



Are robots capable of learning?
Why do robots need to learn?
In the day to day we do many activities without just having to think. For example, it seems totally normal for us to enter a room we do not know and walk without touching the objects in that room.

Whatever the environment, the robot must also be able to achieve its goal if we want to do some useful work. Given the high capacity of computers today, why not provide the robot with a detailed description of the environment? Using this description, the robot will be able to carry out its task without needing to learn how it is and how it should act in the environment.
All this could be possible in an artificial toy world, but not in real-life environments. We will not be able to provide the robot with a detailed description of the environment, since it can be too complex or because the environment we do not know it previously. We may want this robot to be able to work in more than one environment. What if the environment was dynamic or changing? If people were going back and still there? How to program the robot to work in these environments?
It is clear, therefore, that to help us in real life, the robot must be able to adapt to the environment in which it will work, that is, to learn to work in that environment. When we have learned, we mean that the robot must be able to improve its behavior making it more appropriate to the environment in which it is located.
Violent learning
In artificial intelligence there are many methods used to learn. The learning method that is intended to be analyzed here is learning through violence, whose name derives from the value called violence. Let's analyze the learning process step by step to understand what violence is.
In order for the robot to adapt its behavior to the environment, it must receive information about it. This is done by sensors: light sensors, contact sensors, artificial vision system, etc.

Once the robot receives information from the environment, it will select and execute one of the actions it can perform (e.g. step forward). Consequently, the robot will receive a data of the suitability of the action. This value is called violence.
It will be positive (award) if the action carried out has led the robot to a more favorable situation (always better with respect to the objective to be achieved) and negative (penalty) if it has left it in worse situation than before the execution of the action. The robot must keep all these experiences in order to decide on future occasions the most convenient action.
Learning is knowing how to decide what action you have to execute at every moment to maximize the violent value that the robot will receive. Suppose we have a simple robot that moves through two wheels and that there is a light source in the environment, that we want the robot to move the light source. It has two light sensors for collecting information from the environment, one to the left and the other to the right. The robot can perform five types of activities: stop, move forward, roll back, turn left and turn right. The sensors distinguish three different situations: the general luminosity measured by the sensor on the left is greater, smaller and the same as that on the right.
Being in these circumstances and able to execute these activities, the robot will begin to move in the environment. The violence it faces will be a great positive if the global luminosity measured in the new situation is higher than the previous step.
Thus, the adaptation between the situation and the action that the robot must learn will be:
- If the brightness on the left is greater than on the right, turn left.
- If the brightness on the left is lower than on the right, turn right.
- If the brightness on the left is the same as on the right, continue.
A simple algorithm: estimation of the interval
This algorithm is based on statistics, specifically on Bernoulli's probability distribution.
As long as the robot acts on the environment, it will save the information received. To do this, it uses two two-dimensional tables, each corresponding to a couple of states/actions.
- The first table shows the number of times the state-action pair has been experienced.
- In the second, the degree of convenience or suitability of the state-action pair is collected.
Each time you execute an action in the environment you will update both tables, adding in the first the situation and the value of the box corresponding to those actions in 1 no and adding the violence you receive (positive or negative) in the corresponding box of the second table.
With these two tables and using statistical calculations you can get the estimated confidence interval for the probability that, being the robot in a situation, an executed action gets a violent value 1. With this interval, the algorithm will know what action to execute so that the behavior shown by the robot is optimal.
Robot Spanky
This robot uses the interval estimation algorithm. It moves with two wheels. It has four light sensors for information on the brightness level and five other sensors for detecting objects in the environment. In addition, the robot is surrounded by a circular sensor to detect possible shocks.
All these devices make the robot receive information about the environment in 5 bits.
- Bits 0.1: The greatest brightness comes from the robot.- 00: ahead -
01: from left -
10: from right -
11: from behind - Bit 2: Has the impact sensor on the right found an object? Yes or no.
- Bit 3: Has the left margin impact sensor found any object? Yes or no.
- Bit 4: Has at least one of the three central shock sensors hit an object? Yes or no.
According to the behavior of the robot, the violent you will receive are:
- If the robot has hit something: negative
violence - Average distribution: -2
- Standard deviation: 0.5. - If the robot has not opposed anything: positive violence - If light
(now)> clarity (before)* Media:
1*
Deviation: 0.2-
Brightness(now) Clarity(before) hour* Average:
0*
Deviation: 0.2.
With all this, the Spanky robot tries not to collide with objects and move towards the light source. Spanky was launched more than 20 times. He was able to learn the best strategy in an interval of 2-10 minutes.
Violence received
The algorithm seen modifies the behavior of the robot according to the violence received after the action.
However, what interests us is to maximize the sum of all the violence collected by the robot, and for this, in addition to the violence received after each action, we must take into account those that will be received later. Perhaps by another action the greatest violence is not perceived, but in the long term, if the sum of the violence that would be received is taken into account, it will be greater.
There are algorithms for this. The algorithm called Q study is one of them and quite good. The algorithm is called learning Q, as it saves values Q. What do these Q values indicate? The robot is at the t moment and receives the input status i. Somehow he decides to execute the action at that time and gathers violence r.
So things, the robot assumes that it will continue to act with the best strategy and hopes to receive the violent r (1), r (2)... These r(j) you expect to receive later, j = 1..., will be taken into account, but the farther away, the lower the incidence. This is achieved thanks to the discount factor{ Initially, the value of{ will be close to 1 and will be smaller and closer to 0.
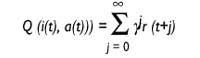
Value Q: action utility to in situation i
where
t: tempo{: discount factor
0 <{ < 1r(t): violence received
at the instant t
The Q value indicates the utility of executing an action in a state.
It will save such a value for each pair of states and actions. A table with the experience of the robot will be completed.
The robot will test in the environment and save in its table all the results you receive for later use.
The robot is at a given time in state i and wants to know the usefulness of this situation. What action would you have to take in this situation to be the maximum violence you will receive in the future? This utility will be the value that has the highest value Q action for this situation and will only decide to carry out such action.
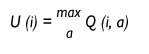
Usefulness of the situation i.
With the information we have, we have enough to build an effective learning algorithm. This algorithm continuously updates the Q values of the table. This is his fundamental work, hence the robot derives his behavior. The algorithm will modify the table values as follows:
Q (i (t), a (t)) = r (t) +{ U (t+1))

Suppose we are at the time t, the robot looks in state i (t) and executes the action a(t). As a result, it is in an r(t+1) situation and has received a r of violence. Then, the algorithm will go to the Q values table and calculate the U (i (t +1) utility of the new state i(t +1), as indicated above. This utility will be deducted through the{ parameter, to add it to the r(t) violence you just received. However, it has the utility of the action a (t) that you have just executed and saves it in the table where it corresponds for later use. He knows how action has gone into state i, to what extent its execution has been good.
When the robot starts to act in the world, the Q values it saves in the table are not very significant, but the author of this algorithm, Watkins, showed that the algorithm quickly approaches the real values Q. Once converged, the robot has learned to move around that environment and will always act on the best strategy. The algorithm is dynamic and the Q values of the table are constantly changing to adapt to a potentially variable environment.
What are you thinking? Can the complexity of computability be enormous? Well, yes! So it is. What you can't...
The problem of computability complexity is enormous. In the case of the previous Spanky robot, the input state is expressed in 5 bits, that is, it is able to differentiate 25 = 32 different states. Of course, Spanky is just a toy robot. In practice, the robot will receive input status information through more bits and will be able to execute more different actions. How large should the algorithm be used? Both in space and time, the combination is exploited.
This algorithm requires all situations to be defined and, as we have seen, the required space is huge. Unfortunately it is not the only problem.
Problems of generalization of entry states
Analyzing the behavior of the living being, although he does not know how to act in new situations, we can observe that he uses a similar experience. This tells us that Izaki is able to generalize. Normally there is a certain relationship between situations and there are very similar situations. If we know how to act in a situation because we have experience in that situation, if we are in a different and new situation, we would act in the same way.
How can the robot know that one situation is similar to another? If you could know it, to know how to act in new situations you would use the experience of similar situations to create similar actions.
One way to fix this problem is to use the Hamming distance. Information about the state of the robot comes through bit series. You can calculate the Hamming distance between these bit series, such as the number of different bits that have two bit sequences.

Great! The problem of generalization can be overcome. However, should all situations be kept? The problem of the combinational explosion is still there!
Statistical groups have also been used to overcome it. However, much remains to be done.
Are we on the right track?
What do you think? Do you think there are things? Although we have not mentioned it yet, there is a problem in all this.
In all the algorithms described we have assumed that the robot is in a certain state and that once an action is performed, without taking into account anything else, we know in what situation will be found at the next moment, that is, that the transition between states is the Markovian. On the contrary, we have never taken into account the situation we are in before we are in the current situation and this can be important.
Suppose the robot is fast and goes forward at full speed. At any given time, due to some obstacle at the front, the decision will be made to turn right. In what situation is it after turning? According to our algorithm, we say that the robot describes the right angle, but we know it is not. The robots used so far are quite slow and the problem has not been very obvious. But if we continue like this, we will realize that we go wrong, because what the robot does and what he believes it does can be very different.
There are many problems. Of course. But so far the trials have been very positive and we have seen that robots can become good students. Just a little more work is needed.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian







