



Future voice voice

A few months ago, on the occasion of the creation of a voice database in Basque, Telefónica called for the recording of 10,000 Basque voices. For this purpose, a free phone number was placed to which the caller should repeat phrases and numbers that a computer said. What the computer was going to say was prepared by the Basque Philology Department of the UPV/EHU with the intention of collecting all the usual sounds in Basque. For this purpose, a macrotext provided by UZEI was analyzed. Although those responsible for the project needed at least 5,000 calls, they received about 19,000, even though they were useful – they repeated everything the computer had said – 11,200. The project was attended by EITB, which recorded everything the local staff said on the computer and carried out a voice capture campaign.
The information collected in telephone calls was collected in Leioa, Department of Electricity and Electronics of the University of the Basque Country. The digital information collected must now be processed and will subsequently constitute the database. This database that is created can be used with the connoisseurs of the voice, so they can continue investigating in this matter. For its part, the Faculty of Philology can also take advantage of the information received to carry out research on the phonology of the current Basque language. If progress is made in the planned way, this project will soon allow access to new services in Basque: telephone brands by voice, telelectura of counters, credit card validation, electronic banking, telephone purchases….
Automatic membrane recognition system
What seems to be a question of the future are the daily bread in the Department of Electricity and Electronics of the UPV, since the Voice Knowledge team devotes hours and hours to it. Computers will come to talk, it seems there is no doubt about it. How does it make them speak? How are they taught?
Our brain builds a message within it following the rules of language. Then, using the system of creating the voice of the body, it produces a very rich wave in harmonics, the voice signal. This acoustic signal has several characteristics: energy, low harmonics in the frequency band of 7-8 kHz, basic frequency, etc. In this sign there are noises. These sounds, according to the rules of language, constitute lexical units. Each noise has its acoustic characteristics. Therefore, these elements, sounds and lexical units that appear encoded in the voice signal, must be decoded to know the generated message.

To be able to use the voice signal on the computer it is necessary to sample it. For this purpose, the analog signal becomes digital. The digital signal is then parameterized to reduce the redundant information of the voice, that is, the most characteristic characteristics of the signal are extracted: energy, basic frequency, certain parameters related to the frequencies, etc.
Voice recognition is performed using two techniques, one based on isolated or silent words, and the other is the so-called continuous membrane. In both cases, for the system to understand the message, it must have a decoder of acoustic models: in the case of isolated words, models of words are used and in the case of continuous language, models of sounds and lexical units.
In the first case, the operation of the system is very simple: the signal is compared with the word models that have been studied and the most similar word model is chosen. As for the knowledge of continuous language, the process is divided into two phases: acoustic and phonetic decoding and language modeling. In the phase of acoustic and phonetic decoding, the string of sounds of the voice signal is obtained. Then, in the modeling phase of the language, the lexical units are obtained and, using syntactic and semantic rules, the message containing the signal is decoded. At that time the computer is already able to know the language.
The process is carried out by different mathematical methods. As for acoustic models, structural-stochastic approximations, hidden models of Markov. On the other hand, to learn models and know the message, other algorithms: Baum-Welch, Viterbi.
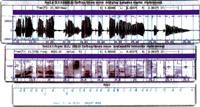
And it is that for the system to function properly you have to know each noise. Therefore, you must learn different samples of each sound, since the sounds produced by one and another person are different. Therefore, in this phase of automatic language knowledge, it is essential to have a large database, since the more speakers there are, the more features will be able to collect and know the system. That is, in order for the system to know each of the sounds, it needs a lot of samples from each one of them.
Special Basque language?
To date, and also in the UPV, it has been worked mainly with models in Spanish, but the work of the group of automatic recognition of the language is coming soon, since for years it is working mainly with the Basque language. From the point of view of the characteristics of the language, the Basque language can have peculiarities. "As for the sounds," says Karmele Lopez of Ipiña, a member of the Mintzo Automatic Recognition Group, does not seem to be more difficult than the rest of languages, because there is nothing unusual about it. As for the lexicon, the Basque language is special, since the language is sticker. For example, for us the word house is home, but for them what is home — the word does not change — for us is home, and that is a new word. Euskera has a great future in the field of automatic oral knowledge, especially because of the interest it has aroused in the scientific community thanks to its specific characteristics".
Telefónica's database has had an echo, but in the Department of Electricity and Electronics of the UPV/EHU of Leioa they have collaborated with the support of the Basque Philology Department of Vitoria-Gasteiz and with the subsidy of the Basque Government. "For many years our group has been developing a system of automatic recognition of the Basque language. Specifically, two voice databases have been designed, one for use in telephone applications and another for the development of systems of any type. With this, in terms of the phonetic databases, we have managed to equip them to other languages. If we look at the people who work in this field in the world, we can say that we are not so bad, we are in a couple."
Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










