



Elhuyar develops a multilingual system to extract the feeling of social media messages
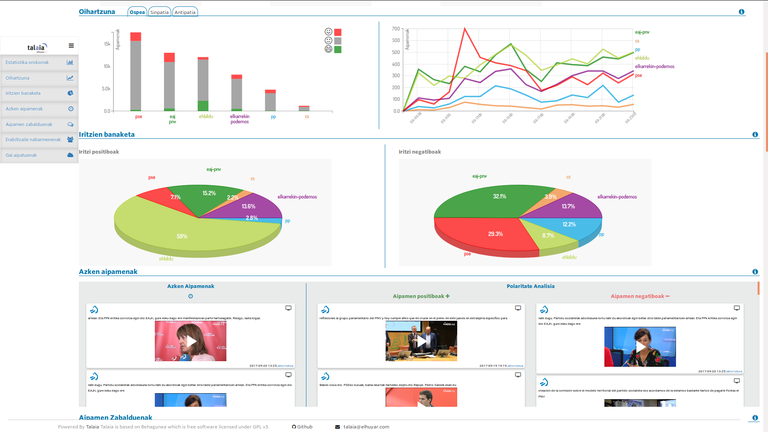
In social networks, users provide information about entities, companies or specific topics. Information extraction systems allow companies to know, for example, the prestige they have in society; or public institutions, to know the attitude of society to its policies.
There were already production systems in several languages, but not in Basque. And the researcher recalled that about 15% of tweets written in Euskal Herria are in Basque (a total of 2,5-2.8 million tweets per year). The rest are mainly in Spanish and French, and some (to a lesser extent) in English. Therefore, San Vicente has developed in these four languages the resources that make up the system to analyze the feeling of messages on social networks.
“The first step was to create polarity lexicons”, explained San Vicente, that is, to create lists of words that by themselves have a positive or negative feeling: bad, bad and good… “In doing so you have to take into account the context”, warned the researcher. In fact, according to the context, the same word may have different polarity: “Lowering sales is bad, while lowering unemployment is good. Therefore, the polarity of the descents varies according to the context.” We must also take into account the negative (no, but yes…) and the irony.
Twitter's own informal writing also creates problems. “On Twitter many make a kind of oral language transcript or mix two languages in one place. Sometimes, to emphasize a word, the last vowel is repeated and emoticons are used to express feelings.” In addition, there are reinforcing and reducing particles, very few… that have been considered in the elaboration of the lexicon.
Machine learning
The next step has been the integration of lexicon into machine learning systems. Thousands of manually classified examples have been used to train these systems: positive, negative or neutral. “With them we teach the system a mathematical model, so that when a new example comes, it will tell if it is positive, negative or neutral based on the previous ones.”
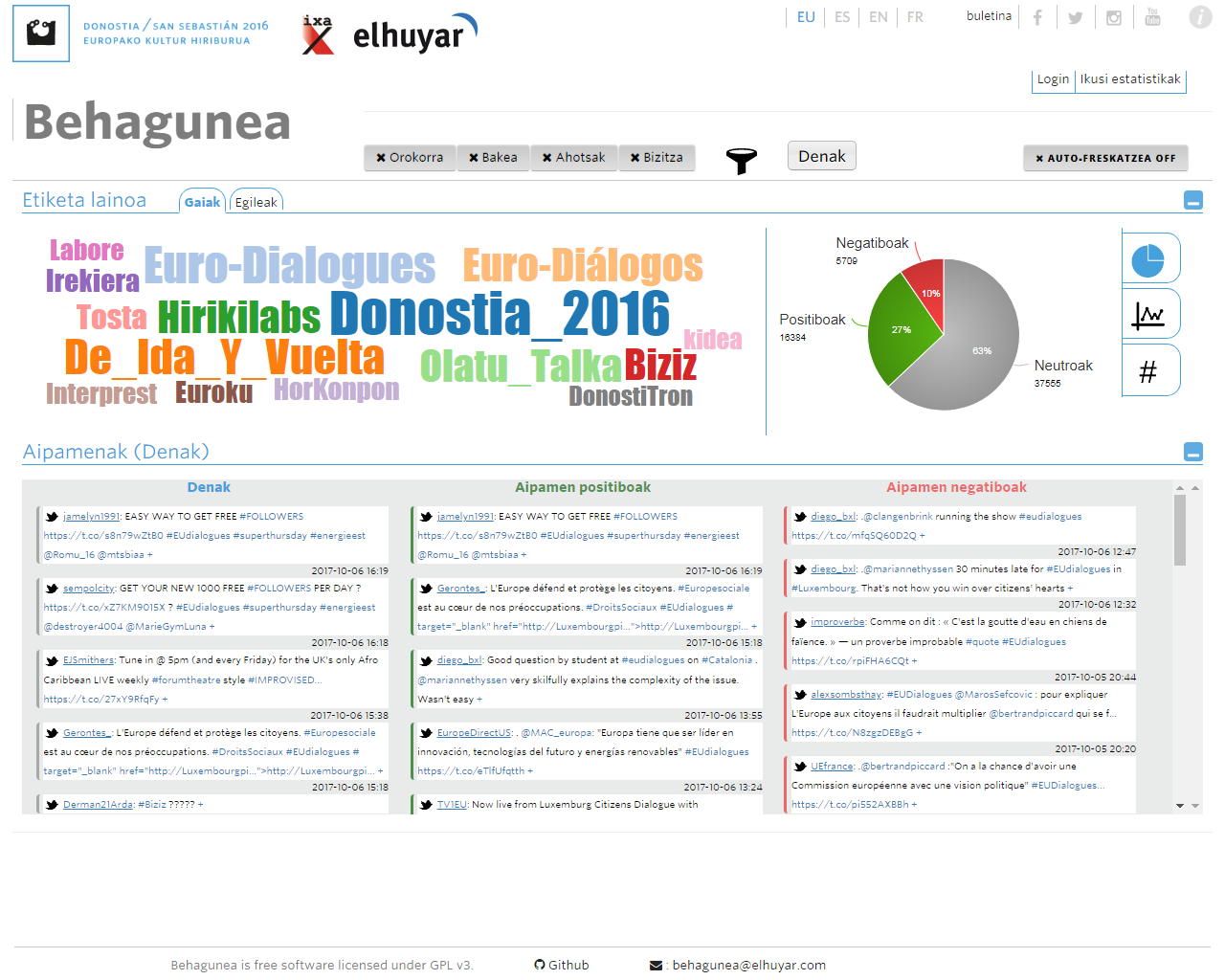
“We have made the rate of invention of the classification in Basque similar to that of other languages,” said San Vicente. At present, the invention rate is around 75%, but Elhuyar members are working to improve the result based on neural networks. Also, although initially the system only extracted the opinions of the texts, it is now able to analyze videos and audios and detect the opinions present in them.
They have already used it in real cases. For example, Behagunea monitored the projects of Capitalidad Donostia 2016. Along with the news, the electoral campaign for the Basque Parliament 2016 was followed and in 2018, with the Institute of Criminology of the UPV, the attitude of the victims of terrorism in social networks has been analyzed.
The research work has been carried out in collaboration with the IXA group and all the results are available on the Elhuyar web of Linguistic Technologies.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







