant això, les aplicacions complexes requereixen de grans xarxes en les quals és pràcticament impossible determinar manualment tots els pesos de cada neurona. Per això, és imprescindible que la pròpia xarxa neuronal estableixi els valors d'aquests pesos mitjançant un procés automàtic. Aquest procés es denomina aprenentatge automàtic i pot dur-se a terme de diverses formes. Nosaltres aquí veurem l'aprenentatge per reforç. Per a això, en primer lloc, hem d'analitzar els algorismes genètics.
Algorismes genètics
La teoria de l'evolució de Darwin ens va ensenyar com es produeix l'evolució dels éssers vius. Els que millor s'adapten al medi ambient són els que tenen més possibilitats de fecundar-se i la fecundació combina les característiques dels pares i obre el camí a la nova generació. Mitjançant la combinació de les característiques dels individus que millor s'adapten, de generació en generació, neixen millors individus. Els algorismes genètics utilitzen aquestes idees per a optimitzar problemes complexos.
Analitzem aquest problema. Un viatger vol visitar n ciutats, però no de qualsevol manera. Per a estalviar diners, vol fer el camí més curt que passa per aquestes n ciutats (figura 3). Tenint en compte que sabem les distàncies entre totes les ciutats, com podem planificar el viatge? Sembla senzill: calculem tots els ordres de visita de les ciutats, sumem les distàncies i prenguem el més petit. Aquesta solució és correcta, però quan n és un gran nombre de ciutats, un ordinador triga moltíssim a trobar la solució. Per tant, no és una solució pràctica.
Els algorismes genètics poden treballar bé amb el problema del viatger. Com? Primer es crea la generació inicial i es creen unes combinacions aleatòries de n ciutats. Aquestes combinacions aleatòries es denominen individus. Es calcula la distància recorreguda per cada individu, quedant l'algorisme amb uns pocs que proporcionen les distàncies més petites per a creuar-lo. En el cas de les ciutats, per exemple, podem combinar les primeres n/2 ciutats d'un individu amb les n/2 de la segona i crear un nou individu de n ciutats. Els individus resultants dels encreuaments formen una segona generació.

Un altre factor important és la mutació. Igual que en la naturalesa, els nous individus poden néixer amb mutacions. En el nostre cas, l'intercanvi entre dues ciutats en posicions aleatòries pot igualar-se a una mutació. La mutació és estranya però té una funció molt important per a trobar individus més adequats.
A mesura que l'algorisme genera noves generacions, els individus aporten millors solucions. Al final, encara que no sempre és possible trobar una solució òptima, el millor individu queda molt prop de l'òptim. Així que en poc temps pot trobar una solució molt bona. No és sorprenent?
Aprenentatge per reforç
Ara ve el més bonic. Imaginem que tenim un robot que es pot moure en qualsevol direcció. Nosaltres volem mostrar que quan diem “dreta” anem a la dreta i quan diem “esquerra” ens movem a l'esquerra. Per a això posem un micròfon que detecta la nostra veu. El senyal que genera el micròfon és l'entrada d'una xarxa neuronal. La sortida es refereix als senyals dels motors que serveixen per a moure el robot (figura 4).
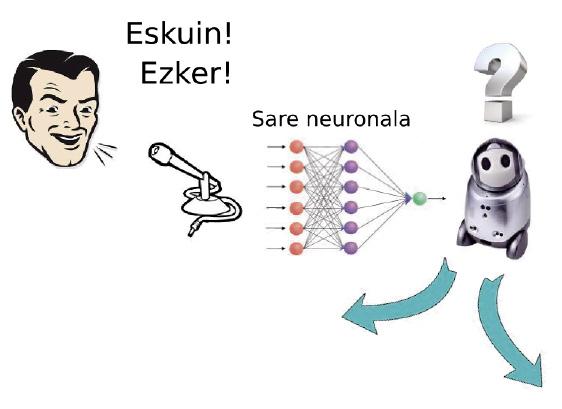
L'objectiu del robot és obtenir els pesos de les neurones que formen la xarxa neuronal perquè faci bé el que hem dit. Entre tots els possibles valors de tots els pesos existeixen solucions que responen a l'estímul vocal amb un moviment adequat. Per a això utilitzarem l'aprenentatge per reforç. Donarem al robot una ordre “dreta” o “esquerra” i depenent del moviment que realitzi li posarem una nota de l'1 al 10. Si diu “dreta” i es mou a l'esquerra li posarem 1. Però si es mou cap endavant fent-ho una mica a la dreta, igual li posem un 5. Clar, quan es mou a la dreta, tindrà un 10!
El procés d'aprenentatge funciona com: en primer lloc, l'algorisme genètic selecciona solucions aleatòries, és a dir, pesos específics de la xarxa neuronal. Executa aquestes solucions i detecta les millors en funció del premi rebut. Creua els millors pisos, a vegades aplica la mutació i torna a provar amb la nova generació. Amb els nous premis rebuts es crearà una nova generació que permetrà trobar una solució amb els premis més potents per a totes les ordres de veu.
Aquests experiments ja s'han realitzat i s'ha comprovat que aquesta tècnica funciona. Però això no és màgia, sinó matemàtiques. ?Realment s'està produint un procés iteratiu de cerca dels paràmetres més adequats d'una funció no lineal. En la nostra opinió, busquem els pesos de la xarxa neuronal en un procés d'optimització en el qual l'objectiu és maximitzar el premi obtingut.
Per a acabar
L'aprenentatge per reforç es basa en processos d'aprenentatge d'éssers humans i animals. A més, aquí hem mostrat com desenvolupar aquest procés utilitzant xarxes neuronals i algorismes genètics. Tots dos tenen la seva base en la naturalesa. És fascinant veure que podem capacitar a les màquines per a aprendre. Potser és més fascinant saber que aquesta capacitat d'aprendre l'hem aconseguit imitant processos que tenen lloc en la pròpia naturalesa, la qual cosa demostra la profunditat del coneixement de la naturalesa que hem adquirit a través de la ciència durant molts anys. Hem pogut combinar psicologia, biologia, neurociències, matemàtiques i informàtica perquè les màquines aprenguin.
Actualment tenim diversos exemples de màquines capaces d'aprendre. Quan comprem en xarxa i valorem els productes, automàticament rebem nous consells perquè els sistemes que estan darrere aprenen de nosaltres. Els cercadors web també utilitzen l'aprenentatge per a oferir cerques personalitzades. A través de la cambra podem conèixer les cares, conduir els cotxes de manera autònoma i posar molts exemples de l'èxit de l'aprenentatge i la intel·ligència artificial.
El camí continua sent llarg. Només hem començat. Encara que la intel·ligència artificial i l'aprenentatge automàtic han evolucionat molt, encara estem lluny del que un ésser humà pot fer. Però avancem.
Bibliografia
"Aquesta entrada #CulturaCientífica 3. Participa en el festival"

Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







