



Erreur avec ou sans h ?

Estimation erreur différente
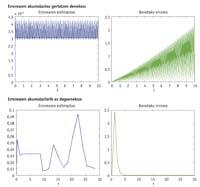
Si une équation différentielle ne peut pas être résolue de manière analytique, elle peut être résolue par des méthodes numériques. Le résultat analytique est précis, tandis que le résultat obtenu par la méthode numérique est approximatif et se construit pas à pas. L'erreur lors du relâchement d'une équation différentielle par méthode numérique est la différence entre le résultat exact et approximatif. Un concept qui théoriquement n'a pas plus de difficultés qu'une soustraction, quand il faut le calculer dans la pratique devient un concept complexe. Mais quel est le problème? Nous ne connaissons pas les résultats exacts de nombreuses équations différentielles. Par conséquent, en ignorant le résultat exact, il nous est impossible de calculer l'erreur que nous commettons en utilisant la méthode numérique. Bien que nous ne connaissions pas l'erreur, nous savons que le résultat approximatif obtenu en utilisant des méthodes numériques d'ordre élevé est plus précis que celui obtenu par des méthodes numériques d'ordre inférieur. Cependant, chaque fois qu'une étape est franchie par la méthode numérique, une mesure nous indique généralement si le résultat obtenu à cette étape est valide ou non. Quelle est cette mesure si nous avons dit que l'erreur ne peut pas être calculée sans connaître le résultat concret?
La mesure utilisée est l'estimation de l'erreur. Une estimation d'erreur de grande utilité est celle qui est calculée comme la différence de résultats obtenue en utilisant des méthodes numériques d'ordre successif, basée sur l'élimination du résultat obtenu en utilisant une méthode numérique d'ordre ( n+1 ), qui est connue comme extrapolation locale. Lorsque nous l'utilisons, nous exigeons à chaque étape que la différence entre les résultats obtenus par deux méthodes consécutives soit inférieure à une tolérance préalablement établie. Si la condition est remplie, le résultat donné par la méthode de commande ( n+1 ) est accepté, sinon il faudra répéter les opérations de passage et le tester avec une autre étape inférieure à celle utilisée précédemment. Si nous voulons utiliser l'extrapolation locale de l'une des mesures à effectuer dans un laboratoire, deux mesures de la quantité à mesurer seraient effectuées à l'aide de deux appareils de précision différente. Étant donné que les précisions de ces appareils doivent être consécutives, lorsqu'un appareil de plus grande précision est disponible, le second est celui qui a une plus grande précision parmi les appareils de moindre précision que le premier. De cette façon, nous assurerions que nous utilisons des appareils avec des précisions successives. La mesure doit être répétée jusqu'à ce que la différence entre les deux mesures soit inférieure à une valeur donnée et, si la condition est remplie, le résultat de l'appareil le plus précis sera accepté. Comme on peut l'apprécier dans l'exemple de laboratoire, la méconnaissance du résultat réel est payée avec la duplication du nombre de calculs.

Par conséquent, l'extrapolation locale est une ressource sûre mais chère à la fois. Comme son potentiel est basé sur la comparaison des résultats obtenus avec deux méthodes d'ordre différent, il entraînera toujours une augmentation du nombre de calculs. Profitant de la certitude de l'extrapolation locale et en acceptant l'augmentation qui va supposer dans le nombre de calculs, de nombreux créateurs ou parents de méthodes numériques se sont concentrés sur la conception de méthodes qui pourraient faire ce nombre de calculs ne pas doubler, c'est-à-dire ont eu pour objectif de donner naissance à deux méthodes d'ordre successif avec les moindres différences possibles. En ce sens, en utilisant un jeu de constantes différent en une seule opération, les méthodes qui réalisent une méthode d'ordre n ou ( n+1 ) sont très utiles car elles permettent d'optimiser la différence entre deux méthodes d'ordre successif. Les méthodes Runge-Kutta introduites en sont un exemple. Il suffit, en plus des opérations effectuées pour obtenir le résultat par la méthode de commande ( n+1 ), d'effectuer une seule opération pour obtenir le résultat que nous fournit la méthode de commande n. Ils offrent donc une option économique pour obtenir des résultats de différents ordres. Il n'y a qu'une autre option plus économique que celle d'obtenir les deux au prix d'une. Mais cela est impossible, car il faudra différencier les différentes méthodes en quelque chose.
Estimation avec h sans h

Parfois, la descente de la barrière ne sera pas affectée, car il y aura des estimations qui passeraient sans aide la hauteur initiale de la barrière. Mais il y aura des sauts qui ne peuvent pas dépasser la hauteur initiale de la barrière et qui seront affectés par la descente de la barrière. Par conséquent, l'étape à répéter en utilisant une autre estimation sera considérée comme valide. La répétition d'une étape implique d'essayer avec des étapes plus petites, et si les étapes sont petites, il faut plus. Par conséquent, lorsque nous utilisons les estimations où nous abaissons la barrière, il y aura moins d'étapes et donc plus grandes que celles qui ne descendent pas. La monnaie, cependant, a un autre aspect, car il peut arriver que la descente de la barrière n'ait pas le résultat souhaité. Cela peut influencer négativement l'erreur finale et réduire considérablement la qualité du résultat approximatif que nous obtenons. En général, l'estimation calculée sans h entraînera la nécessité de prendre des mesures plus petites, mais l'accumulation d'erreur réelle sera également inférieure.

Estimation erreur en h ou sans h
Les équations différentielles peuvent être rigides ou non rigides. La définition pratique de l'équation différentielle rigide est celle d'une équation qui doit prendre de nombreuses étapes à un algorithme. Bien que le mot «beaucoup» n'indique pas de chiffres concrets, 100 étapes ne sont pas nombreux et 3000 sont nombreux. Lorsque le problème est rigide, on préfère utiliser une estimation sans “h”, car avec l’estimation avec “h” on obtiendra un résultat beaucoup mieux que celui obtenu avec l’estimation sans “h”. Bien que le problème ne soit pas rigide, le résultat obtenu avec une estimation sans h sera, dans la plupart des cas, mieux que celui obtenu avec h, mais le résultat --différence entre les deux - ne sera pas si spectaculaire, c'est-à-dire le travail supplémentaire qui suppose l'utilisation d'une estimation sans h dans des équations différentielles non rigides ne produira pas beaucoup de luminosité dans la solution.

Dans les langues, il est courant qu'un mot perde ou gagne le "h" selon l'époque. Exemples sont la construction de murs parfois avec ou sans h, ou la guérison des patients dans les hôpitaux avec ou sans h. Cependant, la fonction ou la signification des mots qui ont collé ou supprimé le “h” par le temps est resté le même. Le sujet des erreurs avec h et sans h en mathématiques ne dépend pas de l'époque: il a toujours été la coexistence entre les deux, et les deux sont nécessaires parce que la fonction de l'un et l'autre n'a jamais été la même. Tout comme nous consultons dans le dictionnaire si un mot a ou non un « h », pour décider s’il utilise ou non un « h » dans l’estimation de l’erreur, il faudra « consulter » le problème à libérer, car la clé du succès que nous obtiendrons dans le résultat sera que l’estimation de l’erreur ait ou non un « h ».

Buletina
Bidali zure helbide elektronikoa eta jaso asteroko buletina zure sarrera-ontzian










