

Intuizioaren bide ilunak argitzen
2017/05/12 Azkune Galparsoro, Gorka - Ikertzailea eta irakasleaEuskal Herriko Unibertsitateko Informatika Fakultatea Iturria: Elhuyar aldizkaria

Intuizioaren inguruan, pentsalari askok egin dute lan historian zehar, hala nola Descartesek, Kantek edo Husserlek. Gaur egun, ordea, psikologoek eta neurologoek aztertzen duten kontzeptu bat da intuizioa, eta, horretarako, zientzia modernoaren tresnak eta bideak erabiltzen dituzte. Ez ditugu haien lan sakonak ekarriko hona. Nahikoa zaigu jakitea azken teorien arabera bide ez-arrazionaletatik sortzen den ezagutza dela intuizioa. Ondorioz, ezagutza-mota hori ezin dugu ez azaldu, ezta hitzetan jarri ere [1]. Eman garrantzia kontzeptu horri, berriro ere azalduko zaigu eta.
Artikulu honetan zehar ikusiko dugu ea intuizioa gizakiok soilik dugun ezaugarri bat denetz. Horretarako, lehenbizi, xakean jokatzen duten makinak aztertu eta ulertuko ditugu. Ondoren, Science aldizkariarentzat 2016. urteko lorpen zientifiko handienetako bat dena ikusiko dugu [2]: AlphaGo, Go txinatar jokoa menderatu duen adimen artifiziala.
Xakea eta Deep Blue makina

Mendebaldeko kulturan, xakea izan dugu mahaiko estrategia-jokoen gailurra. Saia gaitezen joko hori zenbakien bidez aztertzen. Xakean, jokalari bakoitzak 6 motatako 16 pieza ditu hasieran. Mota bakoitzeko piezak era ezberdinetan mugi daitezke. Beraz, jokoaren edozein egoeratan, jokalari batek 35 mugimendu ezberdin egin ditzake.
Zuhaitz-erako egiturak erabiliz azaldu daitezke xakea eta halako jokoak. Zuhaitzaren erroan, partidaren hasierako egoera adierazten da, pieza bakoitza hasierako posizioan egonik. Demagun hasierako egoeratik peoi bat mugitzen dugula. Egoera berri hori gure zuhaitzaren lehen lerroan egongo litzateke, beste pieza guztien mugimendu posible guztiekin batera. Egoera berri bakoitzetik, mugimendu posible adina adar berri irtengo dira, eta, horrela, bukaerara iritsi arte (1. irudia).
Jotzen da xakean sor daitezkeen jokoen kopurua, hau da, zuhaitzaren nodo-kopurua, 10120 inguru dela. Zenbaki horren handitasuna argiago ikusteko, pentsa, kalkulu onenen arabera, gure unibertsoan 1080 atomo daudela!
Lehenbizikoz xake-maisu handi bat garaitu ahal izan zuen makina Deep Blue izan zen, 1997an [3]. IBMk programatutako superkonputagailu hark xakearen zuhaitza erabiltzen zuen erabakiak hartzeko. Zuhaitz osoa gordetzea ezinezkoa denez, joko-egoera bat adierazten zuen nodotik abiatuta, hurrengo sei sakonera-lerroak aztertzen zituen makinak. Sakonera haietan zeuden nodoak ebaluatzen zituen, ikusiz zein nodo zen txarrena beretzat eta zein onena. Ebaluazio horren ondoren, nodorik txarrena ekiditeko egin beharreko mugimendua hartzen zuen.
Joko-estrategia horren gakoa nodoak ebaluatzeko gaitasuna da. Horretarako, IBMk xake-jokalari handiekin egin zuen lan, haien ezagutzarekin irizpide programagarriak lortzeko. Irizpide horiei heuristiko deitzen zaie. IBMk sekulako lana egin zuen heuristiko haiek definitu eta programatzeko, eta, azkenean, Gary Kasparov bera garaitu zuen.
Go txinatar jokoa
Xakearekin alderatuz, go jokoaren arauak sinpleagoak dira, baina joko askoz ere konplexuagoa da. Kalkuluen arabera, 10761 joko posible daude goan! Baina hori ez da txarrena: xakean heuristikoak programatzea posible da, baina goan ia ezinezkoa da behar bezala funtzionatzen duten irizpideak ongi definitu eta programa bihurtzea. Adituak, oro har, ados jartzen dira mugimendu bat ona ala txarra izan den erabakitzean, baina ezin izaten dute azaldu zergatik pentsatzen duten hori. Badirudi intuizioa dela goan jokatzeko gakoa. Eta, noski, oraindik ez dakigu intuizioa hitzetan jartzen, formula matematiko bilakatzen edo programa gisa idazten.
Hori dela eta, aditu gehienek esaten zuten, orain dela ez urte asko, goko jokalari onenei irabaziko zien makinarik ez genuela ikusiko hogei urteren bueltan. Bada, ikusi dugu. 2016ko martxoan, Deep Mind enpresak [4] AlphaGo makinarekin irabazi zion munduko txapeldun handienetako bati, Lee Sedol korearrari.
AlphaGo eta ikasteko boterea
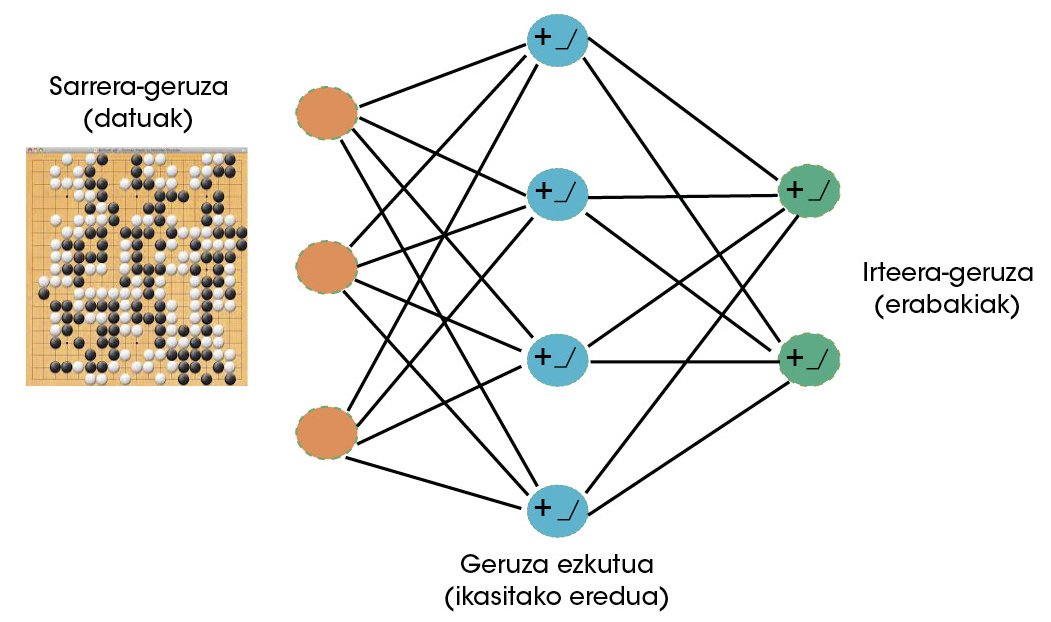
Deep Mindeko zientzialariek argi ikusi zuten goa oso joko egokia izan zitekeela ikasteko gaitasuna duten makinentzat. Beraz, neurona-sareak erabiltzen hasi ziren goan jokatzen ikasteko [5]. Ikasketa-algoritmo arrakastatsuenak dira, gaur egun, neurona-sareak [6]. Garuneko neuronen antzera, neurona artifizialek seinale batzuk jasotzen dituzte (datuak) eta, ikasitakoaren arabera, aktibatu egiten dira ala ez. Ikasketa-prozesuan zehar definitzen du neurona-sareak zer daturen aurrean aktibatu eta aktibazio horien intentsitateak nolakoak izan behar duten. Neurona artifizialak elkarrekin lotuz, geruzak eratuz, portaera oso konplexuak ikas ditzakete sare hauek (2. irudia).
AlphaGok bi neurona-sare garrantzitsu ditu: alde batetik, politika-sarea dugu, eta, bestetik, balio-sarea. Politika-sarearen helburua da joko-egoera bat emanda hurrengo mugimendu onena zein izango den asmatzea. Horretarako, bi ikasketa-estrategia konbinatzen dira. Hasieran, gizakiek jokatutako 30 milioi jokaldi erakutsi zitzaizkion sareari, ikasketa gainbegiratua erabiliz. Hots, sareak ikusten zuen joko-egoera batentzat, hurrengo mugimendua zein zen erakusten zitzaion. Adibide haietatik orokortzen ikasi zuen. Mugimendu guztiak prozesatu eta ikasketa amaituta, gizaki baten mugimenduak aurreikusten zituen politika-sareak, % 57ko asmatze-tasarekin.
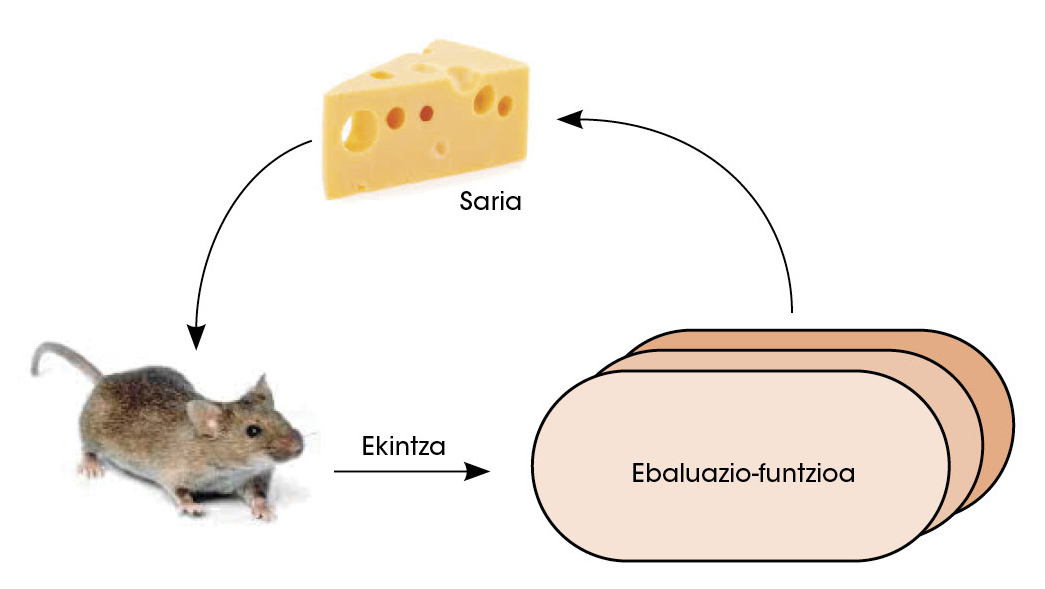
Bigarren fase batean, politika-sarea bere buruaren aurka jokatzen jarri zuten. Horrela, errefortzu bidezko ikasketa erabiliz, hurrengo mugimendu onena zein zen erabakitzeko gaitasuna hobetu zuen sareak. Ikasketa-mota honetan, sareari erabakiak hartzeko askatasuna ematen zaio. Erabaki horien ondorioz irabaztea lortzen badu, saria ematen zaio. Baina galtzen badu, zigorra ematen zaio. Sari-kopurua ahalik eta handiena izan dadin, geroz eta erabaki hobeak hartzen ikasten du sareak (3. irudia).
Balio-sareak beste helburu bat du. Haren egitekoa da, joko-egoera bat emanda, irabazteko probabilitatea balioztatzea. Sare hori entrenatzeko, AlphaGok bere buruaren aurka jokatutako milaka partida erabili ziren. Hainbeste partida ikusi ondoren, balio-sareak ikasi zuen behar bezala kalkulatzen jokalari batek joko-egoera baten aurrean irabazteko zer aukera duen.
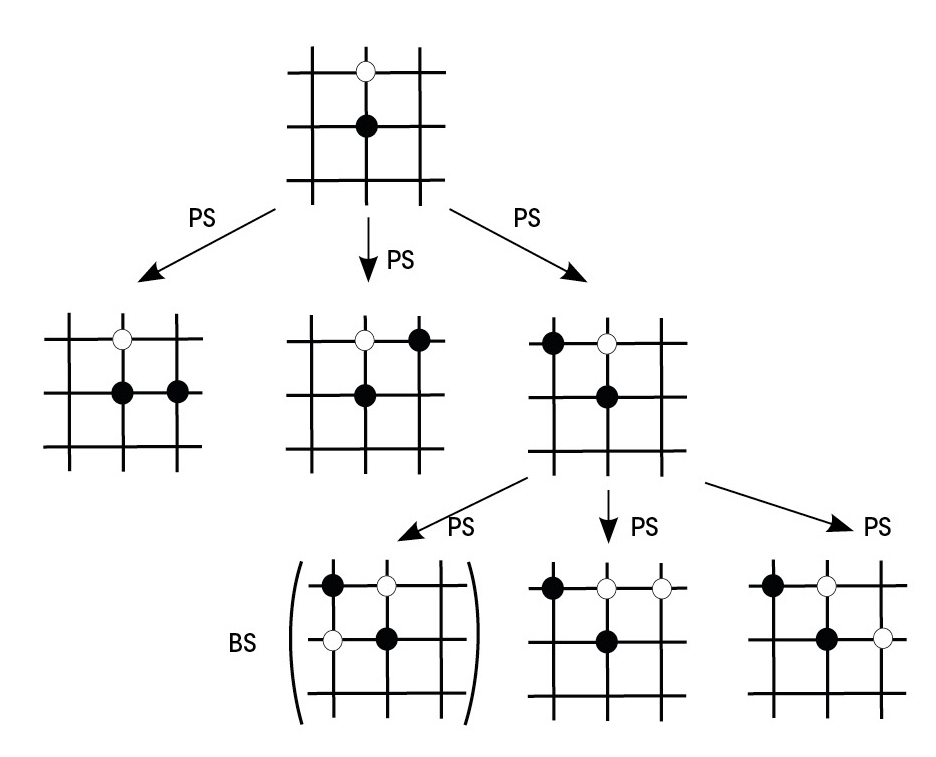
Nola konbinatzen dira bi neurona-sare horiek goan jokatzeko? Horretarako, berriro ere, joko-zuhaitza erabili behar dugu. AlphaGok, joko-egoera bat emanda, politika-sarea erabiltzen du hurrengo mugimendu onenak zein diren aurreikusteko. Mugimendu horientzako partidak simulatzen ditu sakonera jakin bateraino. Partida horien azken joko-egoerak balio-sareari pasatzen zaizkio, irabazteko probabilitatea kalkula dezan. Horrela, politika-sarearen ustez onenak diren mugimenduen artean, balio-sareak irabazteko probabilitate handiena ematen dion joko-adarrari eusten dio AlphaGok (4. irudia). Kontu egin gainera, partida gehiago jokatzearen poderioz, bai politika-sarea bai balio-sarea hobeak bilakatzen direla beren lanean.
Deep Blue vs AlphaGo
Egia da bi makinek joko-zuhaitzean bilaketak eginez hartzen dituztela erabakiak. Baina alde ikaragarria dago zuhaitz horiek aztertzeko garaian. Deep Blueren kasuan, adituek eskuz programatu zituzten joko-egoerak ebaluatzeko irizpideak. Beraz, Deep Bluek ezingo luke xakea ez den beste joko batean jokatu. Eta, noski, haren jokatzeko gaitasuna beti bera izango da, adituren batek heuristikoak hobetzen ez dituen bitartean.
AlphaGok bi neurona-sare darabiltza mugimendu onenak eta joko-egoerak baloratzeko. Sare horiek ez ditu inork eskuz programatu. Beren gaitasuna ikasiz lortzen dute, eta, beraz, bi abantaila nagusi dituzte:
1 Beste edozein mahai-jokotarako balio dezakete.
2 Partida gehiago jokatzen den heinean, jokalari hobe bilakatzen da AlphaGo.
Bi makinen funtzionatzeko moduak adimen artifizialaren munduan historikoki izan diren bi paradigma nagusien adierazgarri bikainak dira: Deep Blueren ezagutzara bideratutako adimen zurruna eta AlphaGoren ikasteko gaitasuna. Makinak eskuz programatzetik, beren kasa ikas dezaten uzteraino. Gaur egun, nahiko argi ikusi dugu bigarren ideia, ikastearena, askoz boteretsuagoa dela, AlphaGo eta halako beste adibide batzuekin.
Ondorioak
Intuizioa ezagutza ez-arrazionala omen da. Goan jokatzen duten adituek intuiziora jotzen dute beren erabakiak eta analisiak azaltzeko garaian. Badakite nola jokatu, baina ez dira gai behar bezala azaltzeko. Ezin esan dezakete zergatik den mugimendu bat beste bat baino hobea.
AlphaGok intuizioaren funtzioa imitatu ahal izan du, ikasteko gaitasunaz baliatuz. Joko-egoera baten aurrean, intuizioz erabakitzen du zein den hurrengo mugimendurik onena, gizaki batek egiten duen antzera. Intuizioz erabakitzen du, halaber, joko-egoera batek irabaztera eramango duenetz. Eta badirudi haren intuizioa gizakienaren gainetik dagoela.
Lee Sedol txapeldun handiak hainbat estrategia erabili zituen AlphaGo menderatzeko asmoz. Partida batean, nahita, gaizki jokatu omen zuen, gaizki jokatzen zuen gizaki baten aurrean AlphaGok zer egin jakingo ez zuelakoan. Huts egin zuen. Partida bakarrean irabazi ahal izan zuen, inork gutxik espero zuen mugimendu bati esker. Ingeniarien arabera, AlphaGok mugimendu hura aurreikusi omen zuen, baina oso probabilitate baxua eman zion. Beraz, Lee Sedolek makina harrituta utzi zuen mugimendu harekin. Behin bakarrik, ordea.
Etorkizunerako erronka da AlphaGok darabiltzan neurona-sareak eta ikasketa-teknikak gure eguneroko arazoak konpontzeko erabiltzea. Ikasteko gaitasuna duten makinek laguntza ikaragarria eman diezagukete industrian, zerbitzuetan, medikuntzan eta baita zientziaren garapenean bertan ere. Intuizioa gakoetako bat izaten da domeinu horietan guztietan, eta badirudi jada badakigula zer egin makinek intuizio hori lor dezaten.
Bibliografia
[1] Intuizioaren teoriak: https://es.wikipedia.org/wiki/Intuici%C3%B3n (azken bisita: 2016/12/28)
[2] Science’s top 10 breakthroughs of 2016: http://www.sciencemag.org/news/2016/12/ai-proteinfolding-our-breakthrough-runners? utm_source=sciencemagazine&utm_medium=twitter&utm_campaign=6319issue-10031 (azken bisita: 2016/12/28).
[3] Deep Blue (chess computer): https://en.wikipedia.org/wiki/Deep_Blue_(chess_computer) (azken bisita: 2017/01/21)
[4] Deep Mind: https://deepmind.com/ (azken bisita: 2017/01/29)
[5] Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
[6] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia

