Tool to scan Basque texts in Basque

When we use OCR software, each character is scanned as if it were a photo and then that scanned image is scanned and returned to a normal character code (e.g. ASCII).
The accuracy of the OCR system is limited by three factors: the quality of the original document, the quality of the image created by the scanner and the interpretation made by the OCR software. ELEKA has developed a tool to perform this interpretation in Basque.
To transform the scanned image into text, the OCR analyzes the points that compose it and distinguishes the gaps between them. This process is called segmentation and is done in three steps: first lines are separated, then words are isolated and finally characters are separated. This last phase is simpler if all characters are of the same width, and it gets very complicated if they touch each other, if they are mixed with other punctuation marks or if the width depends on the shape of the character.
The uniqueness of Basque
To realize the character knowledge it is necessary that the OCR system knows all the characters of the language of the scanned text. If doubts arise with the characters, I would wait for the word to be completed, process in which it will be useful to have a dictionary of that language to be able to equate it. Thus, through a game of probabilities and evaluating whether it is a dictionary word, the system will select one or another character.
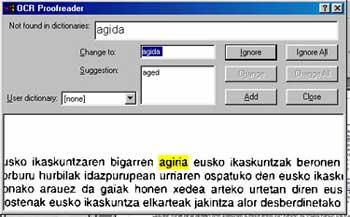
In theory, it is enough to have an alphabet and a dictionary in that language to correctly apply the OCR, but in the case of Basque it is not so. You cannot give a complete list of possible words, that is, you cannot create a dictionary, since being a declined language, from each of the roots there are too many forms of word. The linguistic tools will provide great help in this step, that is, working the main characteristics of the Basque language can achieve great improvements to develop an OCR system. For example, combinations of characters or words made in Basque (using ts, tz, tx, or stripes) are less common in other European languages.
With most of the OCR software currently used, when we want to analyze a text in Basque, we must use the vocabulary of a language in Spanish. However, in these cases it is preferable not to use vocabulary than that of another language so as not to make more mistakes in the text. For example, if we are using an English dictionary, it will almost certainly replace most "six" appearances with "set." If you are using Spanish, the word "energy" is replaced by "energy" (with tilde).
Corrector for the Basque language
ELEKA has developed a correction plug-in in in Basque for the Omnipage program, the most widely used OCR software. This program was prepared to convert the scanned image into characters also in the case of Basque, but not for the later phase of verification and correction of words. ELEKA has added to the program morphological information of the Basque language to digitize in the best possible way the texts in Basque.
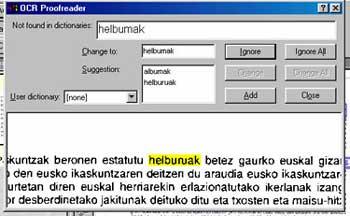
The following intentions will consist of adding an OCR corrector such as Xuxen for the word processors Microsoft Word and OpenOffice, to make available to users who do not use Omnipage the OCR system in Basque.
The project has been developed in collaboration with the Basque Government's Deputy Ministry of Language Policy and will soon be on the street.
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian