



Datos dorados

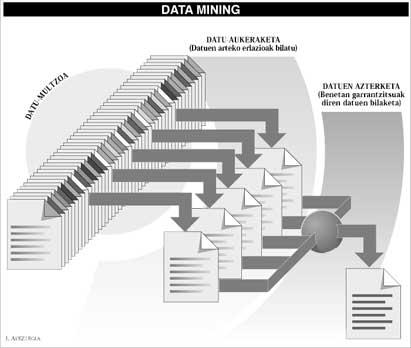
En la actualidad, el conjunto de datos que alberga cualquier organización es enorme. Es cierto que muchos de estos datos se almacenan inútilmente, pero analizar este gran grupo y extraer la información relevante que hay en el mismo, aunque en pequeñas cantidades, es tan difícil como buscar una aguja entre paja. Sin embargo, los beneficios económicos que puede reportar a una empresa son muy elevados. Con un simple ejemplo, comprenderás mejor lo que queremos transmitir, supongamos que eres el gestor de un restaurante y que, basándose en las diferentes combinaciones de menús que suelen pedir tus clientes, sabes qué nuevo plato os conviene ofrecer. Las ventajas son evidentes. Y el mismo ejemplo nos sirve para obtener información que los supermercados, las bolsas, las grandes empresas o la propia policía pueden utilizar. Y esto es sólo el principio.
Todo ello es posible hoy en día gracias a una nueva técnica denominada data mining. Los científicos que están desarrollando esta técnica tratan de tomar un conjunto completo de datos y, a través de una serie de estudios estadísticos, descubrir posibles relaciones entre los datos, excluyendo la basura de este conjunto de datos y recogiendo información realmente relevante. Trabajan como buscadores de oro, secuestrando la tierra de los ríos, buscando pequeños trozos de oro.
Acceso a la información: carrera de obstáculos
Para llegar a dichos resultados se pueden utilizar diferentes técnicas. Una de ellas es la denominada “inducción de árboles normativos”, un método que, mediante diferentes combinaciones, nos explicará las normas más adecuadas. Por ejemplo, “Ensalada y tortilla de palos a la hora con pimientos de chuleta”. Aunque parezca insignificante, este tipo de combinaciones con los conjuntos de datos disponibles puede convertirse en un problema debido a la complejidad de las combinaciones que se generan a través de este procedimiento: “Patatas B ALDIN Y (NO filetes y pimientos Y (NO helado y café) Y ...”
Para superar estos problemas se han desarrollado técnicas más avanzadas, entre las que se encuentra el uso de redes neuronales. La contribución de este sistema a su funcionamiento consiste en intentar imitar la lógica del pensamiento humano para buscar las relaciones existentes entre los datos. Las redes neuronales ofrecen mejores resultados que la inducción (una tasa de invención cercana al 75%), pero el conjunto de reglas que utiliza para relacionar los datos puede resultar muy complejo y a menudo incomprensible. Esto plantea dos problemas: por un lado, la imposibilidad de explicar a los clientes que han solicitado un análisis de los datos en qué se basa el proceso, como el riesgo de fracaso de algunas empresas de las que depende, y por otro, la imposibilidad de revisar las normas básicas en caso de avería en la red.
Pero estos problemas se resolverán en breve. En la actualidad se han empezado a utilizar “algoritmos genéticos”, aplicando principios basados en normas de medidas financieras a la hora de cribar datos. Aunque esta técnica no es muy eficaz, es más comprensible para los clientes. La otra opción es utilizar métodos lógicos simples para encontrar reglas que nos expliquen las relaciones entre los datos, o basados en una forma normal disyuntiva, que da muy buenos resultados.
Pero, sin duda, entre las técnicas más exitosas y prometedoras de la actualidad se están imponiendo las basadas en el lenguaje natural: técnicas que utilizan palabras comunes al lenguaje para controlar el ordenador. La razón de su éxito es evidente: hoy en día, la mayoría de los datos existentes en el mundo se encuentran en el texto ordinario, guardados en papel, microfichas o páginas del procesador de textos, por lo que su lectura resulta difícil para los buscadores de datos.
Así, las ventajas de esta nueva técnica son evidentes, ya que gracias a ellas se han creado paquetes de software que analizan datos en textos sencillos. Así se puede entender el interés que se manifiesta en algunos sectores por desarrollar estas técnicas. Por ejemplo, basta tener como texto las listas de posibles sospechosos de la policía, utilizando la teoría y el análisis lingüístico de los conjuntos que utiliza este programa, para obtener una respuesta rápida preguntando directamente “¿Quién es el mayor sospechoso?”.
Esto puede resultar sorprendente, pero sólo será el primer paso de un largo proceso, una técnica recién creada que nos permitirá sorprender en aplicaciones diferentes que todavía pueden tener más posibilidades.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







